一、前言
源代码审计,顾名思义就是检查源代码中是否存在安全隐患,使用自动化工具以及人工的方式对源代码进行分析检查,发现源代码的这些缺陷引起的漏洞,并提供修复措施和建议。
在开始之前,我们先了解一下MVC设计模式的基本概念:
MVC:全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写。其中:
Model(模型)一般用于放置对数据库进行存取等操作的代码
View(视图)一般用于放置静态资源如前端代码、css等
Controller(控制器)用于存放接受用户输入和业务逻辑处理的代码。
我们以Java的SpringMVC来举例,SpringBoot项目的三层架构如下:
Model层:包含service层和dao层
Service层用来实现业务逻辑
Dao层的作用是封装对数据库的访问:增删改查,不涉及业务逻辑
Controller层:负责业务模块的流程控制
View层:html、css、js等等
过程如下:
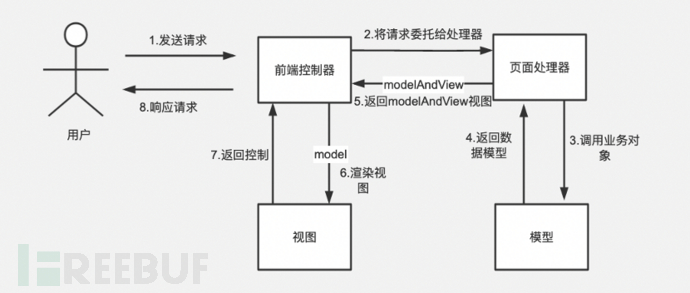
有了这些知识之后,我们就可以大致定位到文件位置了。
二、代码审计的方法
下面我们来介绍三种常用的代码审计的方式:
全文通读 | 敏感函数溯源 | 功能点定向审计 | |
说明 | 从系统入口开始审计,分析所有数据流走向。 | 搜索敏感函数,逆向追踪参数的传递过程,分析参数是否可控。 | 定位敏感功能点,分析其是否存在安全缺陷。 |
