2020-11-04 09:00:00 Author: arthurchiao.github.io(查看原文) 阅读量:134 收藏
Published at 2020-11-04 | Last Update 2020-11-04
This post also provides a Chinese version.
This post serves as a successor to our previous post Trip.com: First Step towards Cloud Native Networking. We will update some of our recent progresses on Cilium-based networking & security.
- 1 Networking @Trip.com: a quick revisit
- 2 Cloud native networking
- 3 Cloud native security
- 4 Conclusion
- References
For historical reasons, Neutron+OVS has been our networking stack in the past years - even for our Kubernetes clusters. As cloud native era approaches, this solution gets increasingly cumbersome, especially its inherent hardware and software bottlenecks in the face of the sheer scale of containers today [1].
So, to address the bottlenecks, as well as to meet the ever-increasing new networking requirements, we devoted lots of efforts to investigating and evaluating various kinds of new generation networking solutions, and in the end Cilium won our favor.

Fig 1-1. Networking solutions over the past years [2]
In combination with BGP [3], Cilium landed our production environment at the end of 2019. Since then, we have been migrating our existing Pods from legacy network to Cilium.
As one of the early practitioners, we’ve made certain customizations to smoothly rollout Cilium into our existing infrastructure. Below lists some of them [2]:
- Deploy with
docker-compsoe + saltinstead ofdaemonset+configmap. - Run BGP with
BIRDinstead ofkube-router. - Fixed IP address patch for StatefulSet (working together with sticky scheduling).
- Custom monitoring and alerting.
- Many configuration customizations.
We have detailed most of these changes and customizations in [2], refer to the post if you are interested.
In the next, we’d like to elaborate on some topics that are not covered much before.
2.1 BGP peering model
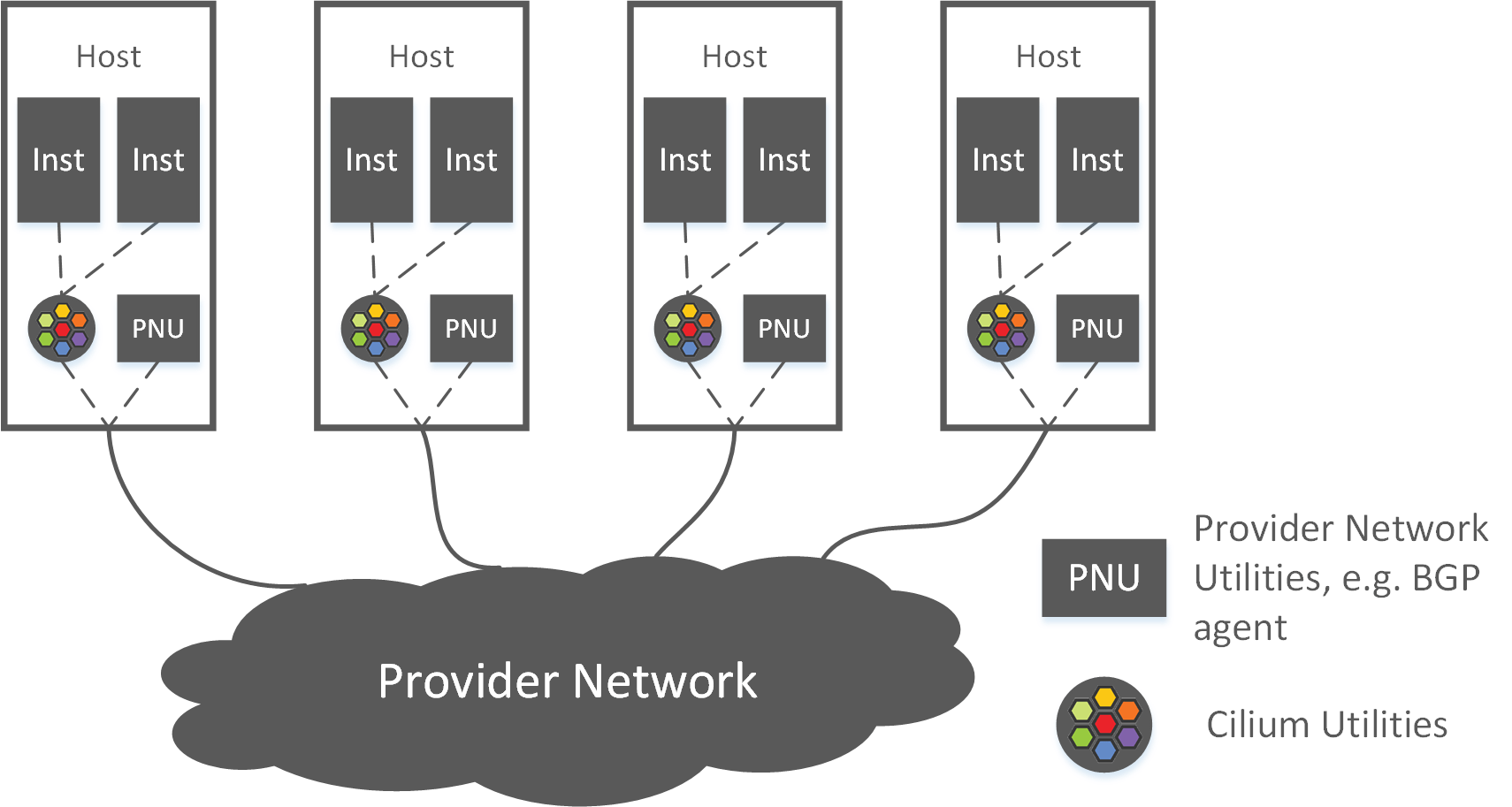
With Cilium+BIRD, networking is split into two complementary parts, with the host as boundary, as shown in Fig 2-1:
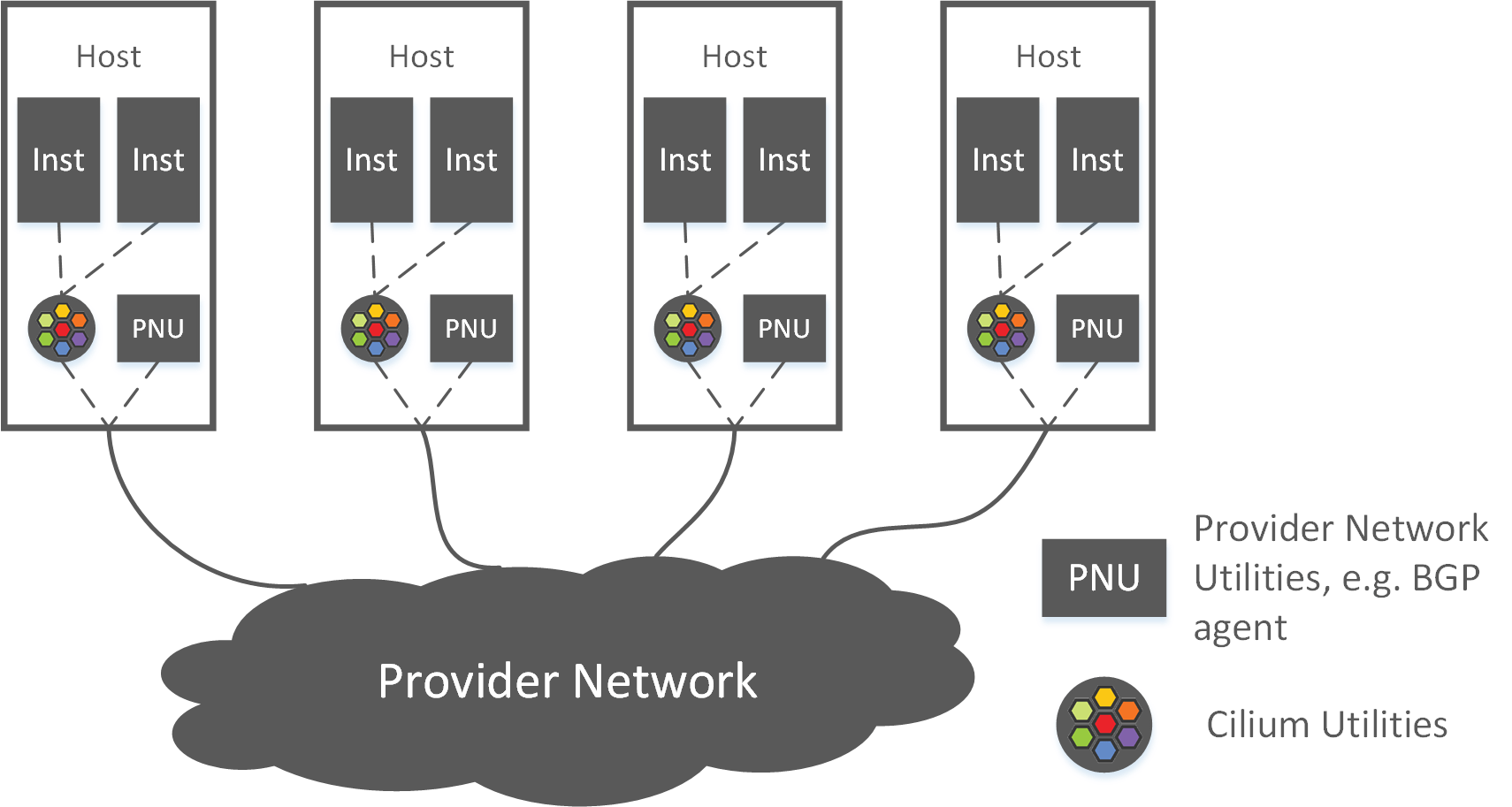
Fig 2-1. High level topology of the Cilium+BGP solution [2]
- Inner-host networking: handled by Cilium (and the kernel stack),
which is responsible for
- Setting up and tearing down virtual networks for Pods,
- Generating, compiling and loading eBPF for Pods,
- Handling inter-Pod communications where the two sides are on the same host.
