继前图灵奖获得者Hennessy和Patterson在ISCA 2018提出“A New Golden Age for Computer Architecture”,编译器界大神Chris Lattner在ASPLOS 2021提出了“The Golden Age of Compiler Design”。另一方面,2020年图灵奖授予了编译器“龙书”作者Jeffrey Ullman和Alfred Aho。编译器技术在新的时代背景下似乎又再次焕发了新的活力,成为了业界的热点。
而作为现在最热门的AI计算场景,与编译器技术的结合自然成为了大家不约而同的技术路线。机器学习跨入深度学习时代后,比较老一代的计算框架基本将神经网络建模为计算图,其中算子为节点,张量为边。然后以拓扑序执行,辅以并行优化等。这种范式下,为了达到好的性能,一般需要对网络中的算子深度优化。但是,今天的神经网络结构日益复杂,算子种类也更加繁多。不同的算子参数、输入配置以及算子间的融合,使得需要优化的算子数量组合爆炸,一一硬刚不切实际,而且很多时候也缺乏专家经验和开发时间。为了挖掘极致的性能,同时使得新算子实现更为方便,基于编译技术的方法成为了主流。像TVM,XLA,Glow,nGraph,MindSpore,Jittor,MegEngine,ONNC,Tiramisu等等用到或是基于编译技术的计算框架层出不穷。
在这个方向上,TVM可以说是先驱者。它是一个端到端的深度学习编译器,在平台兼容性和性能等方面都有很好的表现,社区也非常活跃。但它的代码读起来不算太容易理解(编译器的代码好像都不太好读…)。TVM经过几年的快速演进,今天已是一个比较复杂的系统了,里边的功能很多。了解它的手段之一是透过一个最简单的例子来看看其大致处理流程。因此,本文就以官方教程Working with Operators Using Tensor Expressions中的例程vecadd为例。它可以说是TVM的“Hello world”了。
import tvm
import os
n = 1024
A = tvm.te.placeholder((n,), name='A')
B = tvm.te.placeholder((n,), name='B')
C = tvm.te.compute(A.shape, lambda i: A[i] + B[i], name="C")
s = tvm.te.create_schedule(C.op)
# outer, inner = s[C].split(C.op.axis[0], factor=64)
# s[C].parallel(outer)
tgt = tvm.target.Target(target="llvm", host="llvm")
fadd = tvm.build(s, [A, B, C], tgt, name="vecadd")
dev = tvm.device(tgt.kind.name, 0)
a = tvm.nd.array(np.random.uniform(size=n).astype(A.dtype), dev)
b = tvm.nd.array(np.random.uniform(size=n).astype(B.dtype), dev)
c = tvm.nd.array(np.zeros(n, dtype=C.dtype), dev)
fadd(a, b, c)
它做的事就是两个向量的逐元素相加,简单地不能再简单。这个case中不考虑复杂算子,不考虑Relay,不考虑复杂pass,不考虑复杂的schedule,不考虑auto-tuning机制,不考虑graph runtime等。也正是因为简单,分析它的处理流程可以让我们抓住主干,避免陷入复杂的细节。麻省虽小,五脏俱全。它包含了TVM主要流程中的几个关键要素。为了不致一篇显得冗长,整个过程会分多篇介绍。上篇主要涉及计算定义与schedule的创建。我们知道,TVM是基于Halide中algorithm与schedule分离的思想。简单而粗俗地说,前者指定算啥,后者指定怎么算。下面两节就是分别对应计算的定义与schedule的构建。
现实使用当中,我们多数情况下会通过前端的解析器从已有的机器学习模型中导入。如from_onnx.py中的relay.frontend.from_onnx()函数可以从onnx模型导入。但上面例子是单个算子的例子,其中是直接通过TE(Tensor expression)来定义的。
先来看下例子中的计算定义部分:
A = tvm.te.placeholder((n,), name='A')
B = tvm.te.placeholder((n,), name='B')
C = tvm.te.compute(A.shape, lambda i: A[i] + B[i], name="C")
首先通过placeholder()函数创建tensor对象。它会调用_ffi_api.Placeholder()函数从Python调到C++层构建PlaceholderOpNode对象,然后将它的输出tensor返回。主要流程如下:
te.placeholder() # operation.py
return _ffi_api.Placeholder() # placeholder_op.cc
return placeholder()
return PlaceholderOp(...).output(0) # tensor.cc
n = make_object<PlaceholderOpNode>();
...
