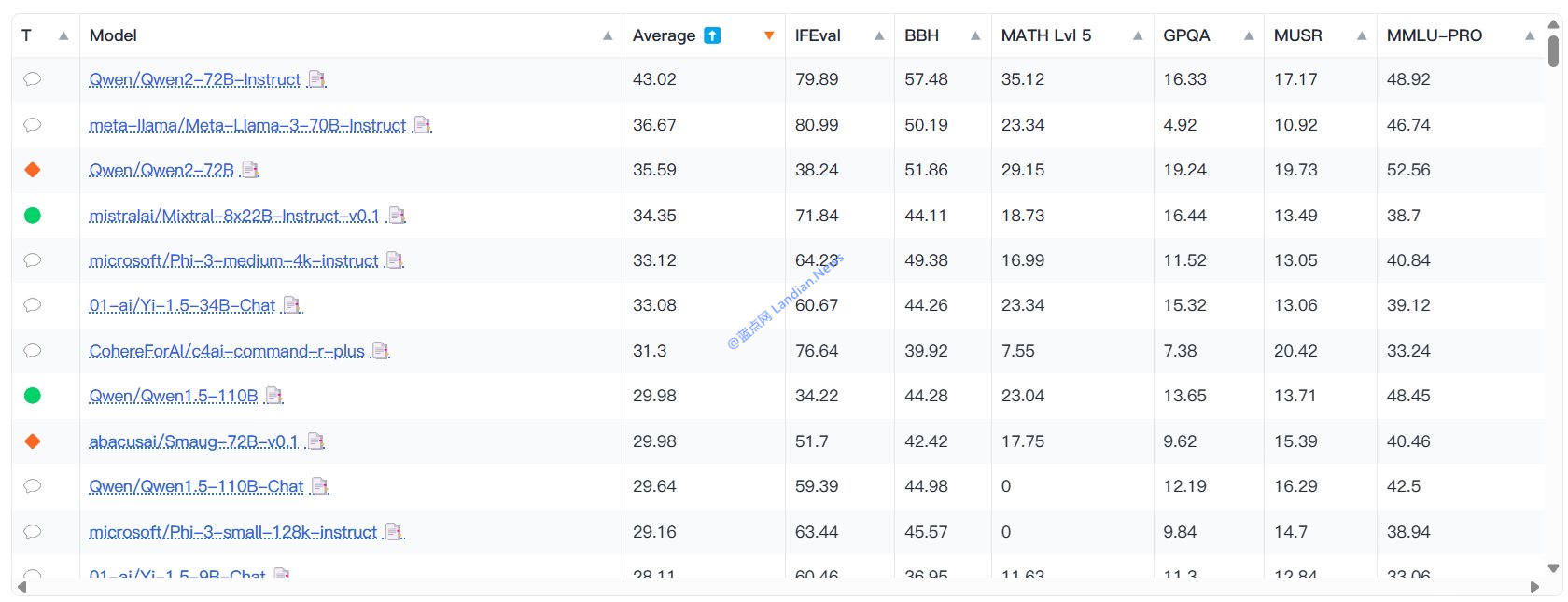
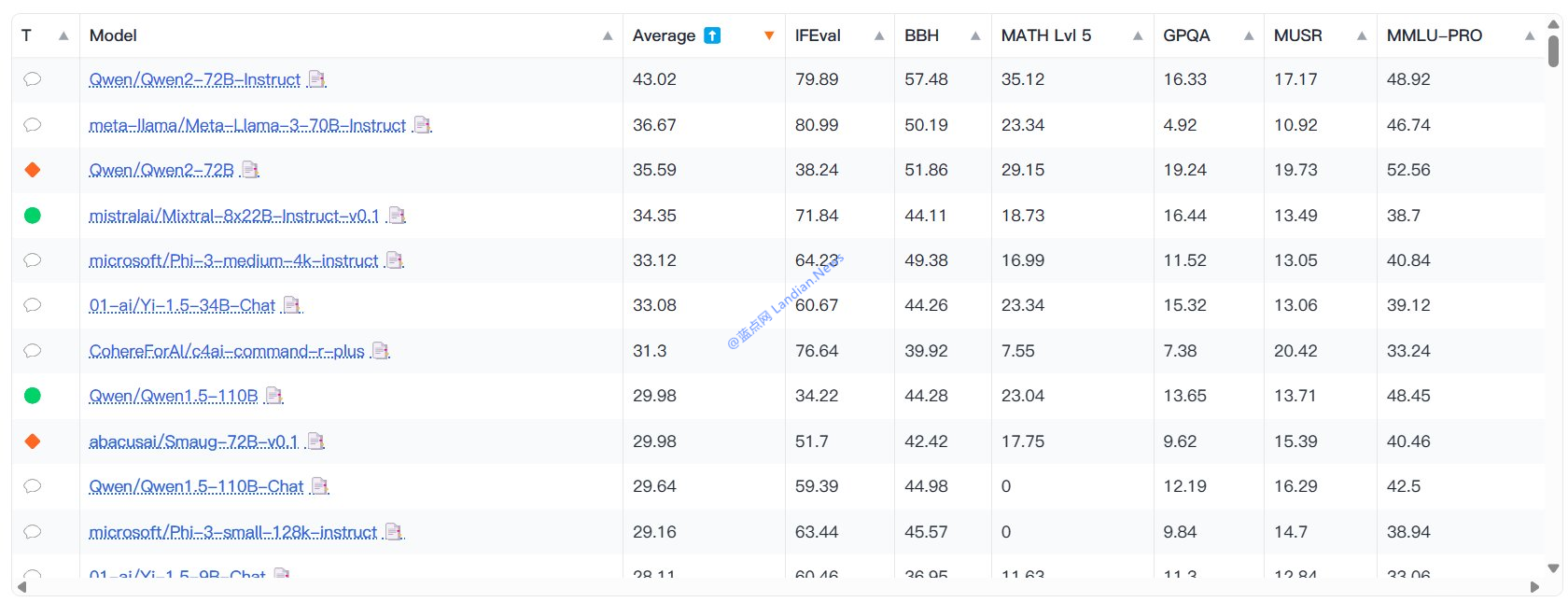
#人工智能 HuggingFace 搭建新系统评估开源和开放模型,此次测试阿里云通义千问 Qwen-72B 版力压群雄排名第一。值得注意的是测试也发现部分模型存在作弊,即针对基准测试进行优化以取得更好的分数,但在新系统中就被暴露出来了,未来这种情况应该会越来越多。查看全文:https://ourl.co/104711
知名模型托管平台 HuggingFace 日前使用 300 张 NVIDIA H100 AI 加速卡构建了一个新系统用来测试开源和开放的人工智能模型,此次测试使用 MMLU-Pro 等 AI 模型测试集,较此前的测试集难度有所提升。
该平台称以前的数据测试集对于现在新推出的模型来说实在是太简单了,就像是拿初中试卷给高中生考试一样,因此无法真正有效的评估模型能力。
而且出于营销和宣传考虑,部分模型实际上存在作弊行为,即使用经过优化的提示词或评估设置来为模型提供最佳机会,这样可以取得更高的分数。
这种情况就像是部分 Android 厂商在进行跑分测试时会冻结其他应用释放内存和降低 CPU 使用率,甚至还会通过外部硬件进行降温来获得更过的基准测试分数。
