2020-11-29 09:00:00 Author: arthurchiao.github.io(查看原文) 阅读量:207 收藏
Published at 2020-11-29 | Last Update 2020-11-29
译者序
本文翻译自 2019 年 Daniel Borkmann 和 Martynas Pumputis 在 Linux Plumbers Conference 的一篇分享: Making the Kubernetes Service Abstraction Scale using eBPF 。 翻译时对大家耳熟能详或已显陈旧的内容(K8s 介绍、Cilium 1.6 之前的版本对 Service 实现等)略有删减,如有需要请查阅原 PDF。
实际上,一年之后 Daniel 和 Martynas 又在 LPC 做了一次分享,内容是本文的延续: 基于 BPF/XDP 实现 K8s Service 负载均衡 (LPC, 2020)。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
- 译者序
- 1 K8s Service 类型及默认基于 kube-proxy 的实现
- 2 用 Cilium/BPF 替换 kube-proxy
- 3 相关的 Cilium/BPF 优化
- 4 Cilium 上手:用 kubeadm 搭建体验环境
以下是译文。
K8s 当前重度依赖 iptables 来实现 Service 的抽象。 对于每个 Service 及其 backend pods,在 K8s 里会生成很多 iptables 规则。 例如 5K 个 Service 时,iptables 规则将达到 25K 条,导致的后果:
- 较高、并且不可预测的转发延迟(packet latency),因为每个包都要遍历这些规则 ,直到匹配到某条规则;
- 更新规则的操作非常慢:无法单独更新某条 iptables 规则,只能将全部规则读出来 ,更新整个集合,再将新的规则集合下发到宿主机。在动态环境中这一问题尤其明显,因为每 小时可能都有几千次的 backend pods 创建和销毁。
- 可靠性问题:iptables 依赖 Netfilter 和系统的连接跟踪模块(conntrack),在 大流量场景下会出现一些竞争问题(race conditions);UDP 场景尤其明显,会导 致丢包、应用的负载升高等问题。
本文将介绍如何基于 Cilium/BPF 来解决这些问题,实现 K8s Service 的大规模扩展。
K8s 提供了 Service 抽象,可以将多个 backend pods 组织为一个逻辑单元(logical unit)。K8s 会为这个逻辑单元分配 虚拟 IP 地址(VIP),客户端通过该 VIP 就 能访问到这些 pods 提供的服务。
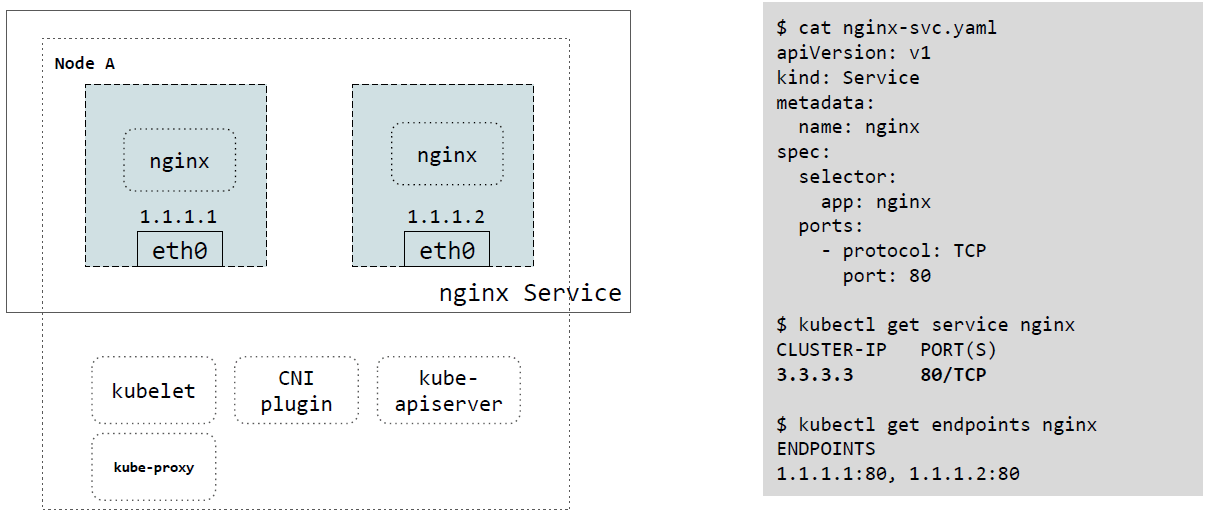
下图是一个具体的例子,
-
右边的 yaml 定义了一个名为
nginx的 Service,它在 TCP 80 端口提供服务;- 创建:
kubectl -f nginx-svc.yaml
- 创建:
-
K8s 会给每个 Service 分配一个虚拟 IP,这里给
nginx分的是3.3.3.3;- 查看:
kubectl get service nginx
- 查看:
-
左边是
nginxService 的两个 backend pods(在 K8s 对应两个 endpoint),这里 位于同一台节点,每个 Pod 有独立的 IP 地址;- 查看:
kubectl get endpoints nginx
- 查看:
上面看到的是所谓的 ClusterIP 类型的 Service。实际上,在 K8s 里有几种不同类型
