Published at 2024-02-15 | Last Update 2024-02-15
整理一些 Linux 服务器性能相关的 CPU 硬件基础及内核子系统知识。
水平有限,文中不免有错误或过时之处,请酌情参考。
- Linux 服务器功耗与性能管理(一):CPU 硬件基础(2024)
- Linux 服务器功耗与性能管理(二):几个内核子系统的设计(2024)
- Linux 服务器功耗与性能管理(三):cpuidle 子系统的实现(2024)
- Linux 服务器功耗与性能管理(四):监控、配置、调优(2024)
- Linux 服务器功耗与性能管理(五):问题讨论(2024)
- 1 CPU 相关的内核子系统
- 2 CPU 频率管理子系统(
cpufreq):调节运行任务时的p-state - 3 idle task:没有 runnable tasks 时占坑
- 4 CPU 空闲管理子系统(
cpudile):空闲时如何节能(c-state) - 5 CPU 功耗管理(PM)QoS:
pm_qos,保证响应时间 - 6 系统定时器(timer)对空闲管理的影响
- 参考资料
1.1 调度器:时分复用 + 任务调度 —— sched
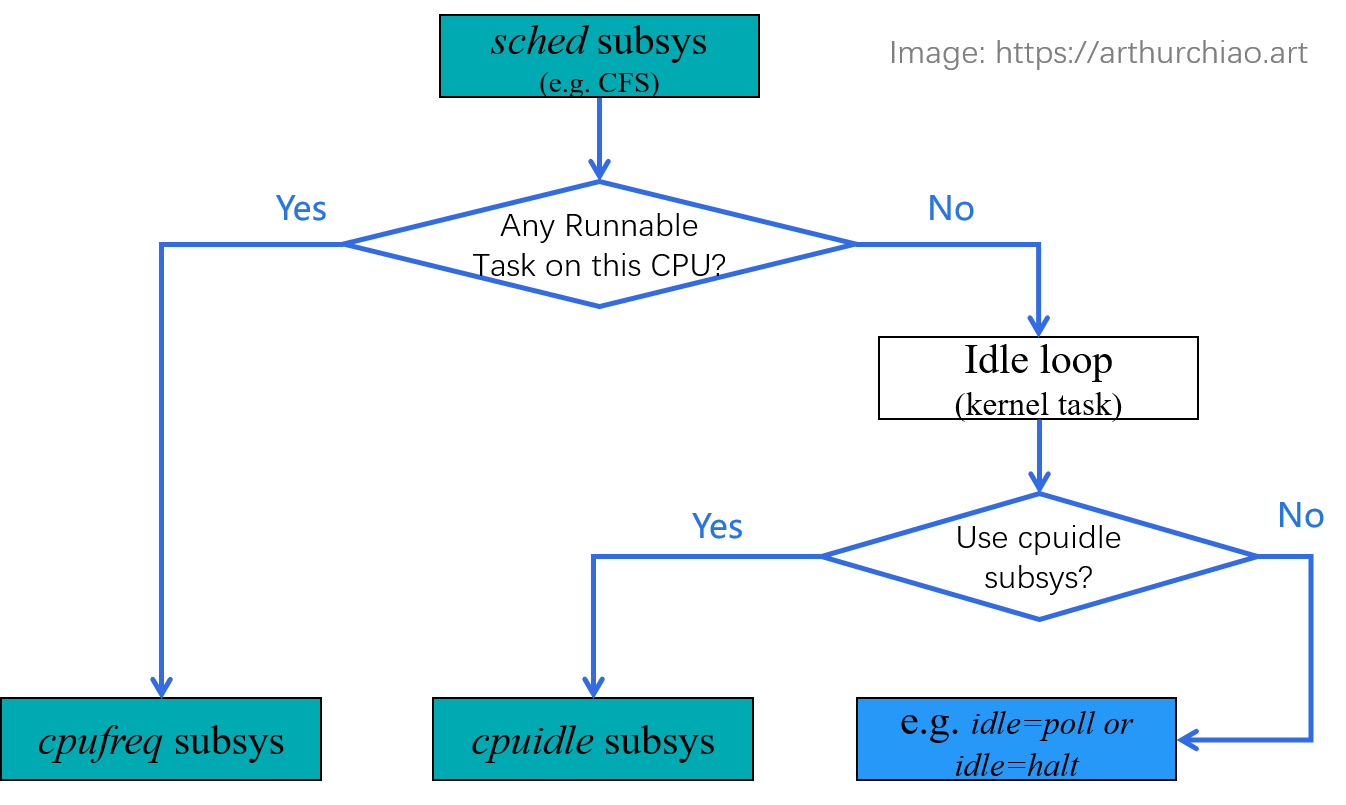
如下图所示,内核给每个 CPU 创建一个任务队列或称运行队列(run queue),
根据算法(例如 CFS)将 runnable 任务依次放到 CPU 上执行,这个过程就称为调度。
Linux kernel scheduler: CFS Image source
本质上就是一个时分复用系统。
更多信息:Linux CFS 调度器:原理、设计与内核实现(2023)
1.3 有任务:用哪个频率执行任务?—— cpufreq
CPU 有任务需要执行时,该以哪个频率/电压来执行呢?
这里就需要一个管理组件,它的主要功能就是管理 CPU 执行任务时所用的频率/电压,
回忆上一篇,这个功能其实就是为 CPU 选择一个合适的 p-state。
Linux 内核中,对应的就是 cpufreq 子系统。
1.4 无任务:执行轻量级占坑程序 —— idle task
事实证明,什么都不做,比大家想象中要复杂地多 (Doing nothing, it turns out, is more complicated than one might think) [5].
如果 run queue 中没有 runnable tasks,CPU 无事可做,内核调度器该做什么?
- 从原理来说,非常简单。产品经理:什么都不做。
- 从实现来说,非常模糊。程序员:“什么都不做”的代码怎么写?
