
05/14/2024
6 min read

Golang 1.20 introduced support for Profile Guided Optimization (PGO) to the go compiler. This allows guiding the compiler to introduce optimizations based on the real world behaviour of your system. In the Observability Team at Cloudflare, we maintain a few Go-based services that use thousands of cores worldwide, so even the 2-7% savings advertised would drastically reduce our CPU footprint, effectively for free. This would reduce the CPU usage for our internal services, freeing up those resources to serve customer requests, providing measurable improvements to our customer experience. In this post, I will cover the process we created for experimenting with PGO – collecting representative profiles across our production infrastructure and then deploying new PGO binaries and measuring the CPU savings.
How does PGO work?
PGO itself is not a Go-specific tool, although it is relatively new. PGO allows you to take CPU profiles from a program running in production and use that to optimise the generated assembly for that program. This includes a bunch of different optimisations such as inlining heavily used functions more aggressively, reworking branch prediction to favour the more common branches, and rearranging the generated code to lump hot paths together to save on CPU cache swapping.
The general flow for using PGO is to compile a non-PGO binary and deploy it to production, collect CPU profiles from the binary in production, and then compile a second binary using that CPU profile. CPU Profiles contain samples of what the CPU was spending the most time on when executing a program, which provides valuable context to the compiler when it’s making decisions about optimising a program. For example, the compiler may choose to inline a function that is called many times to reduce the function call overhead, or it might choose to unroll a particularly jump-heavy loop. Crucially, using a profile from production can guide the compiler much more efficiently than any upfront heuristics.
A practical example
In the Observability team, we operate a system we call “wshim”. Wshim is a service that runs on every one of our edge servers, providing a push gateway for telemetry sourced from our internal Cloudflare Workers. Because this service runs on every server, and is called every time an internal worker is called, wshim requires a lot of CPU time to run. In order to track exactly how much, we put wshim into its own cgroup, and use cadvisor to expose Prometheus metrics pertaining to the resources that it uses.
Before deploying PGO, wshim was using over 3000 cores globally:
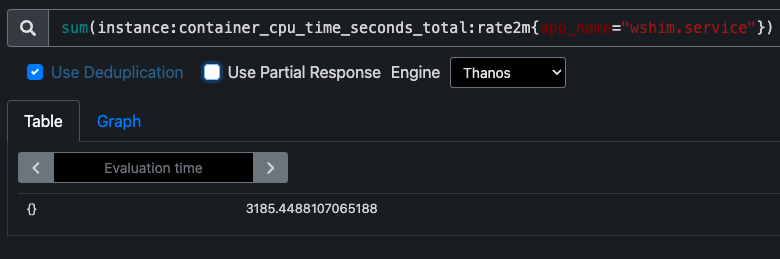
container_cpu_time_seconds is our internal metric that tracks the amount of time a CPU has spent running wshim across the world. Even a 2% saving would return 60 cores to our customers, making the Cloudflare network even more efficient.
The first step in deploying PGO was to collect representative profiles from our servers worldwide. The first problem we run into is that we run thousands of servers, each with different usage patterns at given points in time – a datacenter serving lots of requests during daytime hours will have a different usage pattern than a different data center that locally is in the middle of the night. As such, selecting exactly which servers to profile is paramount to collecting good profiles for PGO to use.
In the end, we decided that the best samples would be from those datacenters experiencing heavy load – those are the ones where the slowest parts of wshim would be most obvious. Even further, we will only collect profiles from our Tier 1 data centers. These are data centers that serve our most heavily populated regions, are generally our largest, and are generally under very heavy loads during peak hours.
Concretely, we can get a list of high CPU servers by querying our Thanos infrastructure:
num_profiles="1000"
# Fetch the top n CPU users for wshim across the edge using Thanos.
cloudflared access curl "https://thanos/api/v1/query?query=topk%28${num_profiles}%2Cinstance%3Acontainer_cpu_time_seconds_total%3Arate2m%7Bapp_name%3D%22wshim.service%22%7D%29&dedup=true&partial_response=true" --compressed | jq '.data.result[].metric.instance' -r > "${instances_file}"
Go makes actually fetching CPU profiles trivial with pprof. In order for our engineers to debug their systems in production, we provide a method to easily retrieve production profiles that we can use here. Wshim provides a pprof interface that we can use to retrieve profiles, and we can collect these again with bash:
# For every instance, attempt to pull a CPU profile. Note that due to the transient nature of some data centers
# a certain percentage of these will fail, which is fine, as long as we get enough nodes to form a representative sample.
while read instance; do fetch-pprof $instance –port 8976 –seconds 30' > "${working_dir}/${instance}.pprof" & done < "${instances_file}"
wait $(jobs -p)
And then merge all the gathered profiles into one, with go tool:
# Merge the fetched profiles into one.
go tool pprof -proto "${working_dir}/"*.pprof > profile.pprof
It’s this merged profile that we will use to compile our pprof binary. As such, we commit it to our repo so that it lives alongside all the other deployment components of wshim:
~/cf-repos/wshim ± master
23/01/2024 10:49:08 AEDT❯ tree pgo
pgo
├── README.md
├── fetch-profiles.sh
└── profile.pprof
And update our Makefile to pass in the -pgo flag to the go build command:
build:
go build -pgo ./pgo/profile.pprof -o /tmp/wshim ./cmd/wshim
After that, we can build and deploy our new PGO optimized version of wshim, like any other version.
Results
Once our new version is deployed, we can review our CPU metrics to see if we have any meaningful savings. Resource usages are notoriously hard to compare. Because wshim’s CPU usage scales with the amount of traffic that any given server is receiving, it has a lot of potentially confounding variables, including the time of day, day of the year, and whether there are any active attacks affecting the datacenter. That being said, we can take a couple of numbers that might give us a good indication of any potential savings.
Firstly, we can look at the CPU usage of wshim immediately before and after the deployment. This may be confounded by the time difference between the sets, but it shows a decent improvement. Because our release takes just under two hours to roll to every tier 1 datacenter, we can use PromQLs `offset` operator to measure the difference:


This indicates that following the release, we’re using ~97 cores fewer than before the release, a ~3.5% reduction. This seems to be inline with the upstream documentation that gives numbers between 2% and 14%.
The second number we can look at is the usage at the same time of day on different days of the week. The average usage for the 7 days prior to the release was 3067.83 cores, whereas the 7 days after the release were 2996.78, a savings of 71 CPUs. Not quite as good as our 97 CPU savings, but still pretty substantial!
This seems to prove the benefits of PGO – without changing the code at all, we managed to save ourselves several servers worth of CPU time.
Future work
Looking at these initial results certainly seems to prove the case for PGO – saving multiple servers worth of CPU without any code changes is a big win for freeing up resources to better serve customer requests. However, there is definitely more work to be done here. In particular:
- Automating the collection of profiles, perhaps using continuous profiling
- Refining the deployment process to handle the new “two-step deployment”, deploying a non PGO binary, and then a PGO one
- Refining our techniques to derive representative profiling samples
- Implementing further improvements with BOLT, or other Link Time Optimization (LTO) techniques
If that sounds interesting to you, we’re hiring in both the USA and EMEA!
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.