阅读: 0
一、前言
人机验证服务是突破传统验证码的人机识别产品,通过对用户的行为数据、设备特征与网络数据构建多维度数据分析,可以对风险设备使用、模拟行为、暴力重放等攻击进行综合判决,解决企业账号、活动、交易等关键业务环节存在的欺诈威胁问题。早期的验证码通常是一串非常简单的形状标准的数字,经过长期发展,形式越来越多样化,现在简单的数字英文验证码已经很容易被机器读取破解,复杂的验证码设计得愈发反人类。不过得益于机器学习,尤其是深度学习的进步,很多学者和技术大牛都这方面有了一些研究成果,本文将对已有的一些人机验证绕过技术进行总结。
二、亚马逊验证码识别
亚马逊网站验证码全部由英文字母组成,每个字母的形式也是多样的,通过现有库Tesseract-OCR技术识别效率比较低。有研究者采用向量空间技术进行训练识别,识别率可达到95%[1]。
如下图所示,作者手动收集了大量的亚马逊网站验证码图片,先将格式转换为小容量的gif格式,然后将并将原图片中的黑色像素拷贝到新的相同尺寸的白色图片上,进行二值化处理,从而得到较低像素的图片集。

图2.1 低像素验证码图片集
接着将这些图片中的字母进行纵向切割,切割规则为:依次纵向检索每个像素点,在横向固定的前提下:若遇到像素值为0,则表示为黑色的字母;若整个纵向都没遇到黑色,则表示是分割点。然后我们可以得到一样图片的横向的所有分割点的坐标,最后分割即可将分割出的字母图片放到不同的训练库中,每个字母都多张图片,训练库中的数量越多识别率越高。

图2.2 被切割的字母图片
当拿到一张新的单字母图片,就可以去数据集中匹配每个图片,计算出相似度最高的训练库,就可以识别这张字母图片,最后依次识别的结果进行组合,拼成最终的验证码。其中用到的匹配算法为AI与向量空间算法,即计算原图片的所有像素点与训练库中的每张图片的所有像素点的余弦值,余弦值越大,相似度越高。经测试,每个字母图片的识别时间大约为1s左右,一张亚马逊验证码的识别时间大约为5-6s,这个时间是可以接受的。
三、12306验证码识别
每年春节,12306网站的验证码都令人头疼。因此有研究者使用深度学习中图像识别的方法破解12306验证码[2],其识别率可以提高到92%。
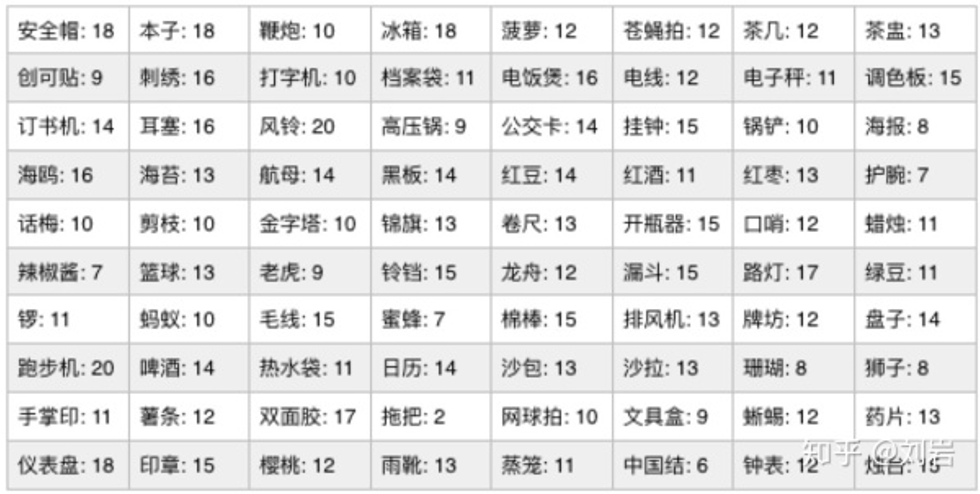
12306的验证码是从图片中找到文字描述对应的物体。经过统计了1000个图片样本后,作者发现中其实所有的图片只有80个类,具体的类别和对应统计个数如图3.1所示。

图3.1 12306验证码类别
因此,12306的验证码的识别工作就可以巧妙地转换成经典的多分类问题。更幸运的是, Kaggle上提供了一份开源的12306已标注图片数据集[3],这也就省去了人工标注数据的繁琐工作。
接下来就是分类网络结构的构建和训练过程。作者使用Keras人工神经网络库中自带的经典卷积网络VGG-16在ImageNet-2012(1000类)上的分类网络,由于输出节点数不一样,他只取了VGG-16的表示层。训练模型时采用的优化策略是Adagrad算法,损失函数选择多类别交叉熵,然后通过加入Dropout来缓解拟合的发生,在一定程度上达到正则化。核心代码如图3.2所示。