-
开发 leader 理解一下需求,从中翻译一下:
- 先保证一个目标:有任务变成 runnable 时(比如等到了键盘输入),能够恢复调度执行 —— 这决定了内核不能完全退出,比如至少要能主动或被动的响应系统事件;
- 在保证以上目标的前提下,内核做的事情越少越好 —— 节能减排,延迟处理器使用寿命,降本增效。
最终方案:引入一个特殊任务 idle task(很多资料中也叫 idle loop),
没有其他任务可调度时,就调度执行它。
- 从功能上来说,可以认为是一个优先级最低的占坑任务。
-
从实现来说,idle task 里面做什么都可以 —— 反正这时候这个 CPU 上没有任何其他 runnable tasks。 根据目的的不同,具体实现可以分为两大类:
- 节能;
- 低延迟。
区分
"idle task"和"task idle"
idle task task idle 一个特殊进程(任务) 普通进程的一种特殊状态(例如在等待 IO),在这种状态下不需要 CPU 来执行 在 Linux 中,如果除了 "idle task" 已经没有其他任务可运行时, 这个 CPU 就是空闲的,即
idle CPU。
1.4.1 直接降低电压和频率,节能
这是主流行为,idle task 里面实现某种降低功耗的逻辑,避免 CPU 空转,节能。
典型配置如 Linux 内核启动项 idle=halt。
这种方式的缺点是从较低功耗(某种程度的睡眠状态)唤醒时有一定的延迟。
1.4.2 仍然全速运行,保持最低唤醒延迟
这类场景比较特殊,比如追求极低延迟的高频交易场景。
没有任务时仍然让 CPU 保持电压和频率空转,不要降压降频,
这样有任务变成 runnable 时可以立即切换执行,延迟最低。
在 Linux 启动项中,对应 idle=poll 配置,后面几篇我们还会多次看到(尤其是这种配置的潜在风险)。
1.4.3 动态降低电压和频率,节能 —— cpuidle 和 c-states
通过一个单独的子系统(cpuidle)来实现不同级别的节能(c-states)。
这里注意和 turbo freq 的区别:
- turbo 是部分 CORE 空闲时,有任务在运行的 CORE 可以动态超频, 目的是提高这几个有任务在运行的 CORE 的性能;
- cpuidle/c-states 是当前 CORE/CPU 没有任务要运行(空闲 CPU),通过动态降频来节能。
1.5 idle loop 模式之三:空闲时间管理 —— cpuidle
再稍微展开介绍下上面第三种: 队列中如果没有 runnable task,比如所有任务都在等待 IO 事件。 这时候是没有任务需要 CPU 的,因此称为 CPU 空闲状态(idle states)。
空闲状态的下 CPU 该怎么管理,也是一门学问,因此内核又引入了另外一个子系统:
cpu 空闲时间管理子系统 cpudile。具体工作内容后面介绍。
1.6 cpuidle + 响应延迟保证:电源管理服务等级 —— PM QoS
如果没有任务时 cpuidle 选择进入某种低电压/低频率的节能模式,当有任务到来时, 它的唤醒时间可能无法满足要求。针对这种情况,内核又引入了功耗管理或称电源管理 服务等级 (PM QoS)子系统。
PM QoS 允许应用注册一个最大 latency,内核确保唤醒时间不会高于这个阈值, 在尽量节能的同时实现快速响应。 具体原理也在后面单独章节介绍。
1.7 小结:各子系统的关系图
最后用一张图梳理一下前面涉及到的各内核子系统:
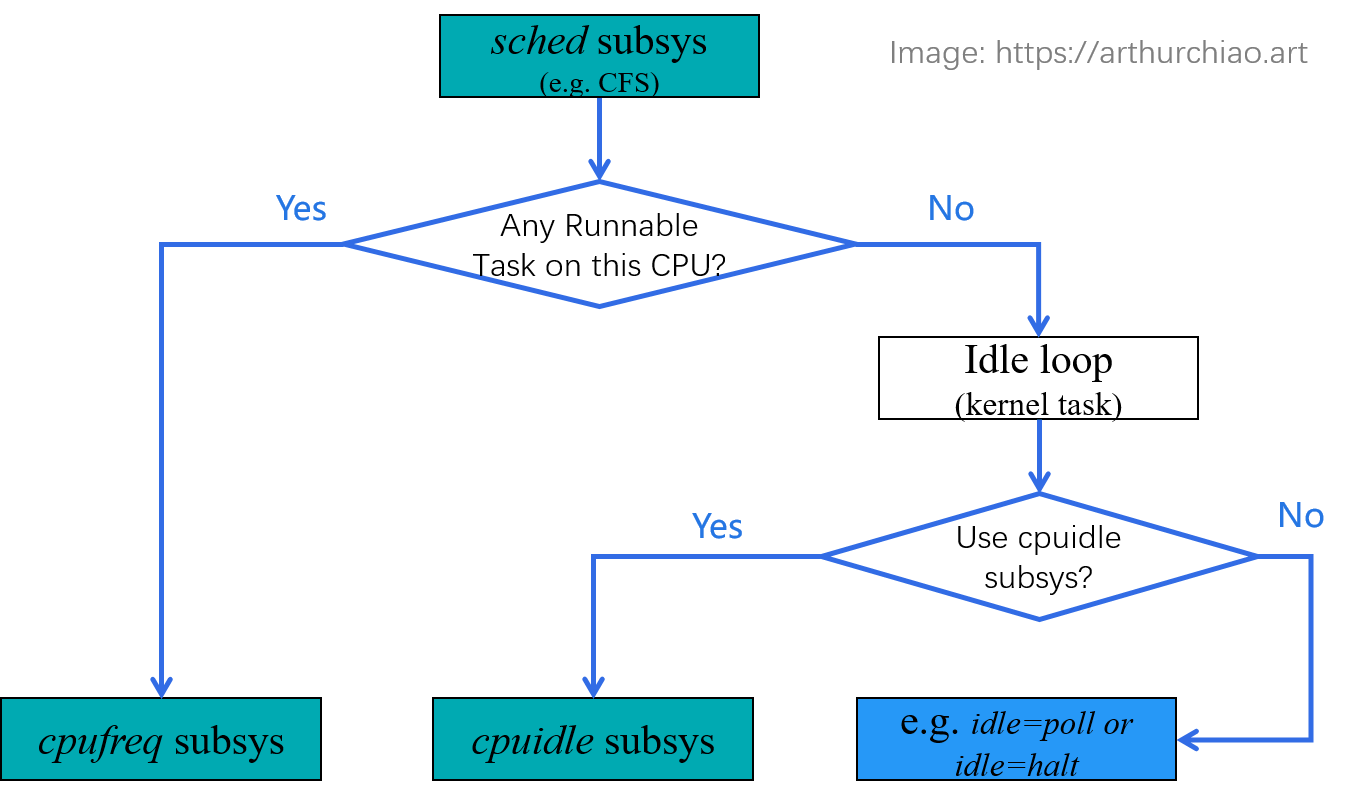
Fig. Relationship of some CPU-related kernel subsystems and tasks
接下来深入到几个子系统的内部看看。
2.1 原理:CPU performance/frequency scaling
处理器硬件有接口暴露给内核,可以设置 CPU 的运行 frequency/voltage,或者说选择不同的 P-state.