优点 | 能够覆盖所有请求入口,避免了遗漏代码的情况。 | 高效。 | 高效 |
缺点 | 需要足够的时间与精力 | 对系统整体结构了解不够深入,无法覆盖逻辑漏洞。 | 容易出现审计遗漏的情况。 |
说明:上述三种方法均为纯人工代码审计的方法,一般情况下我们采用静态源代码扫描工具检测 + 人工验证 + 人工检查相结合的方式
三、审计工具介绍
Fortify:通过内置的五大主要分析引擎:数据流、语义、结构、控制流、配置流等对源代码进行静态分析,分析的过程中与它特有的软件安全漏洞规则集进行全面地匹配、查找。
Checkmax:通过虚拟编译器自动对软件源代码分析,并建立了代码元素及代码元素之间关系的逻辑图。然后对这个内部代码图进行查询,包含已知安全漏洞和质量缺陷问题预先设定好的查询列表。
CodeQL:在 CodeQL 中,代码被视为数据(所以进行扫描前,需要先生成源码对应的数据库文件),安全漏洞则被建模为可以对数据库执行的查询语句。
Semgrep: 是一种快速、开源的静态代码分析工具,它提供了强于grep工具的代码匹配检索能力,并支持两种类型的代码模式匹配。一种是基于AST的匹配,另一种是通用文本匹配。
SonarQubec:是一个用于代码质量管理的开源平台,用于管理源代码的质量。可以通过PMD,CheckStyle,Findbugs等等代码规则检测工具检 测出潜在的缺陷。