data_ = std::move(n);
这里的返回类型,或者说上面的A,B类型为tvm.te.tensor.Tensor。C++层对应TensorNode类。TensorNode中关联的Operation对象代表它是通过什么操作计算得到的。对应的,Operation的output()函数可以得到输出tensor。OperationNode的InputTensors()函数(它是个纯虚函数,因此各继承类中会实现,如ComputeOpNode::InputTensors())得到输入tensor。通过这样的方式在逻辑上形成计算图,表示了它们之间的依赖关系。
接下去的compute()函数(实现在operation.py)主要用于根据给定用TE描述的计算构建一个新的tensor。主要流程如下:
compute(shape, fcompute, ...) # operation.py
...
dim_var = [tvm.tir.IterVar((0, s), x, 0) for x, s in zip(arg_names, shape[:out_ndim])] # expr.py
body = fcompute(*[v.var for v in dim_var])
body = convert(body)
op_node = _ffi_api.ComputeOp(name, tag, attrs, dim_var, body)
outputs = tuple(op_node.output(i) for i in range(num))
return outputs[0] if num == 1 else outputs
其中有几个关键步骤:
-
为每个axis创建
tvm.tir.IterVar,它对应循环变量。如上例中就只有一个axis,范围为[0,1024)。对应的C++层的IterVar类定义在var.h文件中。 -
语句
body = fcompute(*[v.var for v in dim_var])最为关键,它调用传入的lambda函数,返回的body类型为tvm.tir.expr.Add(继承关系:->BinaryOpExpr->PrimExprWithOp->ExprOp & PrimExpr)。lambda函数中的A[i]类型为TensorSlice(继承自ObjectGeneric与ExprOp),它代表Tensor的切片。调用下面的函数前会使用TensorSlice::asobject()函数转成ProducerLoad(expr.py和expr.h)对象,它继承自PrimExpr。这里由于是加操作,因此会调用ExprOp的操作符重载函数__add__()。继而调用add()函数(定义在tir/generic.py)。该函数调用到C++层,相应的函数在tir/op/op.cc中通过下面的宏注册:REGISTER_MAKE_BINARY_OP(_OpAdd, add);。实现为:
PrimExpr add(PrimExpr a, PrimExpr b, Span span) {
BinaryOpMatchTypes(a, b, span);
PrimExpr ret = arith::TryConstFold<tir::Add>(a, b);
if (ret.defined()) return ret;
return tir::Add(a, b, span);
}
返回的是tir::Add对象,它对应Python中的Add对象(定义在tir/expr.py)。
-
调用
convert()函数(实现在object_generic.py)对body对象进行转换,将之转化TVM对象。经过转换后body类型为tvm.ir.container.Array。 -
创建C++层的