基于这种原因 HuggingFace 此前构建了 Open LLM Leaderboard,通过设置完全相同的问题、相同的排序等来评估模型,收集在真实世界中用户也可以重现和可比较的结果。
现在为了尽可能获得真实有效的评估结果,HuggingFace 推出了 Open LLM Leaderboard v2 版,使用 300 张英伟达的 H100 加速卡和数据集对模型进行了重新评估。
在最新发布的测试中,阿里云推出的通义千问系列模型超过 Meta Llama 系列模型成为综合能力最强的模型,获得第一的具体模型是通义千问 Qwen-72B 版。
此次测试有几个特点:
- 测试显示模型参数规模并不是越大越好,也就是有些超大规模参数的模型能力也不是特别好
- 新的评测有效解决了此前评测难度太低的问题,可以更好的反映目前模型的真实能力
- 有迹象表明 AI 公司开始关注于主要测试,而忽略了其他方面的表现,也就是只关注跑分
这应该是目前 AI 行业里首次有明确提到测试作弊的说法,也就是一些开发商现在可能会侧重于对基准测试进行优化以取得更好的分数,这种情况显然是不好的,但由于 AI 公司现在实在是太多,这些公司为了表现自己用于宣传或融资等目的,只能尽可能优化分数来吸引人注意。
除了常规的作弊方法外 (就是上面提到的使用优化后的提示词和测试设置),这种针对基准测试进行优化的做法难以发现,未来行业可能要花费更多时间构建更独特的测试集来评估模型。