一般来说,
- 内核调度器会在一些重要事件发生时(例如新建或销毁进程), 或者定期(every iteration of the scheduler tick)回调 cpufreq update 方法,更新 cpufreq 状态。
- cpufreq 根据状态状态信息,可以动态调整 p-state 级别。
这个功能称为 CPU performance scaling or CPU frequency scaling。
内核文档 CPU Performance Scaling [9] 有详细介绍。
2.2 架构:governor+driver
代码分为三块:
- the core:模型实现和状态维护;
- scaling governors:不同的管理算法;
- scaling drivers:与硬件对接的驱动。
governors
几个比较重要的:
- performance:性能优先
- powersave:节能优先
- userspace:折中
drivers
acpi-cpufreqintel_pstate
2.3 配置
在 sysfs 目录,每个 CPU 一个目录 /sys/devices/system/cpu/cpu{id}/cpufreq/,
$ ls /sys/devices/system/cpu/cpu0/cpufreq/
affected_cpus cpuinfo_min_freq related_cpus scaling_cur_freq scaling_governor scaling_min_freq
cpuinfo_max_freq cpuinfo_transition_latency scaling_available_governors scaling_driver scaling_max_freq scaling_setspeed
2.4 查看两台具体 node
2.4.1 Intel CPU node
先来看一台 Intel CPU 的机器,
(intel node) $ cpupower frequency-info
analyzing CPU 0:
driver: intel_pstate # 驱动,源码在内核树
CPUs which run at the same hardware frequency: 0
CPUs which need to have their frequency coordinated by software: 0
maximum transition latency: Cannot determine or is not supported.
hardware limits: 800 MHz - 3.40 GHz # 硬件支持的频率范围
available cpufreq governors: performance powersave
current policy: frequency should be within 800 MHz and 3.40 GHz.
The governor "performance" may decide which speed to use within this range.
current CPU frequency: Unable to call hardware
current CPU frequency: 2.60 GHz (asserted by call to kernel)
boost state support:
Supported: yes
Active: yes
- driver:
intel_pstate,这个 driver 比较特殊,它绕过了 governor layer,直接在驱动里实现了频率调整算法 [9]。 - CPU 频率范围硬限制:
800MHz - 3.4GHz - 可用 cpufreq governors:
performancepowersave - 正在使用的 cpufreq governor:
performance - 当前策略:
- 频率范围运行在 800MHz - 3.4GHz 之间;
- 具体频率由
performancegovernor 决定。
- 当前 CPU 的频率:
- 从硬件未获取到;
- 从内核获取到的是 2.6GHz
- 是否支持 boost,即
turbo frequency- 支持
- 当前已经开启
2.4.2 AMD CPU node
再看一个 AMD CPU node:
(amd node) $ cpupower frequency-info
analyzing CPU 0:
driver: acpi-cpufreq # 驱动,源码在内核树
CPUs which run at the same hardware frequency: 0
CPUs which need to have their frequency coordinated by software: 0
maximum transition latency: Cannot determine or is not supported.
hardware limits: 1.50 GHz - 3.74 GHz # 硬件支持的频率范围
available frequency steps: 2.80 GHz, 2.10 GHz, 1.50 GHz
available cpufreq governors: conservative ondemand userspace powersave performance schedutil
current policy: frequency should be within 1.50 GHz and 2.80 GHz.
The governor "performance" may decide which speed to use within this range.
current CPU frequency: 2.80 GHz (asserted by call to hardware)
boost state support:
Supported: yes
Active: yes
Boost States: 0
Total States: 3
Pstate-P0: 2800MHz
Pstate-P1: 2100MHz
Pstate-P2: 1500MHz
- driver:
acpi-cpufreq - CPU 频率范围硬限制:
1.5GHz - 3.74GHz - 可用的频率步长:1.5G 2.1G 2.8G
- 可用 cpufreq governors:conservative ondemand userspace powersave performance schedutil
- 正在使用的 cpufreq governor:
performance - 当前策略:
- 频率范围运行在 1.5GHz - 2.8GHz 之间;
- 具体频率由
performancegovernor 决定。
- 当前 CPU 的频率:
- 从硬件获取到 2.8GHz;
- 从内核获取到的是 2.6GHz
- 是否支持 boost,即 turbo
- 支持
- 当前已经开启
- 支持的
p-state频率- Pstate-P0: 2800MHz
- Pstate-P1: 2100MHz
- Pstate-P2: 1500MHz
如果调度队列(rq)为空,或者队列中的所有任务都处于 non runnable 状态,我们就称这个 CPU 是空闲的, 接下来就可以进入某个 c-state 以便降低功耗。从设计上来说,这里可以有两种选择:
- 将进入 c-state 的逻辑直接暴露给调度器,由调度器直接控制;
- 将进入 c-state 的逻辑封装成一个标准的任务(task),放到调度队列里,作为优先级最低的任务。 如果没有任何其他任务可执行,就调度执行这个特殊任务。
Linux 选择的第二种,引入的特殊任务称为 "idle task"。
严格来说,
- 早期系统中真的是进程(线程),优先级最低;干掉这个线程可能是搞垮小型机最简单的方式之一 [3];
- 现代系统中,比如 Linux 内核中,已经是更加轻量级的实现(
ps搜索idle等字样看不到这些进程) 。
一般都是在 CPU 无事可做时通过某种形式的 wait 指令让 CPU 降低功耗。
3.1 idle task 历史
处理器比大多数人想象中要空闲的多。
-
Unix
Unix 似乎一直都有一个某种形式的 idle loop(但不一定是一个真正的 idle task)。 比如在 V1 中,它使用了一个
WAIT指令, 实现了让处理器停止工作,直到中断触发,处理器重新开始执行。 -
DOS、OS/2、早期 Windows
包括 DOS、IBM OS/2、早期 Windows 等操作系统, 都使用 busy loops 实现 idle task。
3.2 Linux idle task 设计
为了保证设计的一致性,Linux 引入了一个特殊的进程 idle task,没有其他 task 可调度时,就执行它。
- 复用标准进程结构
struct task,将“无事可做时做什么”的逻辑封装为 idle task; - 为每个 CPU 创建一个这样的进程(idle task),只会在这个 CPU 上运行;
- 无事可做时就调度这个 task 执行(因此优先级最低),所花的时间记录在
top等命令的idle字段里。
$ top
top - 09:38:34 up 22 days, 22:46, 8 users, load average: 0.24, 0.14, 0.10
Tasks: 168 total, 1 running, 165 sleeping, 2 stopped, 0 zombie
# user system idle wait softirq
%Cpu0 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 3.1 sy, 0.0 ni, 96.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
...