图3.2 12306验证码识别代码
目前,针对12306验证码破解的大部分方法都是利用深度学习技术对验证码图片进行识别的,其准确率大都超过90%。这些识别主要用于12306官网模拟登陆,并进行相应的刷票、抢票等操作。
四、谷歌验证系统破解
reCaptcha 项目出自卡内基梅隆大学,于 2009 年 9 月被谷歌收购用作验证系统。自推出以来,谷歌的 reCaptcha 验证系统就被频繁破解[5],因此谷歌不得不一次又一次地迭代升级。
reCAPTCHA v1版本是将从书本上扫描下来的,无法被 OCR 准确识别的文字显示在验证码问题中,从而判断访问者到底是程序还是人类。该版本被 Bursztein 等人破解,他们使用与本文第2节提到的亚马逊验证码识别类似,都是基于机器学习的系统对文本进行分割和识别,准确率达 98%。
为了反破解,谷歌引入了基于音频和图像的 reCAPTCHA v2版本,使用了一些高级的分析工具来判断一个用户到底是人还是机器人。他们使用了多种元素,包括 cookie、解题的速度、鼠标的移动以及解题的成功率。但尽管如此,美国马里兰大学四位研究人员开发的 unCapture实现了 85% 的 ReCaptcha 对抗率。后来,谷歌发布了新的 ReCaptcha开始使用短语语音进行验证,这些改进最开始成功地防御了第一版 unCaptcha 的攻击,但由于 ReCaptcha 添加了语音形式的验证码识别,破解 ReCaptcha 却变得比以前更加容易。破解者表示,“因为我们只需要调用一个免费的语音识别 API,对所有验证码的识别准确率就能达到 90% 左右。”
前两个版本的 reCAPTCHA 有可利用的文本、图像或音频,可以将其用作训练神经网络的输入。reCAPTCHA v3版本移除了所有用户界面,没有拆开乱码文本或街道标志,甚至也没有勾选“我不是机器人”的方框。它会分析一系列信号,使用机器学习技术返回一个 0 到 1 之间的风险评估分数,这种打分完全是在后台进行的,根本没有人类交互,破解难度更大。而再强的系统也会有漏洞,来自加拿大和法国的研究者另辟蹊径,使用强化学习的方法“破解”了这个最新的验证系统,测试准确率达到 97.4%。但是实际上这项强化学习技术并非破解eCAPTCHA v3 中不可见的分数,而是针对 reCAPTCHA v2 中首次引入的鼠标移动进行分析,用机器学习的方法欺骗二级系统(即旧版的“我不是机器人””打勾操作)以绕过 reCAPTCHA v3,它并没有真正攻破 reCAPTCHA v3。
五、滑动验证破解
滑动验证码本质上并不是验证码,它只是一种网页数据加密的方式,其原理是基于采集用户的操作数据,环境数据等数据,通过一个加密算法得到字符串,然后提交到服务器分析,服务器有一个判定标准,对数据进行简单的分析就知道是不是人工在操作[6]。
目前,在网络上已经存在多种关于滑动验证破解的方法。根据破解的方法和思路,主要有两种手段:第一种方法为通过直接利用Selenium的方式,调用浏览器或Phantomjs,来模拟鼠标移动轨迹过程,实现破解;第二种方法为记录页面加载过程中的网络参数,通过进一步分析参数的JS计算过程,然后模拟轨迹及其计算过程获取前端请求参数,从而能够正确解锁滑动界面。
在这两种方案中,第一种方法相对而言实现难度较低,一旦破解后,假如目标网站不主动升级轨迹的智能检测程度,则基本可长期使用,主要的缺点是访问效率较低;第二种方法实现起来技术难度高,在经过破解后访问效率明显提高,但主要缺点在于受JS代码频繁升级的影响很大。即使是JS加密难度顶峰的淘宝UA算法,也常常被人解密出来,但是算法每过一个月到半个月就全部更换一次,可能刚被解密,加密JS又被改到面目全非。
六、总结
当今互联网中,大量诸如垃圾注册、刷库撞库、薅羊毛等严重影响企业正常业务运作的恶意风险背后都离不开机器自动化脚本。绕开某一个网站的人机验证,重点在于让机器觉着你是人,而不是它的同类,但是机器觉着你是不是机器的重点在于设计这个机器的人所设置的一些检验手段。人机验证服务可以在保障用户体验的同时有效拦截机器风险,提供安全可靠的业务环境。对绕过技术的研究可以有效对恶意访问行为进行约束,对于反爬虫的信息保护也有极大的战略意义。
参考文献:
[1] 亚马逊验证码智能识别技术详解,https://zhuanlan.zhihu.com/p/46603425
[2] 实例解析:12306验证码破解,https://zhuanlan.zhihu.com/p/53329216
[3] Kaggle 12306验证码数据集,https://www.kaggle.com/libowei/12306-captcha-image
[4] 12306验证码识别,https://github.com/senliuy/12306_crack
[5] Google’s reCAPTCHA test has been tricked by artificial intelligence. https://www.wired.co.uk/article/google-captcha-recaptcha
[6] 淘宝在找回密码时需要向右滑动验证,原理是?https://www.zhihu.com/question/35538123/answer/63302379
作者:周鸿屹 王焕然