
作者:腾讯科恩实验室
公众号:https://mp.weixin.qq.com/s/mTynxUBNBeiYcAhx4PNJrA
腾讯安全科恩实验室《Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection》论文入选人工智能领域顶级学术会议AAAI-20。研究核心是利用AI算法解决大规模二进制程序函数相似性分析的问题,本文将深入对该论文进行解读,点击链接获取完整论文。https://keenlab.tencent.com/en/whitepapers/Ordermatters.pdf
二进制函数相似性比对演示效果:
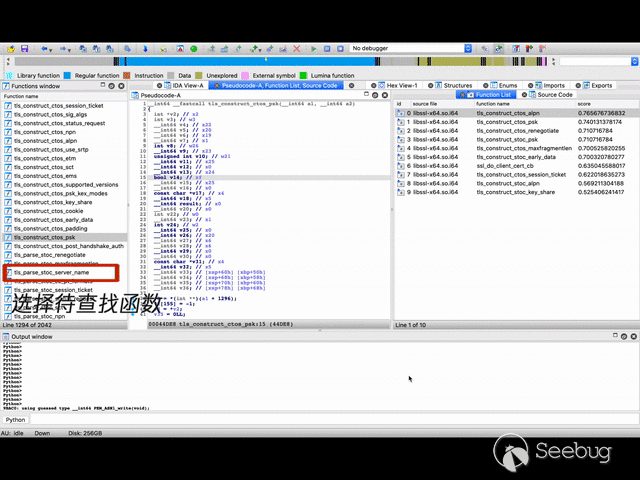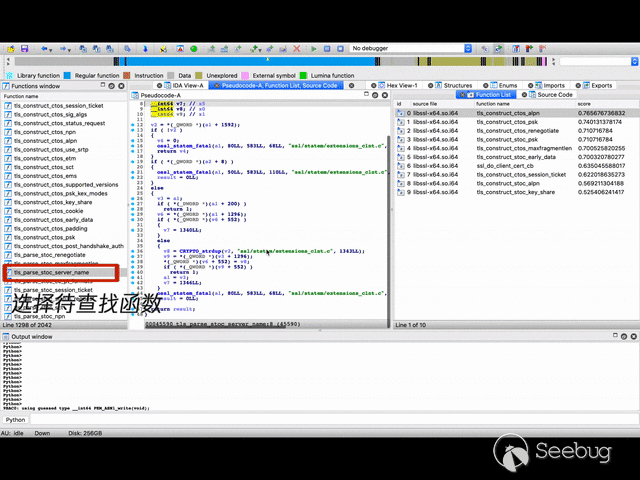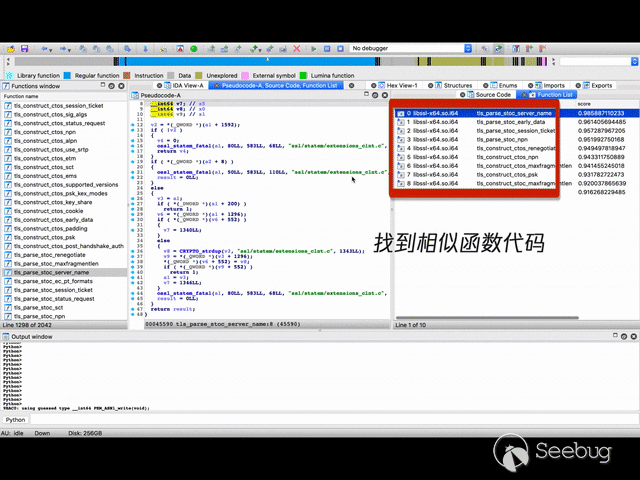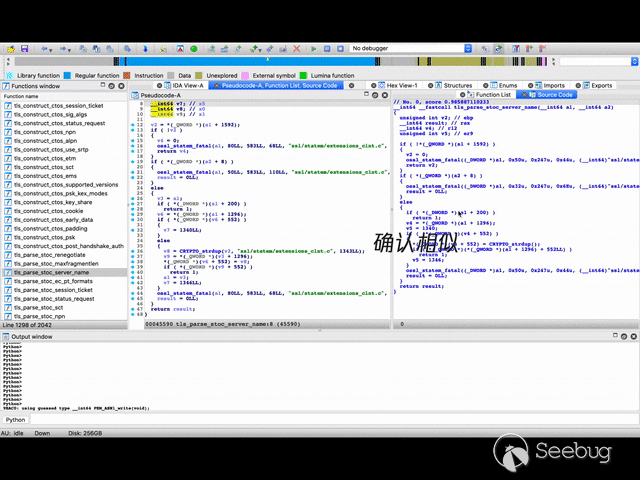
引言 & 背景
二进制代码分析是信息安全领域中非常重要的研究领域之一,其中一类目标是在不访问源代码的情况下检测相似的二进制函数。同一份源代码在不同编译器,不同平台,不同优化选项的条件下所得到的二进制代码是不相同的,我们的任务目标是把同一份源代码所编译出的不同的二进制代码找到。传统算法使用图匹配算法解决此问题,但图匹配算法的速度较慢,且准确率较低。随着近年来深度学习算法的发展,学者们尝试在控制流图(CFG)上使用图神经网络算法,取得了不错的效果。
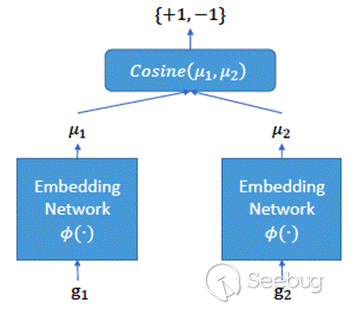