3.3 实现:idle loop
这里只是很简单的看一下,下一篇专门介绍内核实现。
简化之后,
while (1) {
while(!need_resched()) {
cpuidle_idle_call();
}
/*
[Note: Switch to a different task. We will return to this loop when the
idle task is again selected to run.]
*/
schedule_preempt_disabled();
}
如果没有其他任务,就执行 idle。从累积时间来说,idle 函数可能是人类历史上执行时间最长的函数。 [2]
3.4 运行时
3.4.1 1 号进程(PID=1)
我们经常能在教科书或网上看到说,系统启动之后的第一个进程是 init 进程,
它的 PID 是 1,所有其他进程都是这个进程的(N 代)子进程。这句话也不算错,但 init 其实是一个逻辑概念,
真正的 1 号进程名字可能并不叫 “init”。
-
查看一台 ubuntu 机器:
(ubuntu) $ cat /proc/1/cmdline | tr '\0' ' ' /sbin/init splash # /sbin/init is a symlink $ ls -ahl /sbin/init lrwxrwxrwx 1 root root /sbin/init -> /lib/systemd/systemd可以看到最终是执行的
systemd。 -
再来看一台 CentOS 机器,
(centos) $ cat /proc/1/cmdline | tr '\0' ' ' /usr/lib/systemd/systemd --switched-root --system --deserialize 28直接执行的
systemd。
用 pstree 可以直接看到从 PID 1 开始的进程树:
$ pstree -p | head
systemd(1)-+-agetty(13499)
|-atd(9614)
|-auditd(9442)---{auditd}(9443)
|-chronyd(9665)
|-containerd(10324)-+-containerd-shim(14126)-+-pause(14200)
| | |-{containerd-shim}(14127)
...
PID=1 进程是谁创建出来的?有没有可能存在 PID=0 的进程?
3.4.2 0 号进程(PID=0)
ps 查看所有进程,指定 -a 按 PID 升序排列,
$ ps -eaf | head
UID PID PPID CMD
root 1 0 /usr/lib/systemd/systemd --switched-root --system --deserialize 28
root 2 0 [kthreadd] # kernel thread daemon. All kthreads are forked from this thread
root 3 2 [rcu_gp]
root 4 2 [rcu_par_gp]
..
还真能看到 0 号进程,不过它只出现在父进程 PPID 列,是两个进程的父进程:
systemd:PID=1,前面介绍过了,-
kthreadd:PID=2,这是所有内核进程/线程的父进程,- 内核进程是
ps输出中用中括号[]括起来的进程,比如上面看到的[rcu_gp];
- 内核进程是
这也说明上一节我们关于 init 的说明也不太准确,更准确来说,系统启动后
- 所有系统进程(操作系统服务)和用户进程都是从
PID=1的init进程直接或间接 fork 出来的; - 所有内核进程都是从
PID=2的kthreadd进程 fork 出来的;
回到我们的问题,PID=0 是什么呢?
wikipedia.org/wiki/Process_identifier
中有定义,本文不深入,简单把它理解成内核本身(内核最最骨干的执行逻辑),
在所有进程之上,能管理左膀(PID=1)和右臂(PID=2)。
3.4.3 idle task:0 号进程的一部分
做了以上那么多关于 PID 的铺垫,这里回到正题:idle task,是几号进程呢?
