阅读: 0
webshell 是 Web 攻击中常见的一种木马形式,目前主流的检测方法都是基于 HTTP 请求和响应流量的内容特征,然而在 HTTPS 协议下,很多 webshell 检测机制是无能为力的。冰蝎这类加密型 webshell 的出现更是增加了检测难度,尤其是冰蝎3.0版本采用预共享密钥机制,即使在 HTTP 场景中的检测也是有一定难度的。
本文通过提取网络流量中的若干特征,主要针对访问同一 HTTPS 网站的正常加密流量和 webshell 加密流量的分类进行了探索,实现了在 HTTPS 加密流量中 webshell 通信流量的识别,无论对于冰蝎2.0还是3.0升级版,都能够达到很好的识别效果。
一、背景
由于 Web 服务具有很强的便利性,已经被越来越多地用于提供信息服务,然而其中的数据和用户信息也成为了很多不法分子获利的目标。webshell 是一种基于 Web 服务的后门程序,提供了对各种关键功能的远程访问,例如执行任意命令、遍历文件目录、查看和修改任意文件、提升访问权限等。所以如何有效地识别出 webshell 文件或通信是一个亟待解决的问题。
目前较为成熟的 webshell 检测方法一般有三种:日志检测、文件检测和流量检测,主流的检测方式都必须由人工构建字符特征作为输入参数,然而攻击者可以通过对 webshell 代码进行变形从而达到绕过检测的目的,并且随着越来越流行的加密型 webshell 的出现和 HTTPS 加密流量的广泛使用,无疑给 webshell 检测带来了更大的挑战。
本文利用流量检测的方式并基于统计特征,聚焦于在 HTTPS 加密流量中识别出包含冰蝎在内的 webshell 通信流量,分别从数据采集、特征提取、模型训练和预测、特征重要性分析等方面展开阐述。
二、冰蝎3.0
冰蝎是目前比较流行的加密型 webshell 客户端,它可以在通信过程中建立加密隧道,以躲避安全设备的检测。近期发布的3.0版本,对通信流量产生影响的主要是密钥交换方式的改变,其余都是一些功能上的改进。除了对一些 bug 的修复,涉及到流量变化的修改具体是:
- 去除动态密钥协商机制,采用预共享密钥,全程无明文交互;
- 请求体增加了随机冗余参数,避免防护设备通过请求体大小识别请求。
三、webshell 加密流量检测
1. 数据集
为了采集流量数据,我们自建了一个网站,并且安装使用了自签名证书,使得访问该网站的流量都是 TLS 加密的。所以无论是常见的非加密型 webshell 还是冰蝎这类加密型 webshell,访问该网站产生的都是 HTTPS 流量。
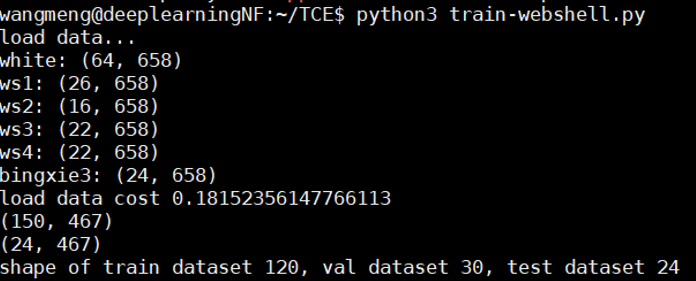
我们目前共收集了访问该网站的具有代表性的6种类型的流量数据,分别是正常访问的流量、两类页面性 webshell 的流量和三类客户端型 webshell 的流量,其中客户端型包括使用量最大的中国菜刀和对流量进行加密的冰蝎,近期也特别收集了新发布的冰蝎3.0的流量。
由于本文旨在研究访问同一 HTTPS 网站的正常加密流量和 webshell 加密流量的分类,所以将所有数据分为正常和 webshell 两种类型,分别标记为0和1。每种数据的标签和数量如表3.1所示,这里数据量的单位是数据包利用 Joy 解析之后双向网络流的数量。