ComputeOp对象(实现在compute_op.cc)。这个对象中包含ComputeOpNode对象的引用。C++层中ComputeOp(继承自Operaton),对应Python中的对象类型为te.tensor.ComputeOp。Python层中ComputeOp(继承关系:ComputeOp->BaseComputeOp->Operation)。最后返回它的output张量对象,类型为te.tensor.Tensor。
对于上面的例子,这一步后构建的数据结构大体如下:

相关主要类简图:

图中也可以看到,Python与C++层中的对象有对应关系。这便于Python与C++间的调用,这也是TVM的特色之一。一般名为XXX的是相应XXXNode的引用(如ComputeOp与ComputeOpNode)。前者继承自ObjectRef,后者继承自Object。主要的内容是在XXXNode中,XXX中的->操作符被重载了,对它的操作及访问会应用到XXXNode上。
Operation代表操作,如PlaceholderOp和ComputeOp。Tensor代表张量,TensorSlice表示Tensor的切片,如例子中A[i]。PrimExpr主要用于low-level的表示,是所有primitive expression的基类。Primitive expression处理POD数据类型。像这里表示计算的Add和包含了张量的ProducerLoad都是PrimExpr。
稍微复杂些的常见例子是矩阵乘matmul:
k = tvm.te.reduce_axis((0, l), name='k')
A = tvm.te.placeholder((n, l), name='A')
B = tvm.te.placeholder((l, m), name='B')
C = tvm.te.compute((n, m), lambda x, y: tvm.te.sum(A[x, k] * B[k, y], axis=k), name='C')
与上例有所区别的是这里操作数都是二维的,且有reduce轴(计算过程中被约减,因此输入中有,输出中没有的轴)。计算中使用了tvm.te.sum()(实现在python/tvm/tir/op.py)函数来reduce中间轴。函数的定义为:
sum = comm_reducer(lambda x, y: x + y, lambda t: const(0, dtype=t), name="sum") # tir/op.py
tvm.te.sum(A[x, k] * B[k, y], axis=k)
tvm.tir.Reduce(...) # expr.py
return Reduce(...); # expr.cc
生成的数据结构与上面vecadd例子中是类似的,其中Add换成了Reduce。
我们知道,TVM中继承了Halide中algorithm与schedule分离的思想。上面定义好了算什么,接下来就需要确定怎么算了。而这就是schedule要定义的事。首先,需要创建一个schedule:
s = tvm.te.create_schedule(C.op)
其中C.op类型为te.tensor.ComputeOp,返回的变量s类型为te.schedule.Schedule。基本流程如下:
create_schedule(ops) # in schedule.py
return _ffi_api.CreateSchedule(ops)
create_schedule(ops) // schedule.h
return Schedule(ops) // schedule_lang.cc
auto n = make_object<ScheduleNode>();
data_ = n;
n->outputs = ops;
auto g = te::CreateReadGraph(n->outputs); # graph.cc
Array<Operation> post_order = te::PostDFSOrder(n->outputs, g); // graph.cc