- 它的优先级最低,没有其他进程可调度时才会调度到它;
- 它叫“进程”(任务,task),但不是普通进程,而是 0 号进程的一部分,或者说是内核的一部分。
从执行上来说,它是直接在内核本身内执行,而并不是切换到某个进程执行。
3.5 从 idle task 进入 c-state 管理逻辑
内核切换到 idle task 代码之后,接下来怎么选择 c-state 以及怎么切换过去, 就是算法、架构和对接特定处理器的实现问题了。 我们下面一节来讨论。
如果队列中没有任务,或者任务都是 wait 状态, 内核调度器该做什么呢?取决于处理器提供的能力,
- 如果处理器本身非常简单(特定场景的低成本处理器),没有什么功耗控制能力,调度器就只能执行一些无意义的指令来让处理器空转了;
- 现代处理器都有功耗控制能力,一般都是关闭部分 processor,进入到某种程度的 sleep 状态,实现节能。 但是,中断控制器(interrupt controller)必现保持开启状态。外设触发中断时,能给处理器发信号,唤醒处理器。
实际上,现代处理器有着非常复杂的电源/能耗管理系统。 OS 能预测处理器停留在 idle mode 的时长,选择不同的 low-power modes. 每个 mode 功耗高低、进出耗时、频率等等都是不同的。
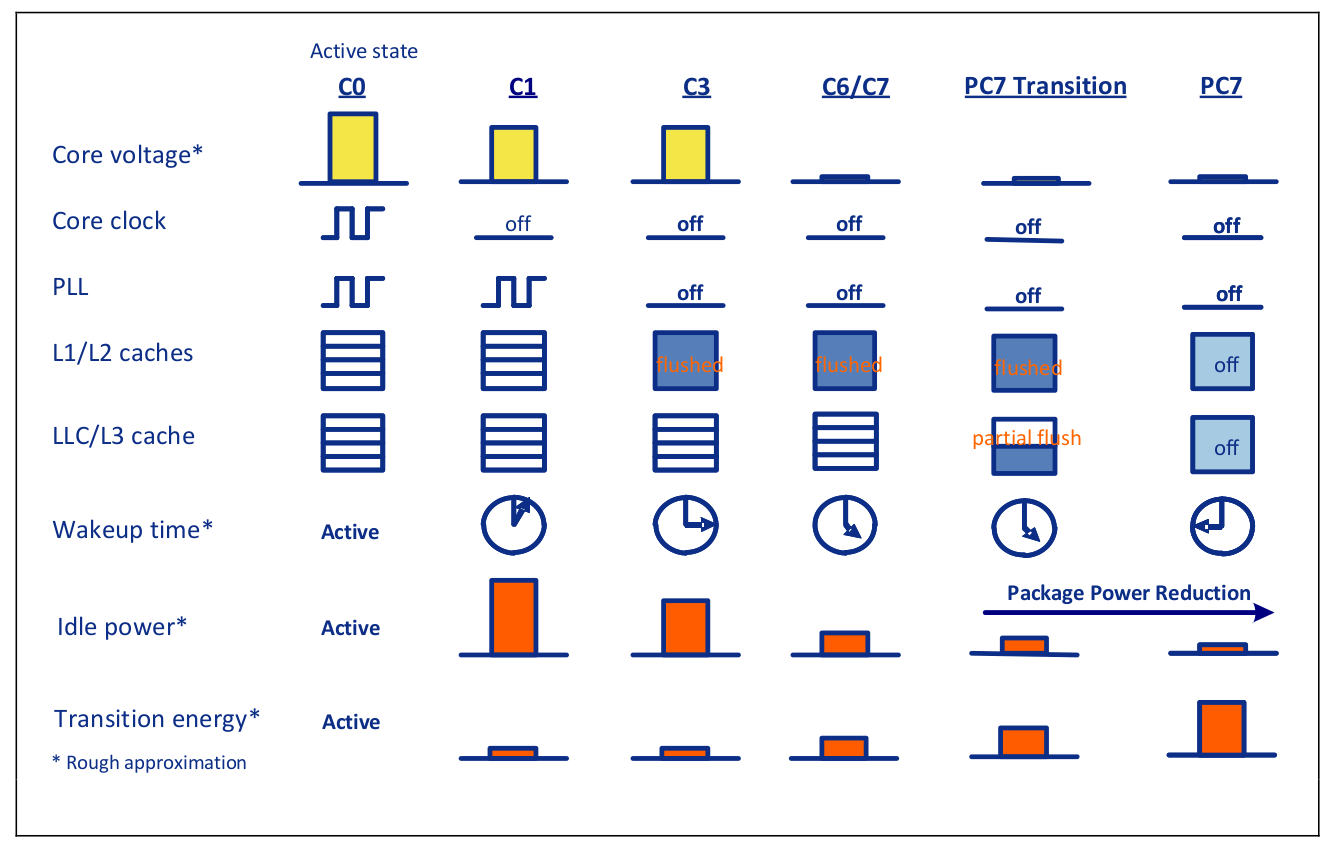
4.1 区分不同的 CPU 空闲级别:引入 c-state (idle state)
为了增强灵活性,引入了 c-state,在处理器 idle 时节能 [7]。
p-states (optimization of the voltage and CPU frequency during operation) and c-states (optimization of the power consumption if a core does not have to execute any instructions) Image Source
4.1.1 ACPI p-states & c-states
ACPI 定义了处理器电源管理的规范,里面有两种状态,
-
Power performance states (
ACPI P states)不同厂商、不同处理器的 p-states 一般都不同。
-
Processor idle sleep states (
ACPI C states)关闭 CPU 部分功能。不同处理器支持的 C-states 可能不同,区别在于能关掉哪些部分。 数字越大,关掉的功能越多,约省电。
4.1.2 C-State 定义
| Mode | Definition |
|---|---|
| C0 | Operational state. CPU fully turned on. |
| C1 | First idle state. Stops CPU main internal clocks via software. Bus interface unit and APIC are kept running at full speed. |
| C2 | Stops CPU main internal clocks via hardware. State in which the processor maintains all software-visible states, but may take longer to wake up through interrupts. |
| C3 | Stops all CPU internal clocks. The processor does not need to keep its cache coherent, but maintains other states. Some processors have variations of the C3 state that differ in how long it takes to wake the processor through interrupts. |
c0比较特殊,是工作状态; 但是工作在什么频率/电压,或者工作在哪个 p-state,是可以配置的,比如为了省电工作在较低的频率和电压;c1是第一个空闲状态,表示 cpu 无事可干时,进入这个状态比 c0 省电。- c2 c3 … 可选的更低功耗 idle 状态,唤醒延迟相应也越大。较深的睡眠状态唤醒时还可能会破坏 L2 cache 数据。
4.1.3 和 p-state 的区别
区别:
- c-state 独立于厂商和处理器,p-state 跟厂商和具体处理器直接相关
- 要想运行在某个 p-state,处理器必现工作在 C0 状态,也就是说处理器得进入工作状态,而不是空闲状态;
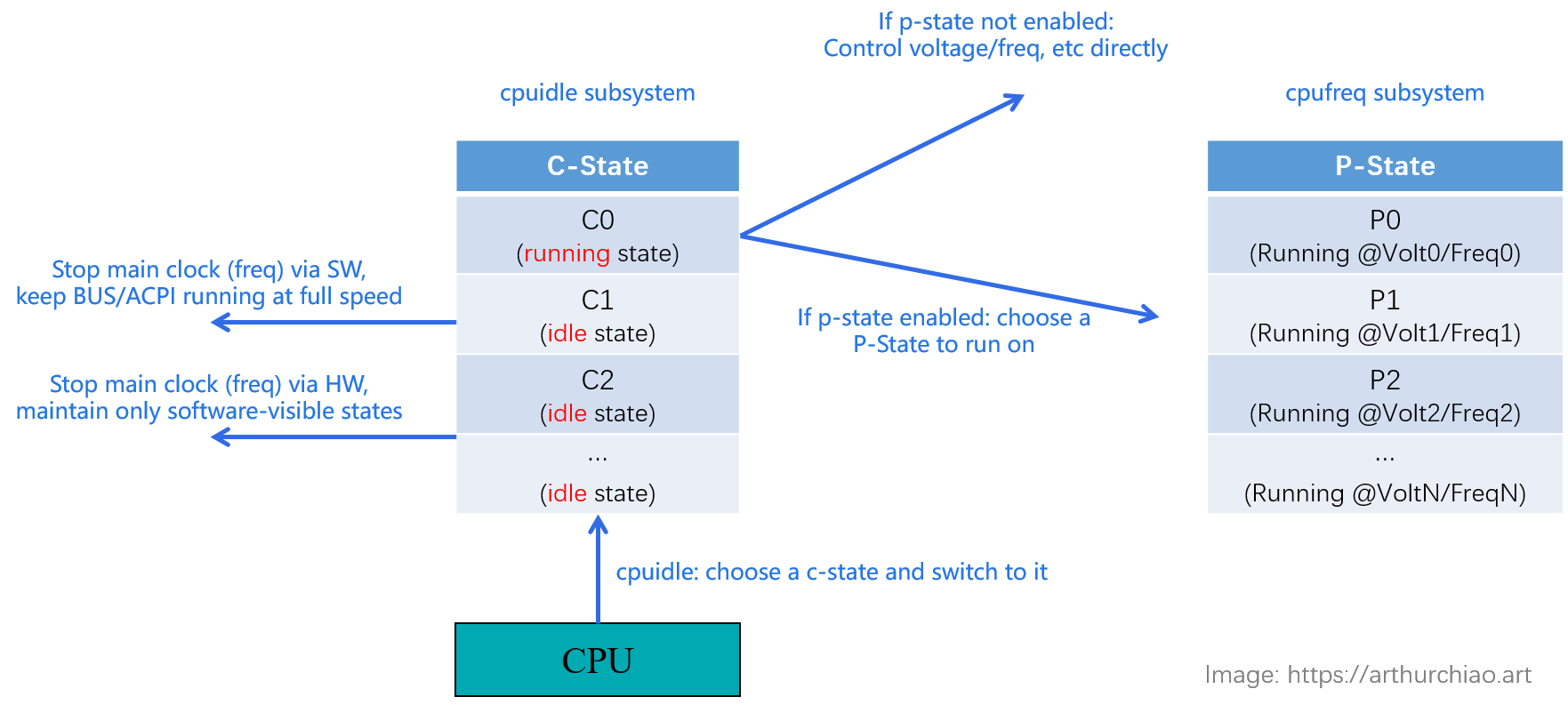
C-States vs. P-States
4.1.4 定义不同 idle 状态 / c-states 的决定因素
每个 idle state 考虑两个参数来描述,
-
target residency(目标驻留时间)硬件能够保证的在这个状态下的最短时间,包括进入该状态所需的时间(可能很长)。
-
(最坏情况下的)
exit latency(退出延迟)从该状态唤醒后开始执行第一条指令所需的最长时间。
4.2 如何选择 c-state:governor + driver
跟 cpufreq 子系统类似,将管理部分封装为一个 governor,有结构体和方法,
通过 driver 实现 governor 的一些方法。
使得架构独立于厂商和处理器。