- Cross-host networking: accomplished via BGP (and kernel routing):
- Exchanging routes (PodCIDRs) with underlying data center network with BIRD.
- Routing Pod traffic that destinated for endpoints on other hosts.
And regarding to the second part - cross-host networking with BGP - a BGP peering model is needed, which solves questions such as,
- What’s responsibilities the BGP agents take? As full functionality agents, or just simple BGP speakers?
- Which part of the data center network will establish connections with BGP agents?
- Which protocol is used for exchanging routes, iBGP or eBGP?
- What’s your ASN scheme?
Regarding to specific requirements, it may end up with a really complex model. But we made a simple one that fitted well into our capabilities and business needs, described as below:
- Each node runs a Cilium agent and a BIRD daemon,
- Allocate a
/25or/24PodCIDR when the node turns up. - BIRD initiates 2 BGP connections with neighbors in the data center network.
- BIRD anounces the PodCIDR to neighbors, but accepts nothing from the latter.
- Allocate a
- Data center network accepts only
/25or/24BGP announcements from nodes, but does not announce any routes to them.
This scheme is simple in that,
- Data center network learns all nodes’ PodCIDRs via BGP, which made the Pod traffic routable within the entire data center.
- Nodes learn nothing from data center network (and other nodes), which keeps the kernel routing table at a constant size, suffering no performance issues. All traffic destinated for Pods on other hosts just goes through node’s default route.

Fig 2-2. BGP peering model in 3-tier network topology
On choosing BGP protocols as well as establishing BGP connections, it depends on different hardware network topologies,
- For access-aggregation-core topology, as shown in Fig 2-2,
- Connections established between nodes and Core switches.
- Use iBGP between them.
- For Spine-Leaf topology
- Connections established between nodes and their adjacent leaf swithes.
- Use eBGP between them.
We have summarized our practices as a getting started guide, see Using BIRD to run BGP [3].
2.2 Typical traffic path: pod-to-service
As an example, let’s see a typical traffic path within this networking solution: accesing Service from a Pod, with the backend located on another node, as shown below,

Fig 2-3. Traffic path: accessing Service from a Pod [4]
Major steps as numbered in the picture:
- Access a Service (
curl <ServiceIP>:<port>) from Pod1 at Node1. - Client side service handling via eBPF: select a Service
backend, then perform DNAT, replacing the ServiceIP with Pod4IP in the
packet’s
dst_ipfield. - Kernel routing: look up kernel routing table with packet’s destination IP; match default route, decide that this packet should be sent out via host bond/NIC.
- Packet arrived bond/NIC: send out to Node1’s gateway, which locates at data center network.
- Routing within data center network. As data center network has already learned PodCIDRs from Node1 and Node2 via BGP before this, it could now determine by destination IP that this packet should be sent to Node2.
- Traffic arrived Node2’s NIC/bond: handled by another piece of eBPF code, which extracts packet header, looks for a Pod-specific eBPF code, and tail call to it.
- Perform ingress policy enforcement for this packet. If allowed, deliver it to Pod4.
- Packet arrived Pod4.
We have a dedicated post for illustrating this process and the code implementation at each stage, see [4] if you’re interested.
2.3 L4/L7 solutions at cluster edge
By its design, ServiceIP is meant to be accessed only within each Kubernetes cluster, what if I’d like to access a Service from outside of the cluster? For example, from a bare metal cluster, an OpenStack cluster, or another Kubernetes cluster?