Fortify和Checkmax属于纯商业软件,各有优缺点,我们重点介绍剩下三款软件。
四、工具的使用
1、Semgrep:
semgrep是一款基于Facebook开源SAST工具pfff中的sgrep组件开发的开源SAST工具,目前由安全公司r2c统一开发维护。
优点: 支持语言丰富,目前已经支持C#, JSON, Json, Kotlin, Rust, Yaml, c, cs, csharp, generic, go, golang, hack, hacklang, html, java, javascript, js, json, kotlin, kt, lua, ml, none, ocaml, php, py, python, python2, python3, rb, regex, rs, ruby, rust, scala, ts, typescript, vue, yaml
开源扫描规则丰富,由社区共同开发维护的扫描规则超过1000条
规则设置简单,采用yaml配置文件编写,语法简单
扫描速度极快:官方称扫描速度大约是每条规则20K-100K loc/sec
生态良好:支持嵌入到几乎所有CI工具中
支持本地扫描:官方不仅提供了VSCode、IntelliJ IDEA、Vim的相关插件,还支持通过pre-commit的方式在代码提交前进行自动扫描
缺点:
数据流跟踪能力较弱
我们通过两小例子来看下semgrep的使用
查找代码中是否使用MD5
Rule:
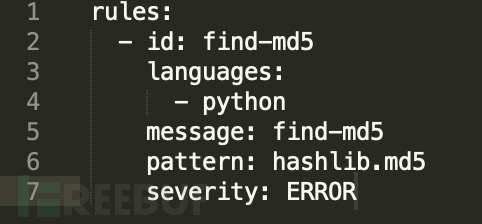
Test code:

Result:

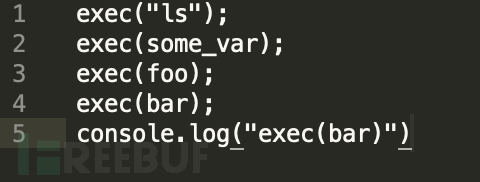
不安全的命令执行
Rele:
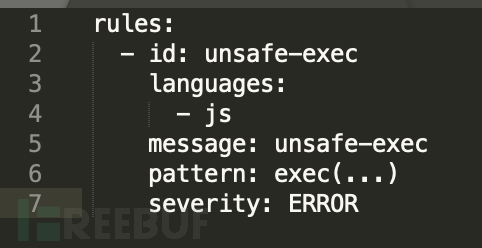
Test Code:
Result:
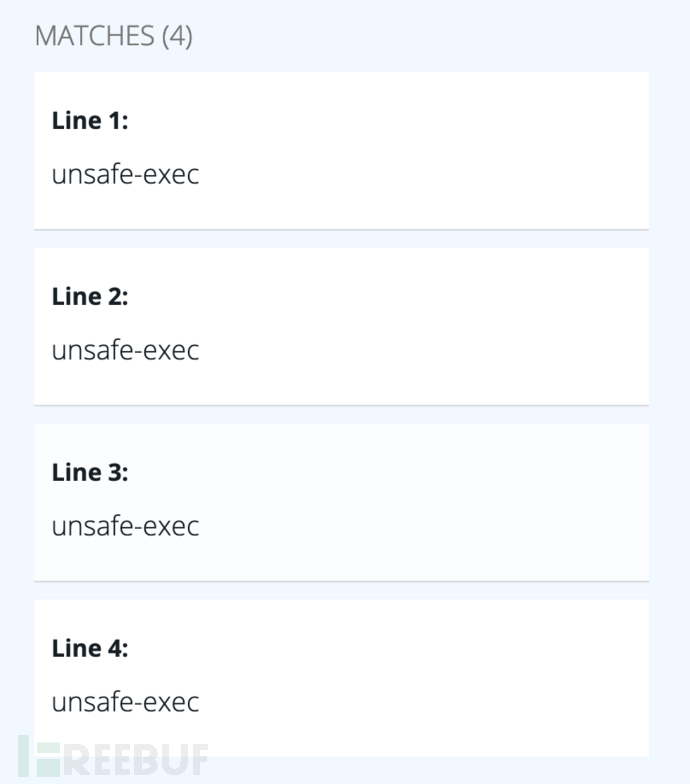
通过这两个小例子我们可以看到semgrep的使用非常简单。即使非常复杂的规则也极少有超过100行的规则。
接下来我们来通过一个小例子,来看下semgrep的一些参数的用法:
Rule: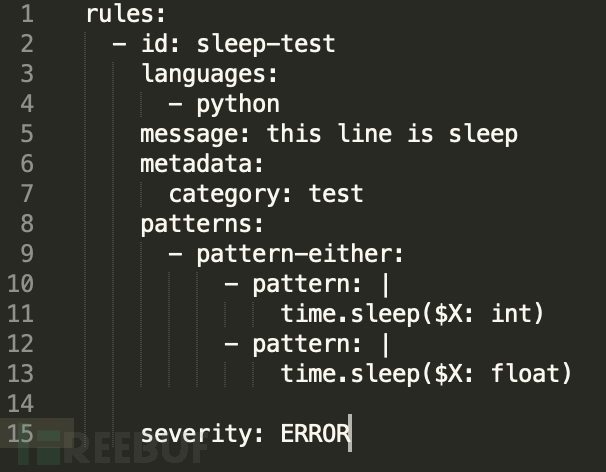
Test Code:
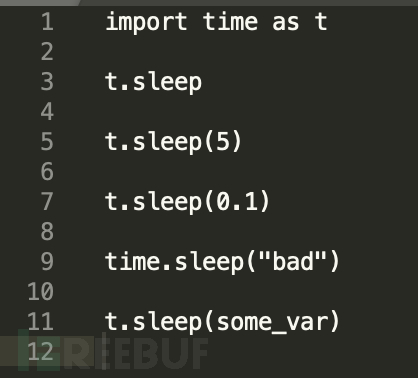
Result:
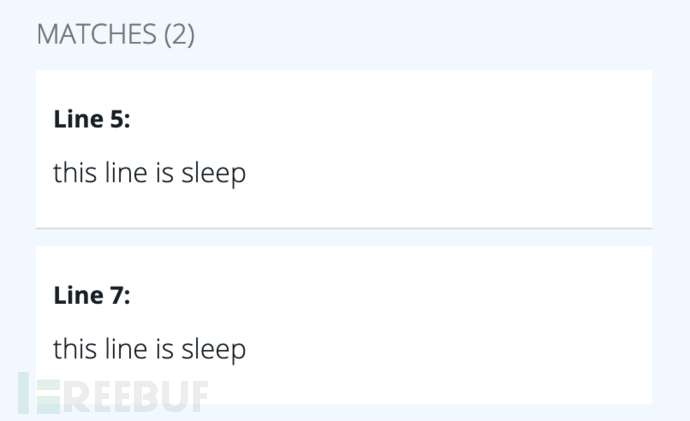
我们可以看到在匹配模式中,sleep函数中用到了int和float两种模式进行匹配,在结果中也确实只匹配到了第五行和第七行代码。而其他行并没有匹配到。
我们来修改下,将sleep函数的参数通过函数返回值的方式传入,看看是否能够匹配
Rule:
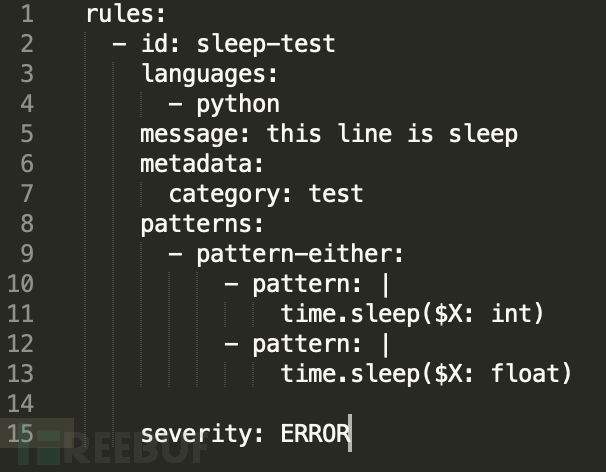
跟上面的规则保持不变