四种 cpuidle governor:menu, TEO, ladder, haltpoll。
4.2.1 为什么会有这么多 governors?
有两类信息可以影响 governor 的决策。
下一个事件何时到来。分为两种情况:
-
定时器事件。这个是确定的,因为内核控制着定时器(the kernel programs timers),所以 governor 知道何时触发。 在下一个定时器到来之前,就是这个 CPU 所在硬件可以在 idle state 下花费的最长时间,包括进入和退出所需的时间。
-
非定时器事件。CPU 可能随时被非定时器事件唤醒,而且通常不可预测。 governor 只能在 CPU 被唤醒后看到 CPU 实际上空闲了多长时间(这段时间将被称为idle duration),
governor 可以基于以上两种时间,来估计未来的 idle duration。 如何使用这些信息取决于算法,这也是为什么有多个 governor 的主要原因。
4.2.2 governor
menu governor 是 tickless 系统的默认 cpuidle governor。
非常复杂,但基本原理很简单:预测 idle duration,使用预测值进行 c-state 选择。
haltpoll
ladder
teo (Timer Events Oriented)
用于 tickless systems。
跟 menu 一样,永远寻找最深的 idle state。
但算法不同。
kernel-doc: drivers/cpuidle/governors/teo.c
4.2.3 driver
用哪个 cpuidle driver 通常取决于内核运行的平台,例如,有大多数 Intel 平台都支持两种驱动:
intel_idlehardcode 了一些 idle state 信息;acpi_idle从系统的 ACPI 表中读取 idle state 信息。
4.3 实地查看两台 Linux node
下面的信息跟服务器的配置直接相关,我们这里只是随便挑两台看下, 不代表任何配置建议。
4.3.1 Intel CPU node
$ cpupower idle-info
CPUidle driver: intel_idle
CPUidle governor: menu
analyzing CPU 0:
Number of idle states: 4
Available idle states: POLL C1 C1E C6
POLL:
Flags/Description: CPUIDLE CORE POLL IDLE
Latency: 0
Usage: 4927634
Duration: 49239413
C1:
Flags/Description: MWAIT 0x00
Latency: 2
Usage: 954516883
Duration: 1185768447670
C1E:
Flags/Description: MWAIT 0x01
Latency: 10
Usage: 7804
Duration: 7491626
C6 (DISABLED) :
Flags/Description: MWAIT 0x20
Latency: 92
Usage: 0
Duration: 0
可以看到,
- cpuidle driver:
intel_idle - cpuidle governor:
menu -
支持的 idle states 种类:4 种
- POLL:即 C0,无事可做时执行一个轻量级线程,避免处理器进入 C1 状态;
- C1
- C1E
- C6:未启用
此外还提供了每种 idle 状态的延迟、使用率、累积时长等等统计信息。
还可以通过 cpupower monitor 查看每个 CPU 的具体状态分布:
$ cpupower monitor
| Nehalem || Mperf || Idle_Stats
PKG|CORE| CPU| C3 | C6 | PC3 | PC6 || C0 | Cx | Freq || POLL | C1 | C1E | C6
0| 0| 0| 0.00| 0.00| 0.00| 0.00|| 3.10| 96.90| 2692|| 0.00| 96.96| 0.00| 0.00
0| 0| 20| 0.00| 0.00| 0.00| 0.00|| 2.05| 97.95| 2692|| 0.00| 98.04| 0.00| 0.00
0| 1| 4| 0.00| 0.00| 0.00| 0.00|| 0.80| 99.20| 2692|| 0.00| 99.23| 0.00| 0.00
4.3.2 AMD CPU node
第一台 node:
$ cpupower idle-info
CPUidle driver: none # 没有 driver
CPUidle governor: menu
analyzing CPU 0:
CPU 0: No idle states # 没有 idle state,CPU 工作在 idle=poll 模式
第二台 node:
$ cpupower idle-info
CPUidle driver: acpi_idle # acpi_idle driver
CPUidle governor: menu
analyzing CPU 0:
Number of idle states: 2
Available idle states: POLL C1 # 最大睡眠深度 C1
POLL:
Flags/Description: CPUIDLE CORE POLL IDLE
Latency: 0
Usage: 11905032