的 Service:
- ClusterIP
- NodePort
- LoadBalancer
- ExternalName
本文将主要关注前两种类型。
K8s 里实现 Service 的组件是 kube-proxy,实现的主要功能就是将访问 VIP 的请 求转发(及负载均衡)到相应的后端 pods。前面提到的那些 iptables 规则就是它创建 和管理的。
另外,kube-proxy 是 K8s 的可选组件,如果不需要 Service 功能,可以不启用它。
1.1 ClusterIP Service
这是 K8s 的默认 Service 类型,使得宿主机或 pod 可以通过 VIP 访问一个 Service。
- Virtual IP to any endpoint (pod)
- Only in-cluster access
kube-proxy 是通过如下的 iptables 规则来实现这个功能的:
-t nat -A {PREROUTING, OUTPUT} -m conntrack --ctstate NEW -j KUBE-SERVICES
# 宿主机访问 nginx Service 的流量,同时满足 4 个条件:
# 1. src_ip 不是 Pod 网段
# 2. dst_ip=3.3.3.3/32 (ClusterIP)
# 3. proto=TCP
# 4. dport=80
# 如果匹配成功,直接跳转到 KUBE-MARK-MASQ;否则,继续匹配下面一条(iptables 是链式规则,高优先级在前)
# 跳转到 KUBE-MARK-MASQ 是为了保证这些包出宿主机时,src_ip 用的是宿主机 IP。
-A KUBE-SERVICES ! -s 1.1.0.0/16 -d 3.3.3.3/32 -p tcp -m tcp --dport 80 -j KUBE-MARK-MASQ
# Pod 访问 nginx Service 的流量:同时满足 4 个条件:
# 1. 没有匹配到前一条的,(说明 src_ip 是 Pod 网段)
# 2. dst_ip=3.3.3.3/32 (ClusterIP)
# 3. proto=TCP
# 4. dport=80
-A KUBE-SERVICES -d 3.3.3.3/32 -p tcp -m tcp --dport 80 -j KUBE-SVC-NGINX
# 以 50% 的概率跳转到 KUBE-SEP-NGINX1
-A KUBE-SVC-NGINX -m statistic --mode random --probability 0.50 -j KUBE-SEP-NGINX1
# 如果没有命中上面一条,则以 100% 的概率跳转到 KUBE-SEP-NGINX2
-A KUBE-SVC-NGINX -j KUBE-SEP-NGINX2
# 如果 src_ip=1.1.1.1/32,说明是 Service->client 流量,则
# 需要做 SNAT(MASQ 是动态版的 SNAT),替换 src_ip -> svc_ip,这样客户端收到包时,
# 看到就是从 svc_ip 回的包,跟它期望的是一致的。
-A KUBE-SEP-NGINX1 -s 1.1.1.1/32 -j KUBE-MARK-MASQ
# 如果没有命令上面一条,说明 src_ip != 1.1.1.1/32,则说明是 client-> Service 流量,
# 需要做 DNAT,将 svc_ip -> pod1_ip,
-A KUBE-SEP-NGINX1 -p tcp -m tcp -j DNAT --to-destination 1.1.1.1:80