表3.1 数据集的标签和数量统计列表
| 标签 | 流量类型 | webshell 类型 | 双向流数 |
| 0 | 正常 | 非 webshell | 64 |
| 1 | 页面型 | 页面型No.1 | 26 |
| 1 | 页面型 | 页面型No.2 | 16 |
| 1 | 客户端型 | 中国菜刀2016 | 22 |
| 1 | 客户端型 | 冰蝎2.0 | 22 |
| 1 | 客户端型 | 冰蝎3.0 | 24 |
2. 特征提取
调用 Joy 对数据包进行解析,得到 json 格式的解析结果,经过处理后提取出五种主要的数据元素,包含六百多维特征,分别是:
(1)数据流元特征
(2)数据包包长序列
(3)数据包时间间隔特征
(4)数据包字节分布特征
(5)数据包 TLS 特征
据观察,对访问同一 HTTPS 网站的 webshell 流量和正常流量作对比,具有如下表3.2中所列的几个特点。
表3.2 访问同一 HTTPS 网站的 webshell 流量和正常流量对比
| 特征 | 区别 |
| TLS 特征 | 完全相同 |
| 入流的包数量 | 正常加密流量通常较多,而 webshell 一般较少 |
| 总熵 | 正常加密流量一般会大 webshell 一个数量级 |
关于熵值,如果数据经过加密或编码处理,那么它的熵值就会变大,所以 webshell 在熵值特征上与正常流量的区别符合常理。
3. 模型训练和测试
使用 LightGBM 作为 webshell 流量识别分类模型,一些重要参数的设计如下:
learning_rate = 0.1
n_estimators = 200
colsample_bytree = 0.9
num_leaves = 7
subsample = 0.9
(1)在冰蝎3.0发布之前,我们已经收集了表3.1中除冰蝎3.0之外的所有数据,并做了一些研究,分别进行了下面三个小实验。
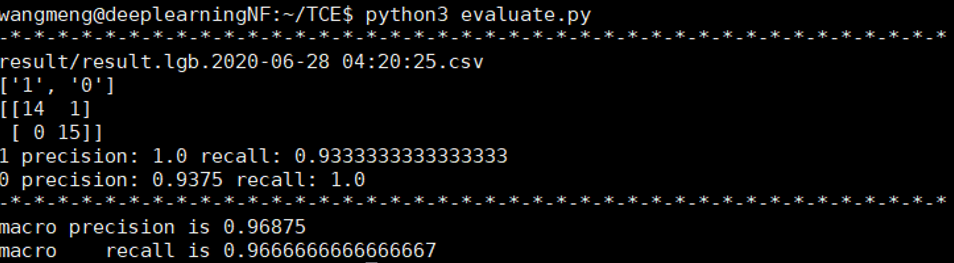
实验一:使用所有流量,随机选出20%作为测试集,剩余的随机选出20%作为验证集,其他80%作为训练集,整体准确率较高,实验结果显示,测试集中只有一条流被分类错误,准确率为96.9%。
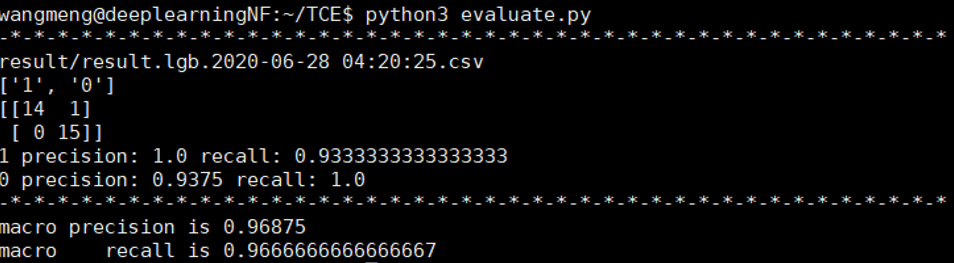
实验二:由于数据量较少很可能导致过拟合,所以进行了交叉验证,预留出页面型No.2的数据作为测试集,使用其余的数据作为训练集和验证集,实验结果显示,16条数据流中预测正确的是15条,准确率是93.7%。
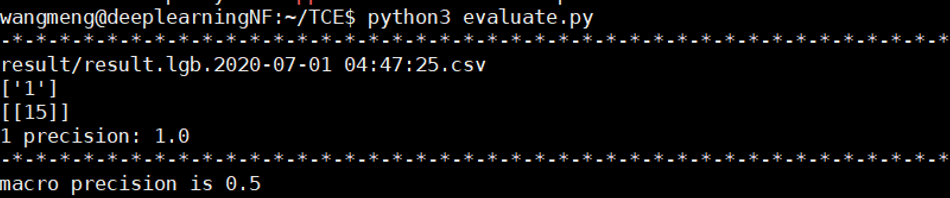
实验三:由于冰蝎2.0是当时数据集中唯一的加密型 webshell,所以单独预留出冰蝎2.0的数据作为测试集,使用其余的数据作为训练集和验证集,实验结果显示,22条数据流中预测正确的是18条,准确率是81.8%。

从实验一和实验二可以看出,模型经过训练之后,对访问同一 HTTPS 网站的正常流量和 webshell 流量具有较好的识别能力。实验三则证明了 webshell 本身是否是加密类型对模型的识别能力没有任何影响,即使在加密型 webshell 并不存在于训练集中的情况下,模型依然能识别出冰蝎的流量。