Duration: 88450207
C1:
Flags/Description: ACPI FFH MWAIT 0x0
Latency: 1
Usage: 3238141749
Duration: 994766079630
$ cpupower monitor | head
| Mperf || Idle_Stats
PKG|CORE| CPU| C0 | Cx | Freq || POLL | C1
0| 0| 0| 18.29| 81.71| 2394|| 0.01| 81.69
0| 0| 64| 13.88| 86.12| 2394|| 0.01| 86.12
第三台 node:
$ cpupower idle-info
CPUidle driver: acpi_idle # acpi_idle driver
CPUidle governor: menu
analyzing CPU 0:
Number of idle states: 3
Available idle states: POLL C1 C2 # 最大睡眠深度 C2
POLL:
Flags/Description: CPUIDLE CORE POLL IDLE
Latency: 0
Usage: 281497562
Duration: 1622947419
C1:
Flags/Description: ACPI FFH MWAIT 0x0
Latency: 1
Usage: 59069668293
Duration: 21144523673762
C2:
Flags/Description: ACPI IOPORT 0x814
Latency: 30
Usage: 9864
Duration: 16089926
$ cpupower monitor | head
| Mperf || Idle_Stats
PKG|CORE| CPU| C0 | Cx | Freq || POLL | C1 | C2
0| 0| 0| 24.83| 75.17| 1886|| 0.00| 75.32| 0.00
0| 0| 64| 22.04| 77.96| 1890|| 0.00| 78.03| 0.00
4.3.3 内核启动日志
内核启动日志说可以看到一些 idle task 相关的信息:
$ dmesg | grep idle
[ 0.018727] clocksource: refined-jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 1910969940391419 ns
[ 0.177760] clocksource: hpet: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 79635855245 ns
[ 0.189880] clocksource: tsc-early: mask: 0xffffffffffffffff max_cycles: 0x1fb633008a4, max_idle_ns: 440795292230 ns
[ 0.227518] process: using mwait in idle threads
[ 0.555478] clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 1911260446275000 ns
[ 0.558415] cpuidle: using governor menu
[ 1.139909] clocksource: acpi_pm: mask: 0xffffff max_cycles: 0xffffff, max_idle_ns: 2085701024 ns
[ 1.194196] ACPI: \_SB_.SCK0.CP00: Found 1 idle states
[ 2.194148] clocksource: tsc: mask: 0xffffffffffffffff max_cycles: 0x1fa32b623c0, max_idle_ns: 440795289684 ns
5.1 解决的问题
c-state 引入的一个问题是:当有任务到来时,从低功耗状态切回运行状态会有一定的延迟, 对于某些应用来说可能无法接受。为了解决这个问题,应用可以通过 Power Management Quality of Service (PM QoS) 接口。
这是一个内核框架,允许 kernel code and user space processes 向内核声明延迟需求,避免性能过低。
5.2 原理
系统会在节能的前提下,尽量模拟 idle=poll processor.max_cstate=1 的效果,
- idle=poll 会阻止处理器进入 idle state;
- processor.max_cstate=1 阻止处理器进入较深的 C-states。
使用方式:
- 应用程序打开
/dev/cpu_dma_latency, 写入能接受的最大响应时间,这是一个int32类型,单位是us; - 注意:保持这个文件处于 open 状态;关闭这个文件后,PM QoS 就停止工作了。
5.3 例子
来自 RedHat Controlling power management transitions:
import os
import os.path
import signal
import sys
if not os.path.exists('/dev/cpu_dma_latency'):
print("no PM QOS interface on this system!")