The good news is that, Kubernetes already ships several models for these accessing patterns, for example,
- L7 model: named Ingress, supports accesing Services via layer 7, e.g. via HTTP API.
- L4 model: including externalIPs Service, LoadBalancer Service, supports accessing Services via L4, e.g. VIP+Port.
The bad news is: Kubernetes only provides these models, but the implementations are left to each vendor. For example, if you are using AWS, its ALB and ELB just corresponds to the L7 and L4 implementation, respectively.
For our on-premises clusters, we proposed a L4 solution with Cilium+BGP+ECMP. It’s essentially a L4LB, which provides VIPs that could be used by those externalIPs and LoadBalancer type Services in Kubernetes cluster:
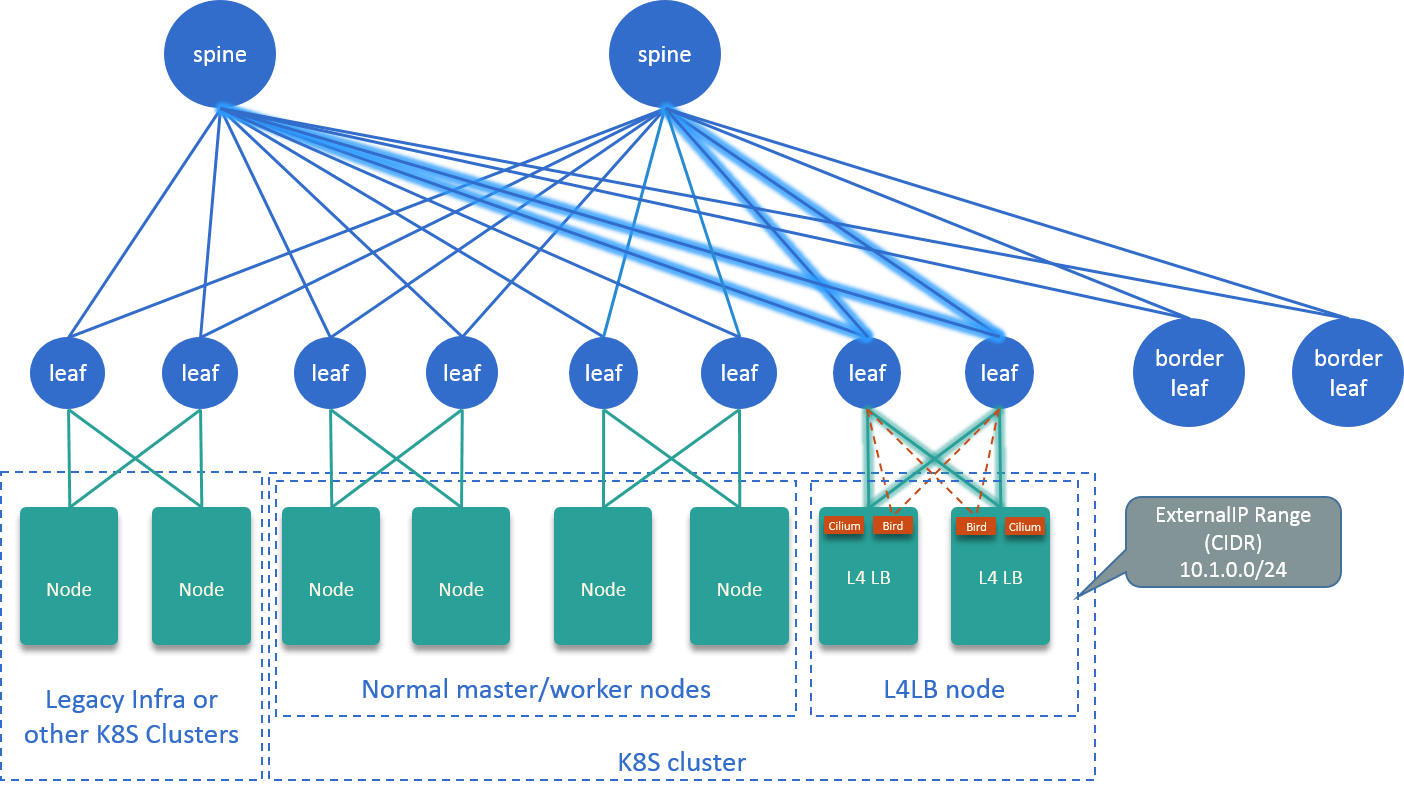
Fig 2-4. L4LB solution with Cilium+BGP+ECMP [5]
Based on this L4 solution, we deployed istio ingress-gateway, which implements the L7 model. A typical traffic path:
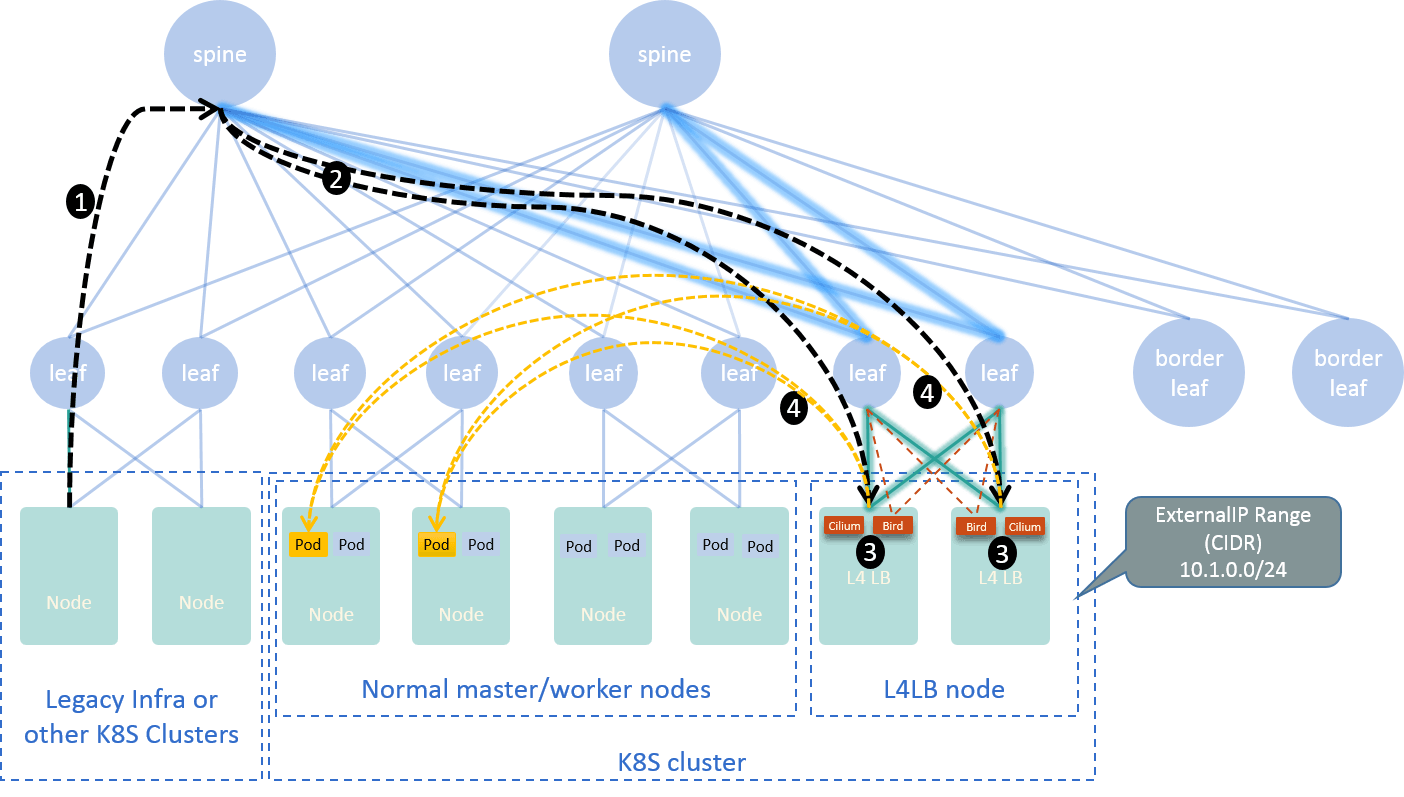
Fig 2-5. Traffic path when accesing Service from outside the Kubernetes cluster [5]
We have a dedicated post for illustrating this, see [5].
Cilium features two cutting edge functionalities:
- Networking: eBPF-based, flexible, dynamic, high performance.
- Security: CiliumNetworkPolicy as a superset of Kubernetes’s NetworkPolicy model, provides L3-L7 network policy enforcement.
As a big step, we are trying to carry out the security capabilities into our infrastructure.