(2)最近冰蝎发布3.0版本,虽然功能上的改进对流量识别影响不大,但是我们想看看密钥交换方式的改变对流量识别的影响,所以在前面实验的基础上继续研究。我们新收集了3.0版本的冰蝎访问自建 HTTPS 网站的流量,由于网站的 TLS 证书已经发生变化,为了避免 TLS 相关特征对实验结果的影响,以下实验只使用了前四种数据元素,包含四百多维特征。
实验四:使用之前的所有数据进行训练和验证,将冰蝎3.0流量作为测试集输入训练好的模型中进行测试,实验结果显示,24条数据流中预测正确的是23条,准确率是95.8%。
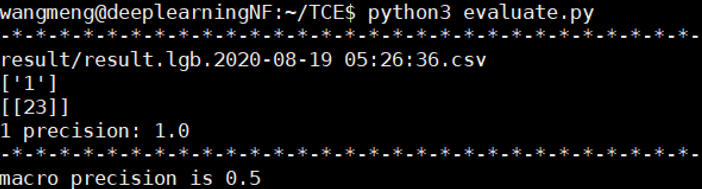
实验五:因为之前的数据中有冰蝎2.0产生的流量,为了避免不同版本冰蝎的相似性对实验结果造成的影响,去掉训练集中的冰蝎2.0数据,让训练集中不包含任何加密型 webshell 流量,还是使用冰蝎3.0的流量作为测试集,实验结果显示,24条数据流中预测正确的是23条,准确率是95.8%。
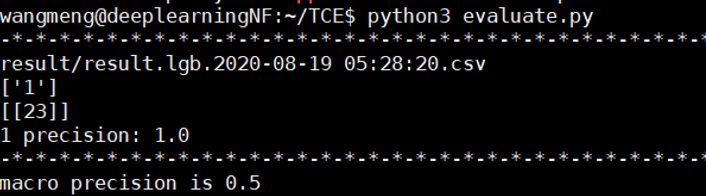
从实验四可以看出,在模型对访问同一 HTTPS 网站的正常流量和 webshell 流量具有识别能力的情况下,模型依然能够识别新版本的冰蝎流量,也就是冰蝎3.0流量的出现并没有影响模型的识别能力。实验五则证明了和实验三相同的结论,即 webshell 本身是否是加密类型对模型的识别能力没有任何影响。
4. 特征重要性分析
如图3.1所示,分别顺序展示了五个实验的重要程度较高的10个特征,column 列表示特征所在的维度,importance 列表示特征重要程度,数值越大,重要程度越高,按降序排列。
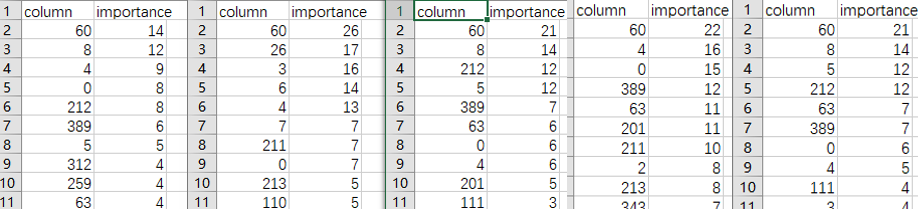
图3.1 五个实验的特征重要性
表3.1中观察到的后两个特征入流的包数量和总熵分别是第0维和第8维特征,由图3.1可以看出,两者都发挥了比较重要的作用,而 TLS 特征并没有发挥任何作用,符合观察到的特点。另外,虽然每次模型训练使用到的特征重要性不尽相同,但也可以发现,一些重要的特征基本不变,只是特征重要程度有所变化。
四、小结
本文主要研究了访问同一 HTTPS 网站的正常加密流量和 webshell 加密流量的分类问题,实验结果表明,经过训练的模型不仅对正常加密流量和包含冰蝎在内的 webshell 加密流量具有较好的识别能力,而且即使在训练集中只包含非加密型 webshell 的情况下,模型依然能够识别冰蝎这类加密型 webshell,冰蝎3.0版本也不例外。
当然这只是一个初步探索,未来还有很多工作需要继续。首先,数据对机器学习模型的训练非常重要,本文实验中用到的数据量是较少的,虽然能在一定程度上说明问题,但是还需要更多的数据来进行验证;其次,webshell 的检测需要结合安全专家知识提取出更有区分度的特征,好的特征工程直接决定了模型效果的上限;最后,数据平衡、模型调优等都是机器学习方法中不可缺少的部分,对模型预测结果有着积极的作用。