# 同理,见上面两条的注释
-A KUBE-SEP-NGINX2 -s 1.1.1.2/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-NGINX2 -p tcp -m tcp -j DNAT --to-destination 1.1.1.2:80
- Service 既要能被宿主机访问,又要能被 pod 访问(二者位于不同的 netns),
因此需要在
PREROUTING和OUTPUT两个 hook 点拦截请求,然后跳转到自定义的KUBE-SERVICESchain; KUBE-SERVICESchain 执行真正的 Service 匹配,依据协议类型、目的 IP 和目的端口号。当匹配到某个 Service 后,就会跳转到专门针对这个 Service 创 建的 chain,命名格式为KUBE-SVC-<Service>。KUBE-SVC-<Service>chain 根据概率选择某个后端 pod 然后将请 求转发过去。这其实是一种穷人的负载均衡器 —— 基于 iptables。选中某个 pod 后,会跳转到这个 pod 相关的一条 iptables chainKUBE-SEP-<POD>。KUBE-SEP-<POD>chain 会执行 DNAT,将 VIP 换成 PodIP。
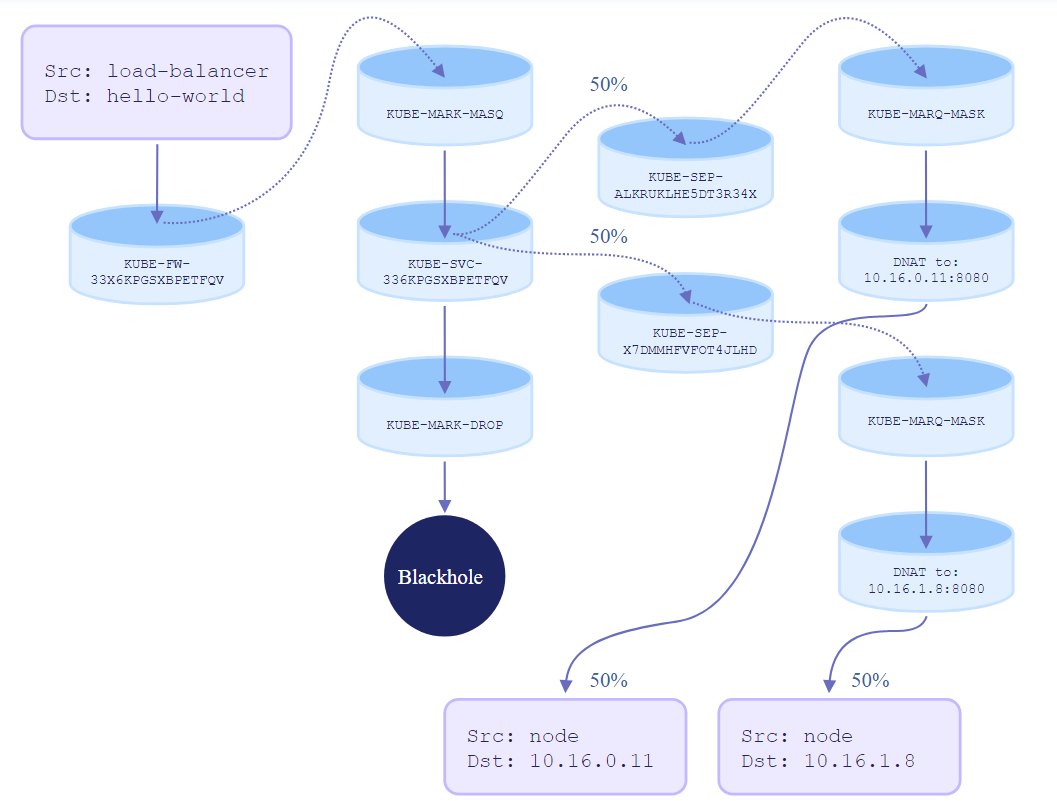
译注:以上解释并不是非常详细和直观,因为这不是本文重点。想更深入地理解基于 iptables 的实现,可参考网上其他一些文章,例如下面这张图所出自的博客 Kubernetes Networking Demystified: A Brief Guide,
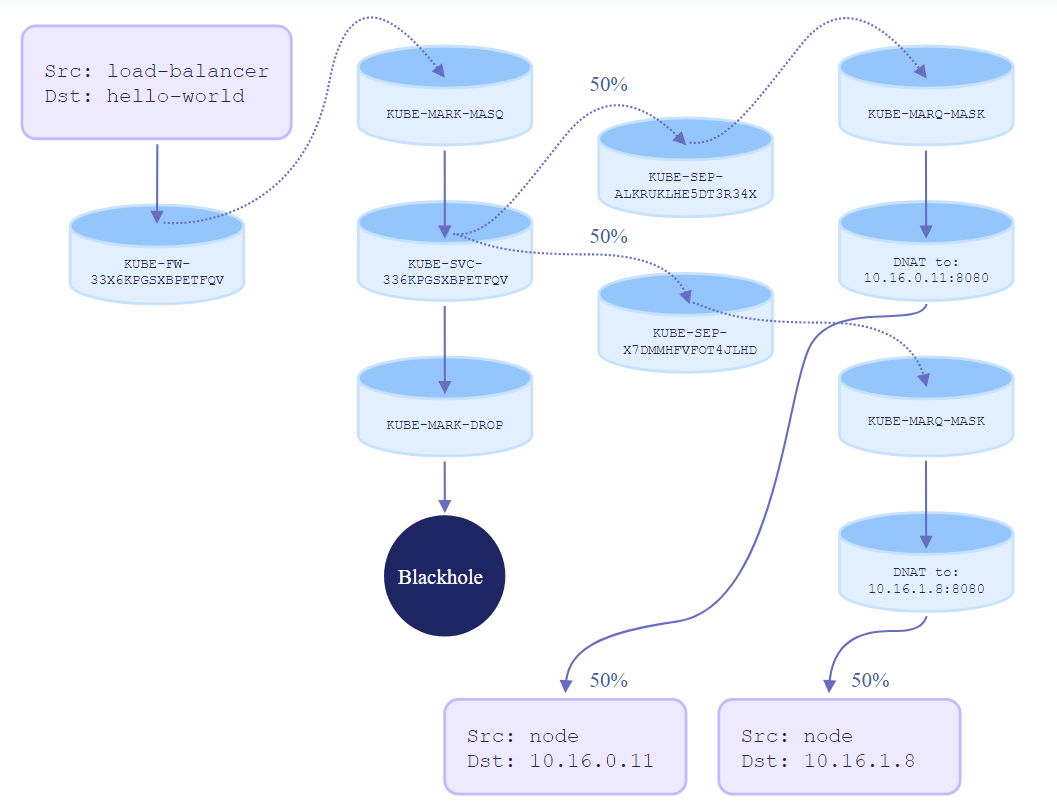
1.2 NodePort Service
这种类型的 Service 也能被宿主机和 pod 访问,但与 ClusterIP 不同的是,它还能被 集群外的服务访问。
- External node IP + port in NodePort range to any endpoint (pod), e.g. 10.0.0.1:31000
- Enables access from outside
实现上,kube-apiserver 会从预留的端口范围内分配一个端口给 Service,然后 每个宿主机上的 kube-proxy 都会创建以下规则:
-t nat -A {PREROUTING, OUTPUT} -m conntrack --ctstate NEW -j KUBE-SERVICES
-A KUBE-SERVICES ! -s 1.1.0.0/16 -d 3.3.3.3/32 -p tcp -m tcp --dport 80 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 3.3.3.3/32 -p tcp -m tcp --dport 80 -j KUBE-SVC-NGINX
# 如果前面两条都没匹配到(说明不是 ClusterIP service 流量),并且 dst 是 LOCAL,跳转到 KUBE-NODEPORTS
-A KUBE-SERVICES -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-NODEPORTS -p tcp -m tcp --dport 31000 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m tcp --dport 31000 -j KUBE-SVC-NGINX
-A KUBE-SVC-NGINX -m statistic --mode random --probability 0.50 -j KUBE-SEP-NGINX1