sys.exit(1)
fd = os.open('/dev/cpu_dma_latency', os.O_WRONLY)
os.write(fd, b'\0\0\0\0')
print("Press ^C to close /dev/cpu_dma_latency and exit")
signal.pause()
except KeyboardInterrupt:
print("closing /dev/cpu_dma_latency")
os.close(fd)
sys.exit(0)
这里写入的是 0,表示完全禁用 c-states。
此外,也可以读写 /sys/devices/system/cpu/cpu<N>/power/pm_qos_resume_latency_us。
最后,我们看一个影响空闲管理性能的东西:timer。
如果我们很关心一件事情的进展,但是出于某些原因,对方不会或无法向我们主动同步进展, 我们该怎么办呢?—— 定期主动去问进展,
- 翻译成计算机术语:轮询;
- 具体到内核,依赖的底层机制:定时器(timer)。
6.1 经典方式:scheduler tick(固定 HZ)
如果一个 CPU 上有多个 runnable task,从公平角度考虑 [12],应该让它们轮流执行。 实现轮流的底层机制就是定时器。
- scheduler tick 是一个定时器,定期触发,不管 CPU 上有没有任务执行;
- timer 触发之后,停止当前任务的执行,根据 scheduling class、优先级等的因素,选出下一个任务放到 CPU 上执行。
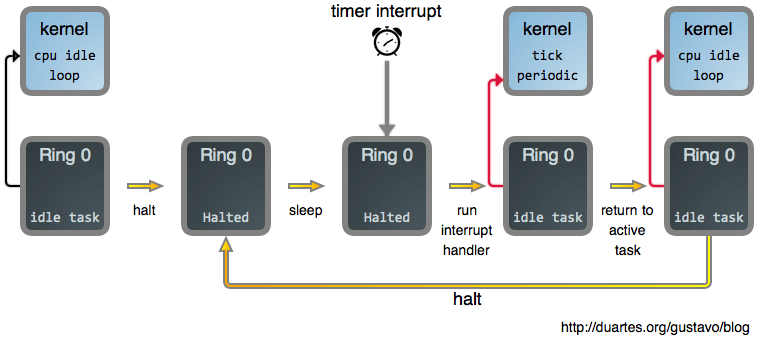
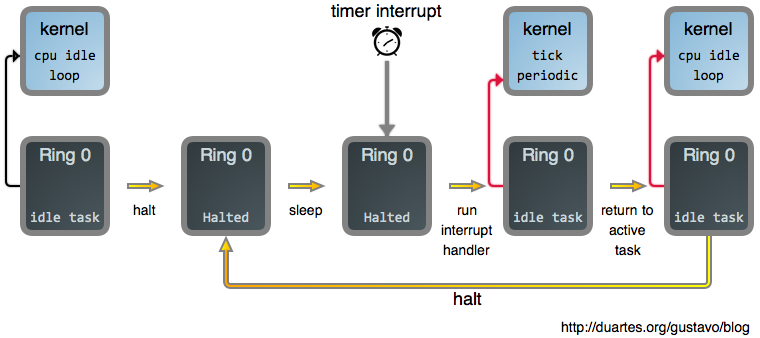{kind=link}
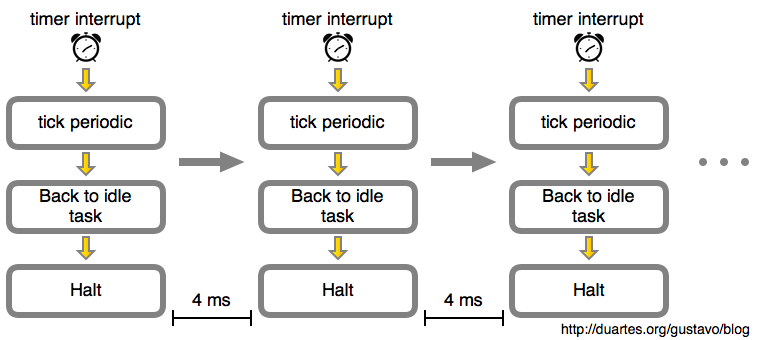{kind=link}
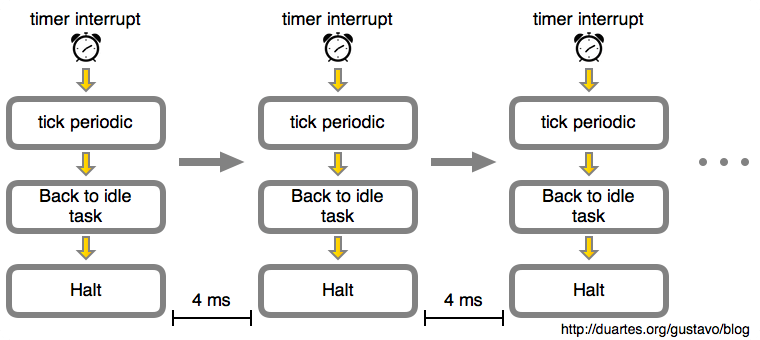
scheduler tick 的触发频率就是系统 HZ,这个是内核编译时指定的,范围是 100~1000,
$ grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=250
即这台机器每秒都要中断 250 次, 从 CPU 空闲时间管理的角度来看,如果 CPU 很空闲,这样频繁触发就很浪费, 增加处理开销。
6.2 改进:tickless mode (nohz)
tickless 模式,也叫 dynamic tick 模式,见内核文档 Documentation/timers/no_hz.rst。
基本原理:CPU 空闲时, 如果内核知道下一个任务何时到来(例如,一个进程设置了 5s 的定时器), 就 关闭或延迟 timer interrupt。
好处是更节能。
编译设置 CONFIG_NO_HZ_IDLE 或启动命令行 nohz=off。
6.3 再改进 adaptive tick
内核文档 NO_HZ: Reducing Scheduling-Clock Ticks。
如果是一个 CPU 密集型的,那跟完全 idle 是类似的,都不希望每 4ms 被打扰一次。
- CPU Idle Time Management, cpuidle kernel doc, 5.15
- What Does An Idle CPU Do, manybutfinite.com, 2014
- what-does-an-idle-cpu-process-do, stackexchange.com
- no hz, kernel doc, 5.15
- The cpuidle subsystem, lwn.net, 2013
- Linux CFS 调度器:原理、设计与内核实现(2023)
- System Analysis and Tuning Guide: Power Management, opensuse.org
- Processor P-states and C-states, thomas-krenn.com
- CPU Performance Scaling, cpufreq kernel doc, 5.15
- Improvements in CPU frequency management, lwn.net, 2016
- CPU idle power saving methods for real-time workloads, wiki.linuxfoundation.org
- Linux CFS 调度器:原理、设计与内核实现(2023)
如有侵权请联系:admin#unsafe.sh