for op in post_order:
Stage stage(op);
n->stages.push_back(stage);
n->stage_map.Set(op, stage);
...
这里从Python调用到C++,主要作用是创建Schedule对象。构造函数中几个主要步骤:
- 创建相应的
ScheduleNode对象,将参数中传入的Operation数组设置到成员outputs中。对于上面的例子,Schedule()函数传入的参数中Operation数组的size为1,即ComputeOp。 CreateReadGraph()函数返回ReadGraph对象,它包含了输出依赖的所有操作及对应的张量。它实质是一个Operation到该Operation的输入tensor的数组Array<Tensor>的映射。它的构建过程主要是以输入节点为root,然后通过Operation的InputTensors()函数找出对应的输入tensor。对于上面例子就是:
| Name | Operation | Inputs |
|---|---|---|
| C | ComputeOp | A, B |
| A | PlaceholderOp | N/A |
| B | PlaceholderOp | N/A |
- 调用
PostDFSOrder()函数得到后序的Operation数组。对于该例子便是A, B, C。它表示了各个Operation之间的依赖关系。 - 按照上面得到的后序数组,对每个
Operation创建相应的Stage对象。Schedule对象包含一系列Stage。每个Stage对象对应一个Operation。如上面的例子,就有三个Stage。每个Stage保存了一个循环嵌套(Loop nest)结构的信息,及每个循环的类型(如parallel, vectorized, unrolled)等。
创建了Schedule及对应的Stage对象后,接下来就可以对其进行一些操作。对于该schedule我们可以应用一些调度原语(Schedule primitive)。详细可见官方文档Schedule Primitives in TVM 。下面是一个很常用的split的简单例子:
outer, inner = s[C].split(C.op.axis[0], factor=64)
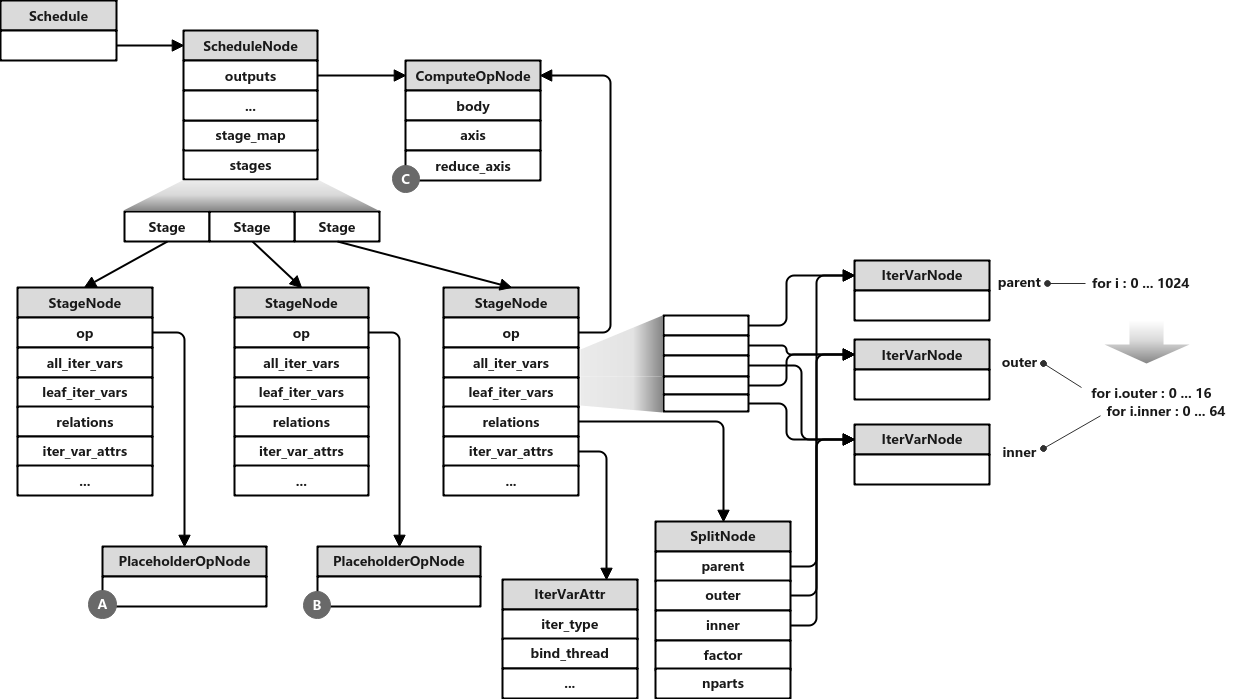
其中,s[C]从schedule中得到对应的Stage对象,其类型为tvm.te.schedule.Stage。split()函数第一个参数和返回值的类型都是tir.expr.IterVar,它对应相应的循环变量(或者说计算轴)。它将操作C的计算中的轴以64为因子进行分割,也就是将一重循环分成二重循环。举例来说,如果原来的循环次数为1024的话,分割后就是外循环16次,内循环64次。其大体流程如下:
Stage::split() // schedule.py
outer, inner = _ffi_api.StageSplitByFactor(...) // schedule_lang.cc
IterVar outer, inner;
Stage::split(parent, factor, &outer, &inner);
SplitHelper(opertor->(), parent, factor, PrimExpr(), p_outer, p_inner);
IterVar outer = IterVar(...);
IterVar inner = IterVar(...);
size_t pos = FindLeafVar(...);
self->relations.push_back(Split(parent, outer, inner, factor, nparts))
auto n = make_object<SplitNode>();
...