-A KUBE-SVC-NGINX -j KUBE-SEP-NGINX2
- 前面几步和 ClusterIP Service 一样;如果没匹配到 ClusterIP 规则,则跳转到
KUBE-NODEPORTSchain。 KUBE-NODEPORTSchain 里做 Service 匹配,但这次只匹配协议类型和目的端口号。- 匹配成功后,转到对应的
KUBE-SVC-<Service>chain,后面的过程跟 ClusterIP 是一样的。
1.3 小结
以上可以看到,每个 Service 会对应多条 iptables 规则。
Service 数量不断增长时,iptables 规则的数量增长会更快。而且,每个包都需要 遍历这些规则,直到最终匹配到一条相应的规则。如果不幸匹配到最后一条规则才命中, 那相比其他流量,这些包就会有很高的延迟。
有了这些背景知识,我们来看如何用 BPF/Cilium 来替换掉 kube-proxy,也可以说是 重新实现 kube-proxy 的逻辑。
我们从 Cilium 早起版本开始,已经逐步用 BPF 实现 Service 功能,但其中仍然有些 地方需要用到 iptables。在这一时期,每台 node 上会同时运行 cilium-agent 和 kube-proxy。
到了 Cilium 1.6,我们已经能完全基于 BPF 实现,不再依赖 iptables,也不再需要 kube-proxy。
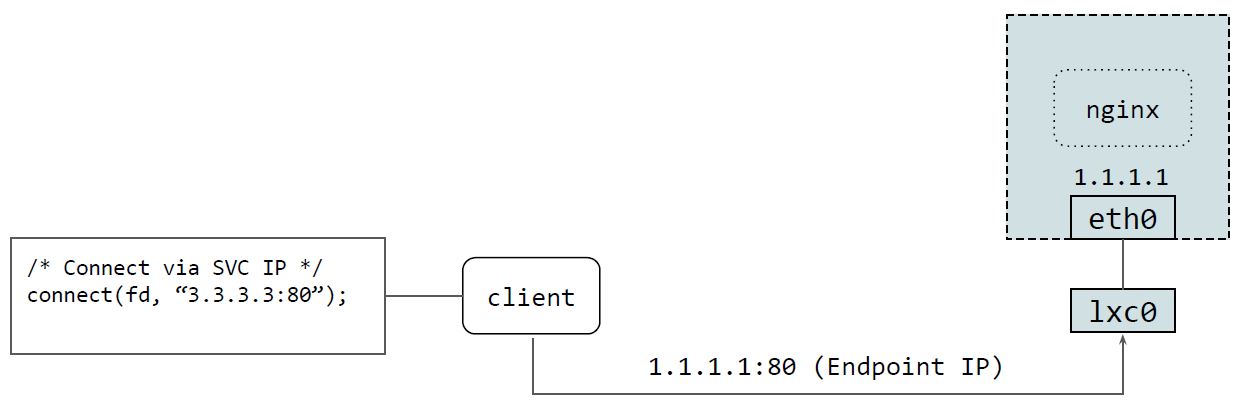
这里有一些实现上的考虑:相比于在 TC ingress 层做 Service 转换,我们优先利用 cgroupv2 hooks,在 socket BPF 层直接做这种转换(需要高版本内核支持,如果不支 持则 fallback 回 TC ingress 方式)。
2.1 ClusterIP Service
对于 ClusterIP,我们在 BPF 里拦截 socket 的 connect 和 send 系统调用;
这些 BPF 执行时,协议层还没开始执行(这些系统调用 handlers)。
- Attach on the cgroupv2 root mount
BPF_PROG_TYPE_CGROUP_SOCK_ADDR BPF_CGROUP_INET{4,6}_CONNECT- TCP, connected UDP
TCP & connected UDP
对于 TCP 和 connected UDP 场景,执行的是下面一段逻辑,
int sock4_xlate(struct bpf_sock_addr *ctx) {
struct lb4_svc_key key = { .dip = ctx->user_ip4, .dport = ctx->user_port };
svc = lb4_lookup_svc(&key)
if (svc) {
ctx->user_ip4 = svc->endpoint_addr;
ctx->user_port = svc->endpoint_port;
}
return 1;
}
所做的事情:在 BPF map 中查找 Service,然后做地址转换。但这里的重点是(相比于 TC ingress BPF 实现):
- 不经过连接跟踪(conntrack)模块,也不需要修改包头(实际上这时候还没有包 ),也不再 mangle 包。这也意味着,不需要重新计算包的 checksum。
- 对于 TCP 和 connected UDP,负载均衡的开销是一次性的,只需要在 socket 建立 时做一次转换,后面都不需要了,不存在包级别的转换。
- 这种方式是对宿主机 netns 上的 socket 和 pod netns 内的 socket 都是适用的。
某些 UDP 应用:存在的问题及解决方式