3.1 Cilium Network Policy (CNP)
Let’s first take a simple example, have a glance at what a CiliumNetworkPolicy (CNP) looks like [6]:
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "clustermesh-ingress-l4-policy"
description: "demo: allow only employee to access protected-db"
spec:
endpointSelector:
matchLabels:
app: protected-db
ingress:
- toPorts:
- ports:
- port: "6379"
protocol: TCP
fromEndpoints:
- matchLabels:
app: employee
The above yaml says:
- Create a CNP, with the provided
nameanddescription. - Enforce this CNP to endpoints (pods) that match label
app=protected-db. - Filter over the
ingress(inbound) traffic of the matched endpoints (server side), allow only if- Protocols and ports each match
TCPand6379. - Traffic is from client endpoints which are labeled
app:employee.
- Protocols and ports each match
As can be seen, CNP is really flexible and easy to use. But to roll it out into real environments in enterprises, there may be considerable challenges.
3.2 Carry-out challenges
As an example, we think below challenges are not specific to us alone.
Multi-cluster
If all your applications run in Cilium, and all your to-be-secured applications converged to a single cluster (most public cloud vendors suggest one big Kubernetes cluster inside each region), then it’ll be fairly easy to rollout things.
But this assumption almost always proves to be false in the reality, especially in companies whose infrastructures have evolved from many many years ago. In other words, “neat” and well-orginazed infrastructures are ideal rather than real.
Hybrid infrastructures
The more bigger challenge for us is that, we still have so many non-Cilium or even non-Kubernetes clusters.
The reality we are facing is: applications scattered among Cilium-powered Kubernetes clusters, Neutron-powered Kubernetes clusters, OpenStack clusters, and bare metal clusters.
Although in the long run, Neutron-powered Kubernetes clusters will fade out, but OpenStack clusters as well as bare metal clusters will continue to live (although may gradually scale down), so we must consider them when planning.
3.3 Security solution design
The security solution we came up:
-
Enforce CNP at only server side, clients could come from any cluster, any platform.
This limits the scope and simplifies the overall design.
-
Only consider (the server side) Cilium Pods at the first stage rollout of this solution.
This is a good starting point, and we expect major part of our server side applications will be running in Cilium clusters.
The, the remaining question is: how to enforce network policy over clients that coming from outside of a cluster, or even outside of Cilium’s awareness? Our answer is:
- First, group Cilium clusters into a ClusterMesh;
- Then, “extend” ClusterMesh to make it be aware of external endpoints.
Each explained below.
3.3.1 Group Cilium clusters into ClusterMesh

Fig 3-1. Vanilla Cilium ClusterMesh [6]
ClusterMesh [7] is a multi-cluster solution provided by Cilium. This solves the multi-cluster problem if all applications are deployed as native Cilium endpoints (Pods).
Using ClusterMesh sounds to be straight forward, but actually it was not our first choice then. Several reasons:
- First, regarding to some internal scenarios, we’ve considered developing an in-house component to synchronize metadata between Kubernetes clusters.
- Besides, we haven’t seen any sharings which claimed that ClusterMesh got used at large scale.
3.3.2 Extend Cilium to perceive non-Cilium endpoints
Here, non-Cilium endpoints include Neutron-powered Pods, VMs, BMs.
Looking at the code, Cilium already has an abstraction for these endpoints, named external endpoints, but, this feature is currently lessly implemented and publicized.

Fig 3-2. Proposed security solution over hybrid infrastructures
As shown above, as an (community compatible) extension to Cilium, we developed a custom API suite, which allows specific owners to fed their instances’ metadata into Cilium cluster, the Cilium will perceive them as external endpoints. And more, we ensure that external points’ create/update/delete events will be timely notified to Cilium.
Combining 3.3.1 & 3.3.2, our extended ClusterMesh now possesses an entire view over our hybrid infrastructures, which is sufficient for enforcing network policy over all types of clients.
This post shares some of our recent processes on Cilium-based networking & security.
- Ctrip Network Architecture Evolution in the Cloud Computing Era
- Trip.com: First Step towards Cloud Native Networking.
- Cilium Doc: Using BIRD to run BGP
- Life of a Packet in Cilium: Discovering the Pod-to-Service Traffic Path and BPF Processing Logics
- L4LB for Kubernetes: Theory and Practice with Cilium+BGP+ECMP
- Cilium ClusterMesh: A Hands-on Guide
- Cilium Doc: clustermesh
如有侵权请联系:admin#unsafe.sh