
#人工智能 微软宣布开源基于图的检索增强生成 (RAG) 方法 --- GraphRAG,该方法能够对私有或以前从未见过的数据集进行问答,有助于大幅度提高 AI 回答的准确性。GraphRAG 的优势在于能够在用户查询之前报告数据的语义结构,通过层次化密集连接的节点社区将图分割为多个层次,再使用 AI 创建数据摘要提供数据集的概览。查看全文:https://ourl.co/104784
微软在今年年初推出了 GraphRAG — 这是一种基于图 (Graph) 的检索增强生成 (RAG) 方法,能够对私有或以前从未见过的数据集进行问答,比传统 RAG 方法可以更好的结构化信息检索和提供更全面的响应生成,重点是可以大幅度提高 AI 回答的准确性。

今天微软宣布 GraphRAG 在 Github 上开源,GraphRAG 代码库还提供了一个解决方案加速器,即提供简单易用的 API 体验,这个 API 也已经托管到 Azure 上,开发者无需编写任何代码,只需要几次点击即可部署。
GraphRAG 利用大型语言模型自动从任何文本文档集合中提取丰富的知识图谱,这种基于图的数据索引特性之一就是能够在用户查询之前报告数据的语义结构。
之后再通过层次化的方式检测密集连接的节点社区,将图分割为从高级主题到低级主题的多个层次,如下图所示:使用 LLM 总结这些节点社区可以创建数据的层次性摘要、提供数据集的概览,无需事先知道要问哪些问题。
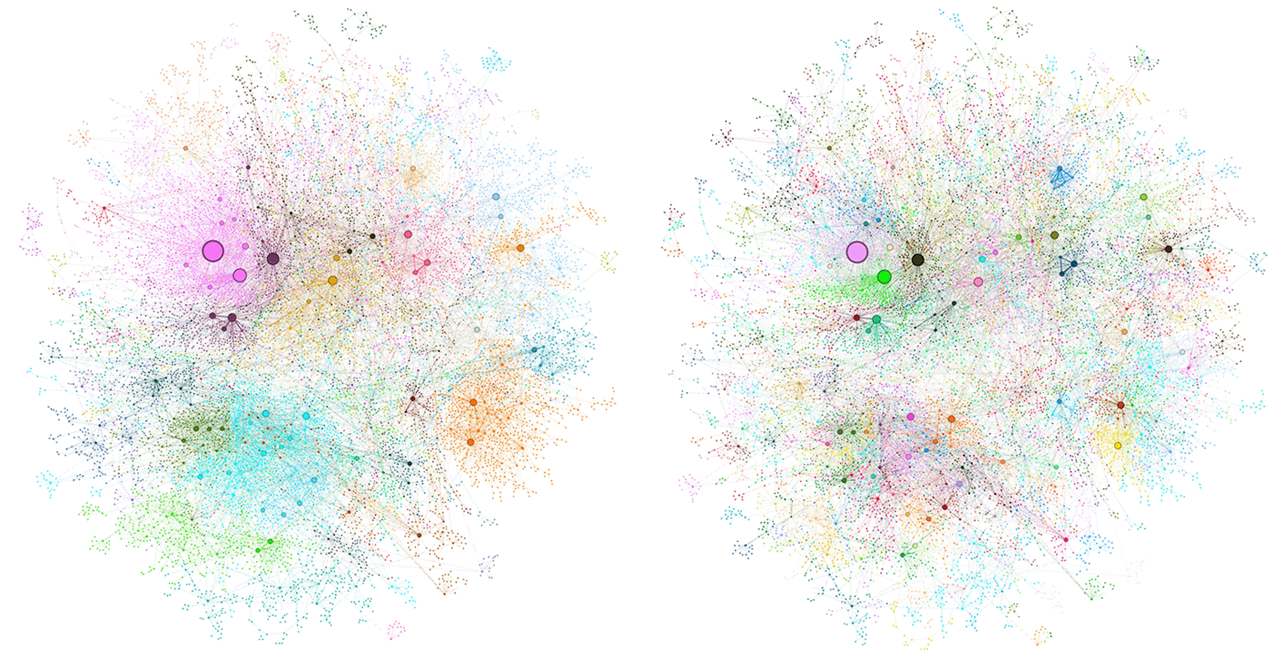
上图中不同颜色代表不同的节点社区、左图为 0 级社区代表主题优先级最高、右图为 1 级社区显示子主题
对全局问题的社区摘要优势:
微软在最近发布的一篇论文中详细介绍了社区摘要如何有助于回答全局问题,这些问题通常涉及整个数据集而不是专注于特定的文本块。
在这种情况下基于向量搜索的简单 RAG 方法显然是不够的,例如考虑数据集中的主要主题是什么时,简单的 RAG 往往会给出错误答案,因为这种方法是通过问题语义上相似的文本块生成答案,不一定是回答问题所需的输入文本子集。
然而,如果一个问题涉及整个数据集那就应该考虑所有输入文本,由于简单的 RAG 只考虑最重要的前 k 个输入文本块,这就会出现问题。
更糟糕的是简单的 RAG 方法还会将问题与哪些表面上看起来与该问题相似的文本框匹配起来,这会导致出现误导性答案而非正确的内容。
而社区摘要有助于回答此类全局问题,因为实体和关系描述的图索引已经考虑了其构建中的所有输入文本,因此可以使用 map-reduce 方法进行问答,保留数据背景相关的所有内容。
微软开源 GraphRAG 后所有开发者和企业都可以在 Github 上获取该项目并基于该项目开发或改进自己的项目,这不仅为开发者社区提供了一个强大的工具,也为信息检索和响应生成领域带来了新的独特 RAG 方法。
有兴趣的开发者可以点击这里查看论文:https://www.microsoft.com/en-us/research/publication/from-local-to-global-a-graph-rag-approach-to-query-focused-summarization/
项目地址:https://github.com/microsoft/graphrag