但这种方式对某些 UDP 应用是不适用的,因为这些 UDP 应用会检查包的源地址,以及
会调用 recvmsg 系统调用。
针对这个问题,我们引入了新的 BPF attach 类型:
BPF_CGROUP_UDP4_RECVMSGBPF_CGROUP_UDP6_RECVMSG
另外还引入了用于 NAT 的 UDP map、rev-NAT map:
BPF rev NAT map
Cookie EndpointIP Port => ServiceID IP Port
-----------------------------------------------------
42 1.1.1.1 80 => 1 3.3.3.30 80
-
通过
bpf_get_socket_cookie()创建 socket cookie。除了 Service 访问方式,还会有一些客户端通过 PodIP 直连的方式建立 UDP 连接, cookie 就是为了防止对这些类型的流量做 rev-NAT。
-
在
connect(2)和sendmsg(2)时更新 map。 -
在
recvmsg(2)时做 rev-NAT。
2.2 NodePort Service
NodePort 会更复杂一些,我们先从最简单的场景看起。
2.2.1 后端 pod 在本节点
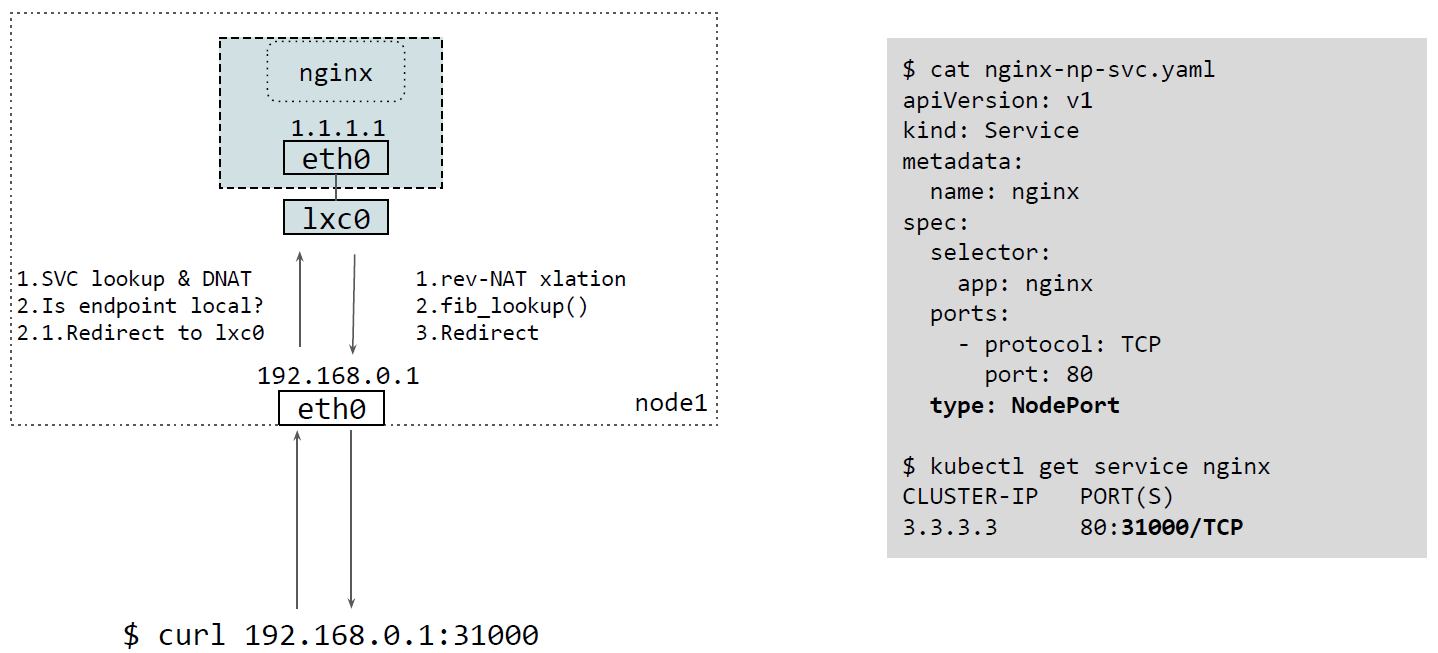
后端 pod 在本节点时,只需要在宿主机的网络设备上 attach 一段 tc ingress bpf 程序,这段程序做的事情:
- Service 查找
- DNAT
- redirect 到容器的 lxc0。
对于应答包,lxc0 负责 rev-NAT,FIB 查找(因为我们需要设置 L2 地址,否则会被 drop), 然后将其 redirect 回客户端。
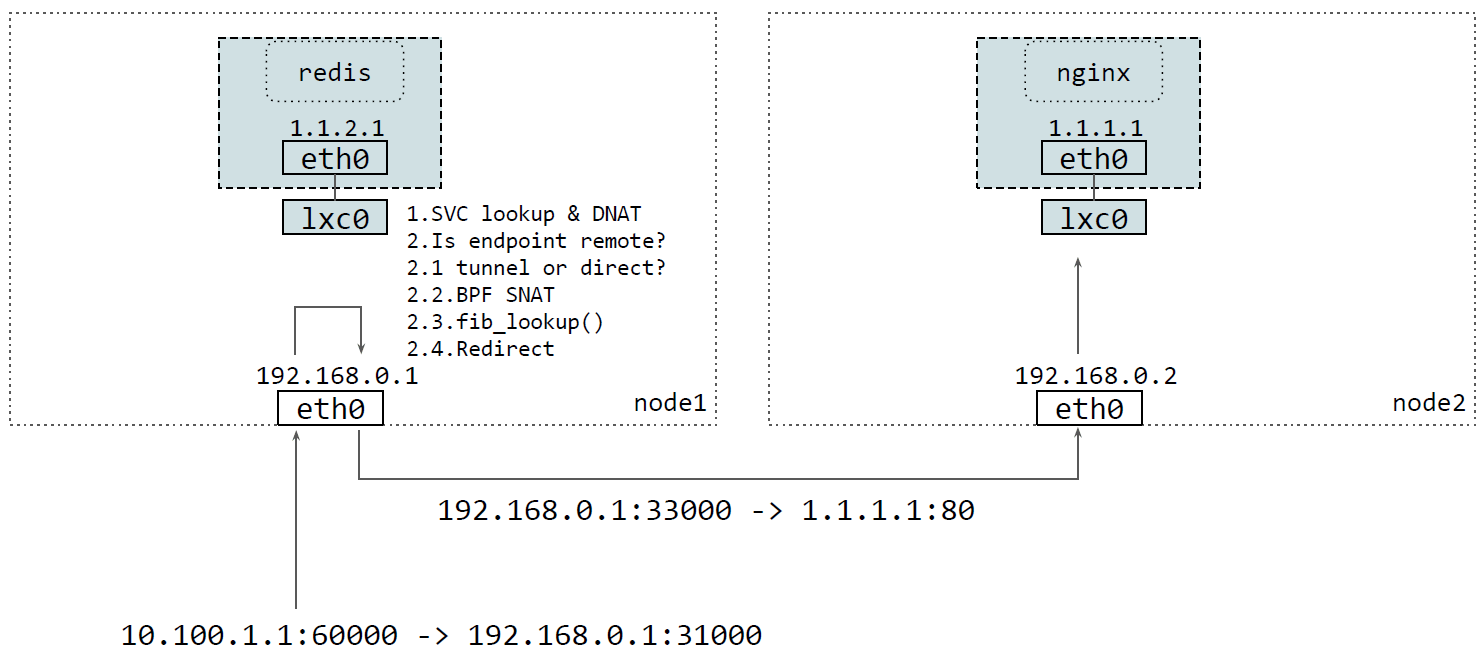
2.2.2 后端 pod 在其他节点
后端 pod 在其他节点时,会复杂一些,因为要转发到其他节点。这种情况下,需要在 BPF 做 SNAT,否则 pod 会直接回包给客户端,而由于不同 node 之间没有做连接跟踪( conntrack)同步,因此直接回给客户端的包出 pod 后就会被 drop 掉。
所以需要在当前节点做一次 SNAT(src_ip 从原来的 ClientIP 替换为 NodeIP),让回包也经过
当前节点,然后在这里再做 rev-SNAT(dst_ip 从原来的 NodeIP 替换为 ClientIP)。
具体来说,在 TC ingress 插入一段 BPF 代码,然后依次执行:Service 查找、DNAT、 选择合适的 egress interface、SNAT、FIB lookup,最后发送给相应的 node,
反向路径是类似的,也是回到这个 node,TC ingress BPF 先执行 rev-SNAT,然后 rev-DNAT,FIB lookup,最后再发送回客户端,
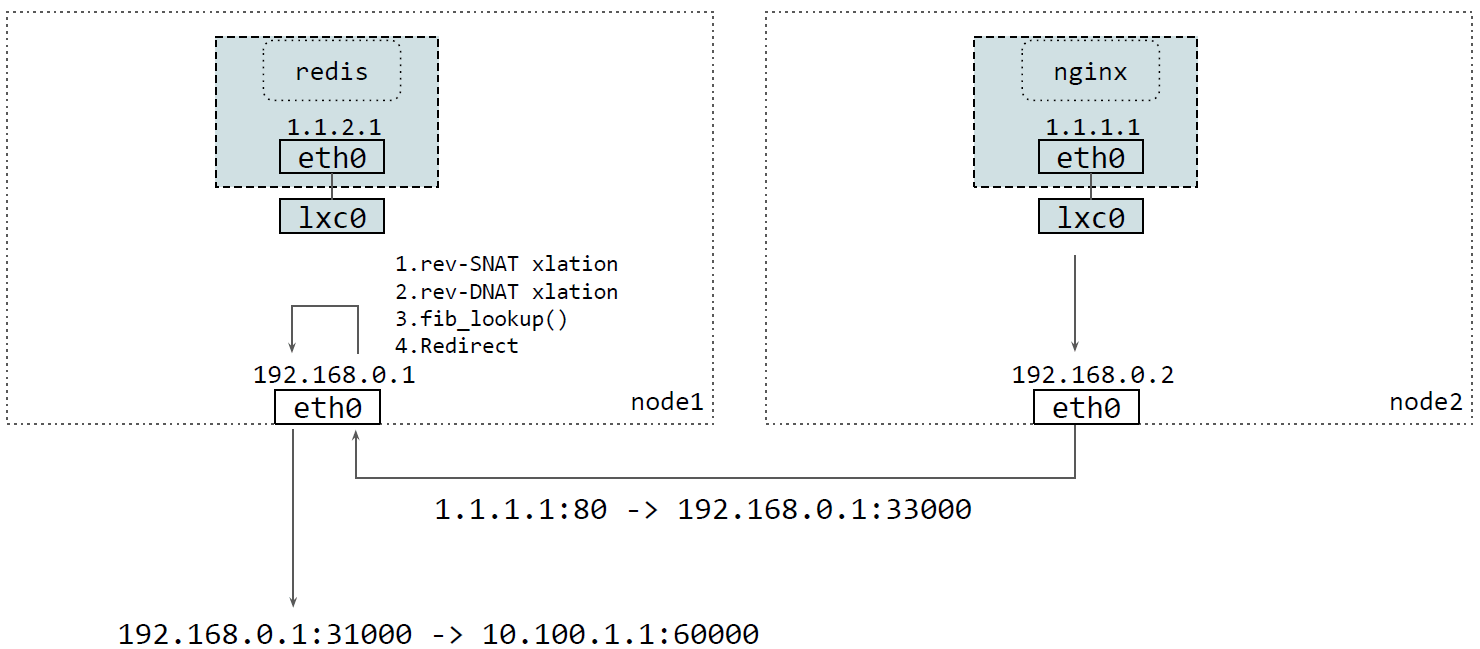
现在跨宿主机转发是 SNAT 模式,但将来我们打算支持 DSR 模式(译注,Cilium 1.8+ 已经支持了)。DSR 的好处是 backend pods 直接将包回给客户端,回包不再经过当前 节点转发。
另外,现在 Service 的处理是在 TC ingress 做的,这些逻辑其实也能够在 XDP 层实现, 那将会是另一件激动人心的事情(译注,Cilium 1.8+ 已经支持了,性能大幅提升)。
SNAT
当前基于 BPF 的 SNAT 实现中,用一个 LRU BPF map 存放 Service 和 backend pods 的映 射信息。
需要说明的是,SNAT 除了替换 src_ip,还可能会替换 src_port:不同客户端的