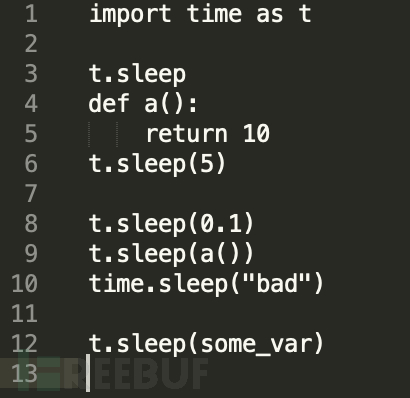
Test Code:
Result:
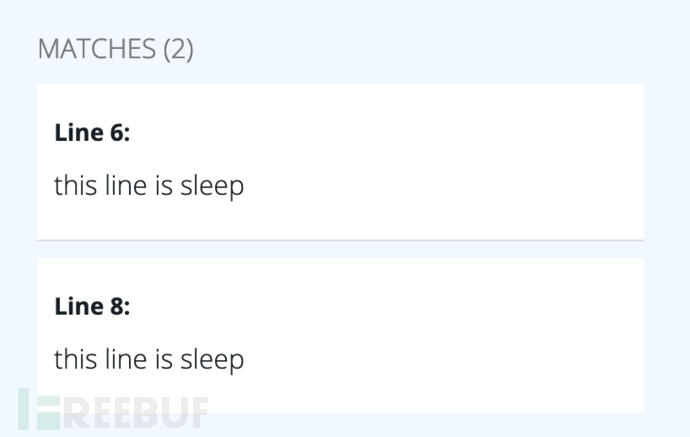
从结果可以看到仍然是只匹配到了第六行和第八行,而在第九行中,函数a的返回值虽然是一个int类型的值,但是并未匹配到,从而也说明了,semgrep的数据流的追踪能力较弱。
如果我们需要匹配到所有sleep的函数,可以在匹配模式中修改
Relue:
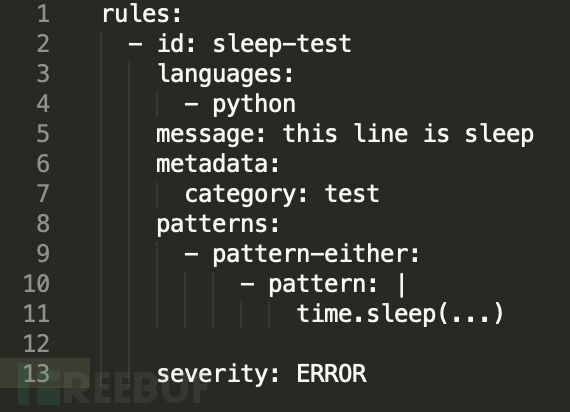
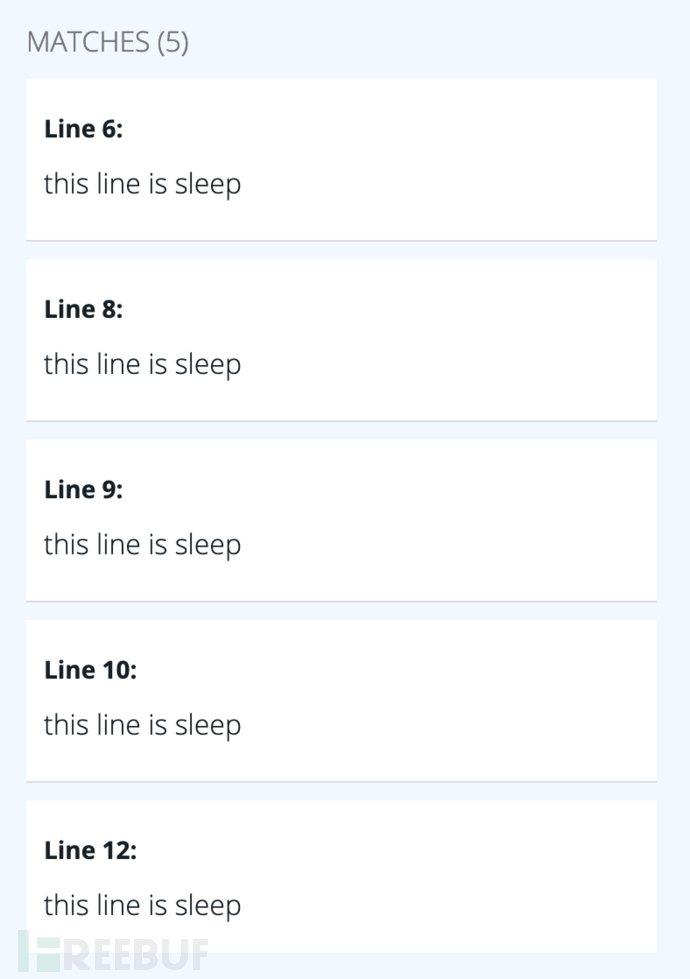
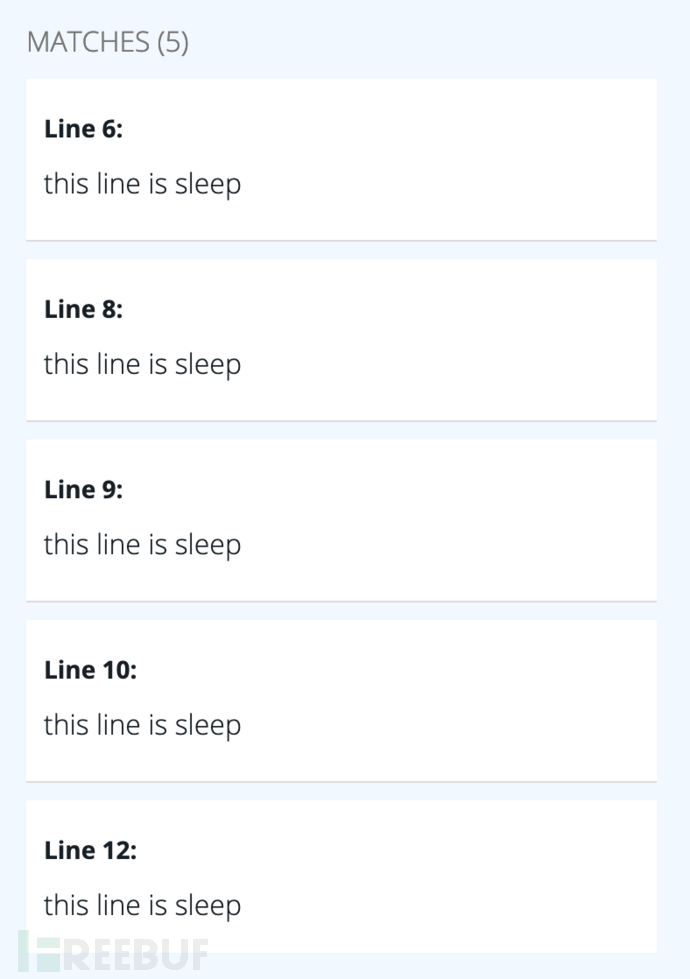
再次对上面的代码进行匹配,则可以看到所有函数都被匹配到了。
Result:
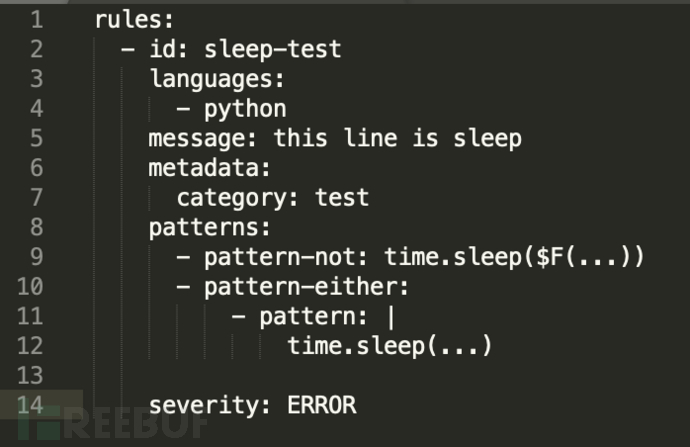
当然在匹配模式中也可以排除掉某些条件,比如我们想匹配所有的sleep的函数,但是通过函数传参的排除掉,则可以修改规则:
Relue:
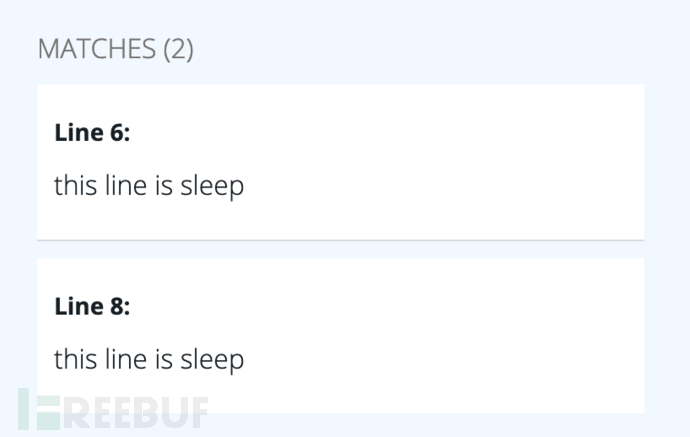
对上述代码进行匹配,可以看到第九行没有匹配到。
Resul
后续计划
codeql和SonarQube工具的使用
典型案例分析
一个完整的项目分析过程
如有侵权请联系:admin#unsafe.sh