data_ = std::move(n);
all_vars.push_back(outer);
all_vars.push_back(inner);
leaf_vars.erase(leaf_vars.begin() + pos);
leaf_vars.insert(leaf_vars.begin() + pos, inner);
leaf_vars.insert(leaf_vars.begin() + pos, outer);
return Array<IterVar>({outer, inner});
return outer, inner;
前面提到,循环结构表示在StageNode类中。它其中主要的几个相关成员:
relations(类型Array<IterVarRelation>):如这里创建的SplitNode继承自IterVarRelationNode,它的几个成员(parent, outer, inner, factor, nparts)描述了split的参数及前后计算轴变量。all_vars(类型为Array<IterVar>):所有的循环变量。包括split过程中所有新老循环变量。leaf_vars(类型为Array<IterVar>):当前生效的循环变量。如在这个例子中只有经过split后的两个循环变量。
这里主要工作在SplitHelper()函数中完成。它的几个主要步骤:
- 原循环变量(用
IterVar表示)按照给定因子经过切分成为两个,分别为外循环和内循环两个。如例子中的话,外循环范围为[0,16),内循环范围范围为[0,64)。 - 通过
FindLeafVar()函数找到父循环变量(即split前)在leaf_vars数组中的位置,一会split后的新循环变量会插在这个位置。 - 创建
Split对象并存入成员relations中。它对应SplitNode类。它保存了使用了何种调度原语(这里是split),以及应用调度原语前后的循环变量间的关系。 - 更新
all_vars与leaf_vars这两个IterVar数组。前者表示所有的(即split前后)循环变量,后者表示split后循环变量,也可以理解为目前生效的循环变量。添加新产生的循环变量到all_vars和leaf_vars中,同时删除leaf_vars中的原有循环变量。
至此,主要数据结构如下:

相关主要类简图:

经过split后,我们可能会想让外循环并行从而提高性能。那就可以用下面的调度原语:
s[C].parallel(outer)
其调用大体流程如下:
Stage::paralle() // schedule.py
_ffi_api.StageParallel(self, var)
Stage::parallel() // schedule_lang.cc
SetAttrIterType(operator->(), var, kParallelized);
UpdateIterVarAttr(self, var, ...);
ObjectPtr<IterVarAttrNode> n = make_object<IterVarAttrNode>();
n->iter_type = kParallelized;
self->iter_var_attrs.Set(var, IterVarAttr(n));
与上面类似,也是从Python层调用到C++层完成实质的工作。因为这个只要设个为循环变量设个属性就行,因此比较简单,函数UpdateIterVarAttr()中主要就是创建相应的IterVarAttrNode对象,根据参数设置其属性,最后保存到StageNode的iter_var_attrs成员中。
再举例说,对于常见的矩阵乘计算,通常会应用tile这个调度原语来做tiling:
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], 32, 32)
它对于两个计算轴做tiling,对每个轴都分成外循环与内循环,然后返回总共4个新的计算轴。其大体流程如下:
Stage::tile() // schedule.py
x_outer, y_outer, x_inner, y_inner = _ffi_api.StageTile(...) // schedule_lange.cc
IterVar x_outer, y_outer, x_inner, y_inner;
stage.tile(x_parent, y_parent, x_factor, y_factor, &x_outer, &y_outer, &x_inner, &y_inner);
split(x_parent, x_factor, p_x_outer, p_x_inner);
split(y_parent, y_factor, p_x_outer, p_y_inner);
...
reorder(Array<IterVar>({*p_x_outer, *p_y_outer, *p_x_inner, *p_y_inner}));
return Array<IterVar>({x_outer, y_outer, x_inner, y_inner);
return x_outer, y_outer, x_inner, y_inner;
可以看到,其实它主要的工作就是在两个维度上做split,然后对切分后的循环变量按指定顺序做reorder。
到这里,上篇就结束了。下一篇会重点聊一下编译部分。
如有侵权请联系:admin#unsafe.sh