src_port 可能是相同的,如果只替换 src_ip,不同客户端的应答包在反向转换时就会失
败。因此这种情况下需要做 src_port 转换。现在的做法是,先进行哈希,如果哈希失败,
就调用 prandom() 随机选择一个端口。
此外,我们还需要跟踪宿主机上的流(local flows)信息,因此在 Cilium 里基于 BPF 实现了一个连接跟踪器(connection tracker),它会监听宿主机的主物理网络设备( main physical device);我们也会对宿主机上的应用执行 NAT,pod 流量 NAT 之后使用的 是宿主机的 src_port,而宿主机上的应用使用的也是同一个 src_port 空间,它们可能会 有冲突,因此需要在这里处理。
这就是 NodePort Service 类型的流量到达一台节点后,我们在 BPF 所做的事情。
2.2.3 Client pods 和 backend pods 在同一节点
另外一种情况是:本机上的 pod 访问某个 NodePort Service,而且 backend pods 也在本机。
这种情况下,流量会从 loopback 口转发到 backend pods,中间会经历路由和转发过程, 整个过程对应用是透明的 —— 我们可以在应用无感知的情况下,修改二者之间的通信方式, 只要流量能被双方正确地接受就行。因此,我们在这里使用了 ClusterIP,并对其进 行了一点扩展,只要连接的 Service 是 loopback 地址或者其他 local 地址,它都能正 确地转发到本机 pods。
另外,比较好的一点是,这种实现方式是基于 cgroups 的,因此独立于 netns。这意味着 我们不需要进入到每个 pod 的 netns 来做这种转换。
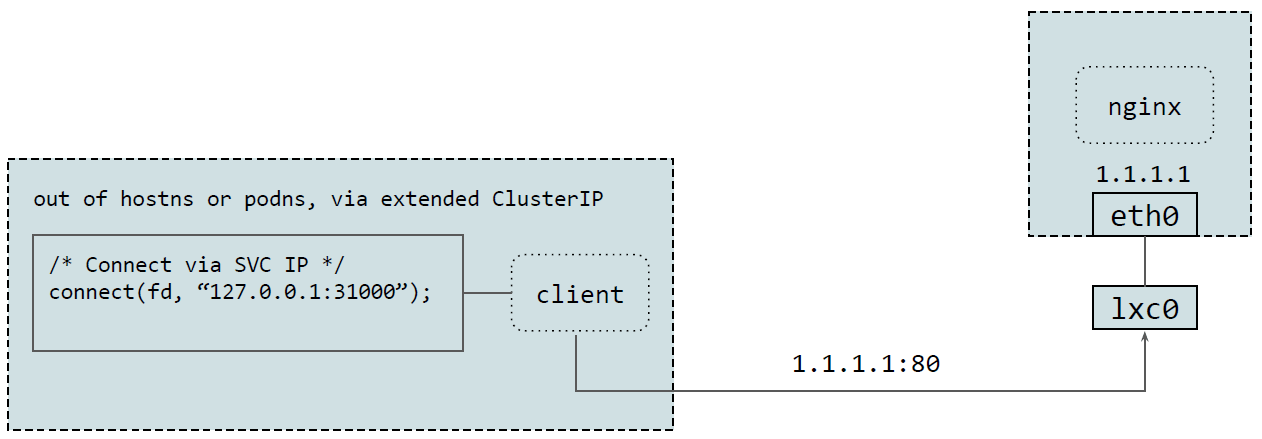
2.3 Service 规则的规模及请求延迟对比
有了以上功能,基本上就可以避免 kube-proxy 那样 per-service 的 iptables 规则了, 每个节点上只留下了少数几条由 Kubernetes 自己创建的 iptables 规则:
$ iptables-save | grep ‘\-A KUBE’ | wc -l:
- With kube-proxy: 25401
- With BPF: 4
在将来,我们有希望连这几条规则也不需要,完全绕开 Netfilter 框架(译注:新版本已经做到了)。
此外,我们做了一些初步的基准测试,如下图所示,
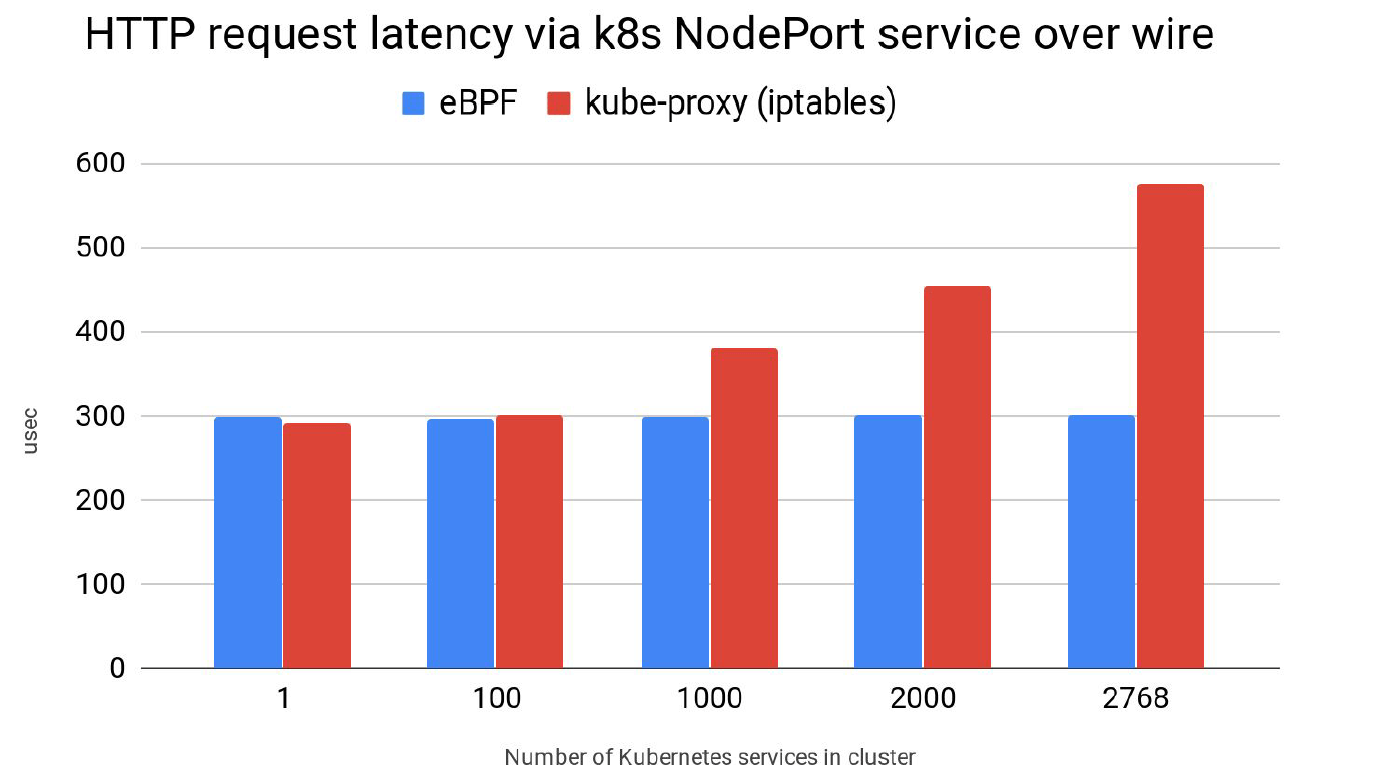
可以看到,随着 Service 数量从 1 增加到 2000+,kube-proxy/iptables 的请求延 迟增加了将近一倍,而 Cilium/eBPF 的延迟几乎没有任何增加。
接下来介绍一些我们在实现 Service 过程中的优化工作,以及一些未来可能会做的事情。
3.1 BPF UDP recvmsg() hook
实现 socket 层 UDP Service 转换时,我们发现如果只对 UDP sendmsg 做 hook
,会导致 DNS 等应用无法正常工作,会出现下面这种错误:
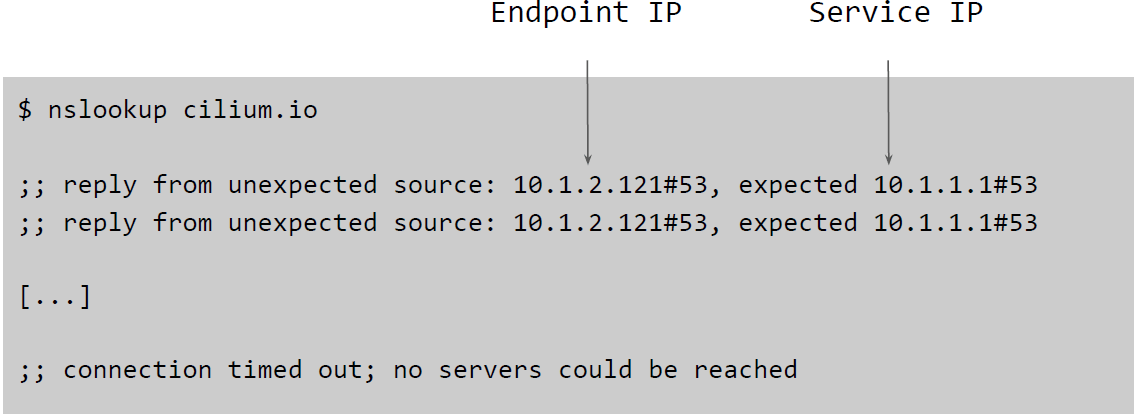
深入分析发现,nslookup 及其他一些工具会检查 connect() 时用的 IP 地址和
recvmsg() 读到的 reply message 里的 IP 地址是否一致。如果不一致,就会
报上面的错误。
原因清楚之后,解决就比较简单了:我们引入了一个做反向映射的 BPF hook,对
recvmsg() 做额外处理,这个问题就解决了:
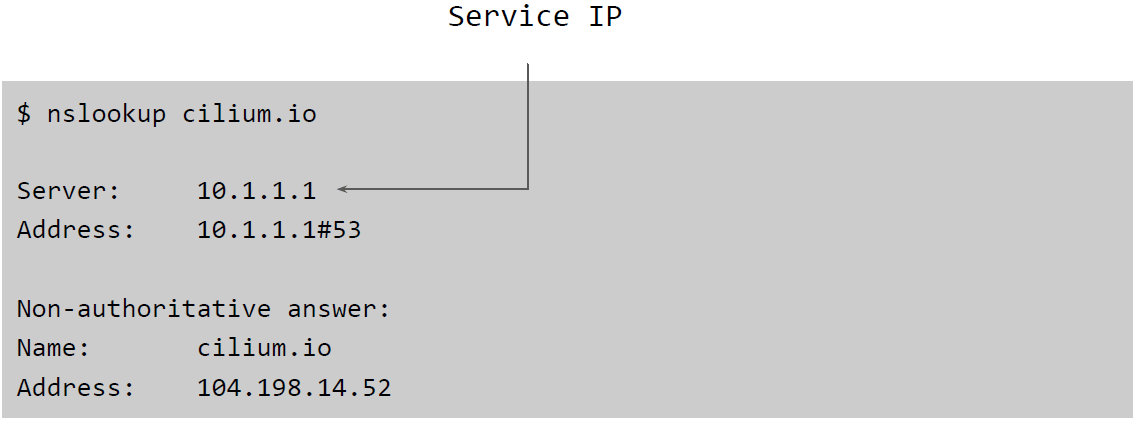
983695fa6765 bpf: fix unconnected udp hooks。
这个 patch 能在不重写包(without packet rewrite)的前提下,会对 BPF ClusterIP 做反向映射(reverse mapping)。
3.2 全局唯一 socket cookie
BPF ClusterIP Service 为 UDP 维护了一个 LRU 反向映射表(reverse mapping table)。
Socket cookie 是这个映射表的 key 的一部分,但这个 cookie 只在每个 netns 内唯一, 其背后的实现比较简单:每次调用 BPF cookie helper,它都会增加计数器,然后将 cookie 存储到 socket。因此不同 netns 内分配出来的 cookie 值可能会一样,导致冲突。
为解决这个问题,我们将 cookie generator 改成了全局的,见下面的 commit。
cd48bdda4fb8 sock: make cookie generation global instead of per netns。
3.3 维护邻居表
Cilium agent 从 K8s apiserver 收到 Service 事件时, 会将 backend entry 更新到 datapath 中的 Service backend 列表。
前面已经看到,当 Service 是 NodePort 类型并且 backend 是 remote 时,需要转发到其
他节点(TC ingress BPF redirect())。
我们发现在某些直接路由(direct routing)的场景下,会出现 fib 查找失败的问题
(fib_lookup()),原因是系统中没有对应 backend 的 neighbor entry(IP->MAC 映射
信息),并且接下来不会主动做 ARP 探测(ARP probe)。
Tunneling 模式下这个问题可以忽略,因为本来发送端的 BPF 程 序就会将 src/dst mac 清零,另一台节点对收到的包做处理时, VxLAN 设备上的另一段 BPF 程序会能够正确的转发这个包,因此这种方式更像是 L3 方式。
我们目前 workaround 了这个问题,解决方式有点丑陋:Cilium 解析 backend,然后直接
将 neighbor entry 永久性地(NUD_PERMANENT)插入邻居表中。
目前这样做是没问题的,因为邻居的数量是固定或者可控的(fixed/controlled number of
entries)。但后面我们想尝试的是让内核来做这些事情,因为它能以最好的方式处理这个
问题。实现方式就是引入一些新的 NUD_* 类型,只需要传 L3 地址,然后内核自己将解
析 L2 地址,并负责这个地址的维护。这样 Cilium 就不需要再处理 L2 地址的事情了。
但到今天为止,我并没有看到这种方式的可能性。
对于从集群外来的访问 NodePort Service 的请求,也存在类似的问题, 因为最后将响应流量回给客户端也需要邻居表。由于这些流量都是在 pre-routing,因此我 们现在的处理方式是:自己维护了一个小的 BPF LRU map(L3->L2 mapping in BPF LRU map);由于这是主处理逻辑(转发路径),流量可能很高,因此将这种映射放到 BPF LRU 是更合适的,不会导致邻居表的 overflow。
3.4 LRU BPF callback on entry eviction
我们想讨论的另一件事情是:在每个 LRU entry 被 eviction(驱逐)时,能有一个 callback 将会更好。为什么呢?
Cilium 中现在有一个 BPF conntrack table,我们支持到了一些非常老的内核版本 ,例如 4.9。Cilium 在启动时会检查内核版本,优先选择使用 LRU,没有 LRU 再 fallback 到普通的哈希表(Hash Table)。对于哈希表,就需要一个不断 GC 的过程。
我们有意将 NAT map 与 CT map 独立开来,这是因 为我们要求在 cilium-agent 升级或降级过程中,现有的连接/流量不能受影响。 如果二者是耦合在一起的,假如 CT 相关的东西有很大改动,那升级时那要么 是将当前的连接状态全部删掉重新开始;要么就是服务中断,临时不可用,升级完成后再将 老状态迁移到新状态表,但我认为,要轻松、正确地实现这件事情非常困难。 这就是为什么将它们分开的原因。但实际上,GC 在回收 CT entry 的同时, 也会顺便回收 NAT entry。
另外一个问题:每次从 userspace 操作 conntrack entry 都会破坏 LRU 的正常工作流程(因为不恰当地更新了所有 entry 的时间戳)。我们通过下面的 commit 解决了这个问题,但要彻底避免这个问题,最好有一个 GC 以 callback 的方式在第一时 间清理掉这些被 evicted entry,例如在 CT entry 被 evict 之后,顺便也清理掉 NAT 映射。这是我们正在做的事情(译注,Cilium 1.9+ 已经实现了)。
50b045a8c0cc (“bpf, lru: avoid messing with eviction heuristics upon syscall lookup”) fixed map walking from user space
3.5 LRU BPF eviction zones
另一件跟 CT map 相关的比较有意思的探讨:未来是否能根据流量类型,将 LRU eviction 分割为不同的 zone?例如,
- 东西向流量分到 zone1:处理 ClusterIP service 流量,都是 pod-{pod,host} 流量, 比较大;
- 南北向流量分到 zone2:处理 NodePort 和 ExternalName service 流量,相对比较小。
这样的好处是:当对南北向流量 CT 进行操作时,占大头的东西向流量不会受影响。
理想的情况是这种隔离是有保障的,例如:可以安全地假设,如果正在清理 zone1 内的 entries, 那预期不会对 zone2 内的 entry 有任何影响。不过,虽然分为了多个 zones,但在全局, 只有一个 map。
3.6 BPF 原子操作
另一个要讨论的内容是原子操作。
使用场景之一是过期 NAT entry 的快速重复利用(fast recycling)。 例如,结合前面的 GC 过程,如果一个连接断开时, 不是直接删除对应的 entry,而是更 新一个标记,表明这条 entry 过期了;接下来如果有新的连接刚好命中了这个 entry,就 直接将其标记为正常(非过期),重复利用(循环)这个 entry,而不是像之前一样从新创 建。
现在基于 BPF spinlock 可以实现做这个功能,但并不是最优的方式,因为如果有合适的原 子操作,我们就能节省两次辅助函数调用,然后将 spinlock 移到 map 里。将 spinlock 放到 map 结构体的额外好处是,每个结构体都有自己独立的结构(互相解耦),因此更能 够避免升级/降低导致的问题。
当前内核只有 BPF_XADD 指令,我认为它主要适用于计数(counting),因为它并不像原
子递增(inc)函数一样返回一个值。此外内核中还有的就是针对 maps 的 spinlock。
我觉得如果有 READ_ONCE/WRITE_ONCE 语义将会带来很大便利,现在的 BPF 代码中其实已
经有了一些这样功能的、自己实现的代码。此外,我们还需要 BPF_XCHG, BPF_CMPXCHG 指
令,这也将带来很大帮助。
3.7 BPF getpeername hook
还有一个 hook —— getpeername() —— 没有讨论到,它用在 TCP 和 connected UDP 场
景,对应用是透明的。
这里的想法是:永远返回 Service IP 而不是 backend pod IP,这样对应用来说,它看到 就是和 Service IP 建立的连接,而不是和某个具体的 backend pod。
现在返回的是 backend IP 而不是 service IP。从应用的角度看,它连接到的对端并不是 它期望的。
3.8 绕过内核最大 BPF 指令数的限制
最后再讨论几个非内核的改动(non-kernel changes)。
内核对 BPF 最大指令数有 4K 条的限制,现在这个限制已经放大到 1M(一百万) 条(但需要 5.1+ 内核,或者稍低版本的内核 + 相应 patch)。
我们的 BPF 程序中包含了 NAT 引擎,因此肯定是超过这个限制的。 但 Cilium 这边,我们目前还并未用到这个新的最大限制,而是通过“外包”的方式将 BPF 切分成了子 BPF 程序,然后通过尾调用(tail call)跳转过去,以此来绕过这个 4K 的限 制。
另外,我们当前使用的是 BPF tail call,而不是 BPF-to-BPF call,因为二者不能同时 使用。更好的方式是,Cilium agent 在启动时进行检查,如果内核支持 1M BPF insns/complexity limit + bounded loops(我们用于 NAT mappings 查询优化),就用这 些新特性;否则回退到尾调用的方式。
有兴趣尝试 Cilium,可以参考下面的快速安装命令:
$ kubeadm init --pod-network-cidr=10.217.0.0/16 --skip-phases=addon/kube-proxy
$ kubeadm join [...]
$ helm template cilium \
--namespace kube-system --set global.nodePort.enabled=true \
--set global.k8sServiceHost=$API_SERVER_IP \
--set global.k8sServicePort=$API_SERVER_PORT \
--set global.tag=v1.6.1 > cilium.yaml
kubectl apply -f cilium.yaml
如有侵权请联系:admin#unsafe.sh