论文[1]提出了名为Gemini的基于图神经网络的算法,它的输入是两个二进制函数的pair,输出是这两个二进制函数的相似度得分。首先,将二进制函数的控制流图作为输入,并使用人工设计的特征提取方法将每个block表示成低维的向量(如图1所示);然后使用Structure2vec算法计算graph embedding;最后使用siamese网络计算相似度得分并使用梯度下降算法降loss训练模型(如图2所示)。与传统方法相比,Gemini的速度和准确率都大幅提升。
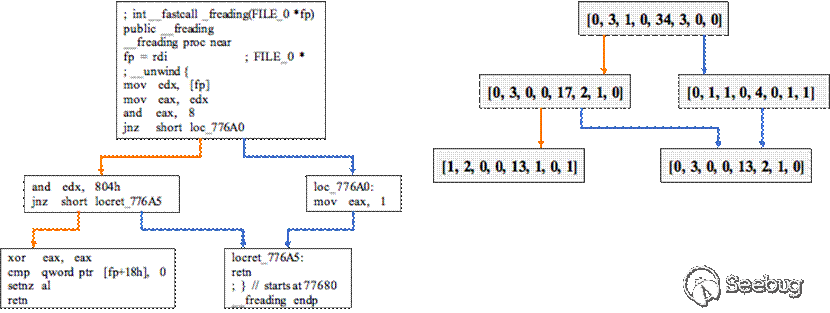
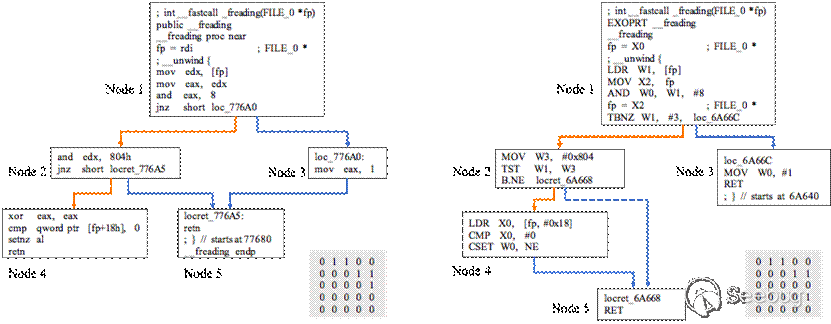
虽然上述方法取得了很大的进步,但仍有一些重要的问题值得研究。一方面,如图1所示,每一个block被表示成一个低维向量,这个特征提取的过程是人工设计的,在Gemini中block特征只有8维向量,这个压缩的过程会损失很多语义信息。另一方面,在二进制代码中节点的顺序是一个很重要的特征,而之前的模型没有设计特殊的算法提取这一特征。图3是函数"_freading"在不同平台x86-64和ARM上编译出的二进制代码的控制流图。这两个控制流图的节点顺序是非常相似的,例如node1都与node2和node3相连,node2都与node4和node5相连,而这种相似性可以体现在它们的邻接矩阵上。经过观察,我们发现许多控制流图的节点顺序变化是很小的。为了解决以上两个问题,我们设计了一种总体的框架,包含semantic-aware模块、structural-aware模块以及order-aware模块。
模型
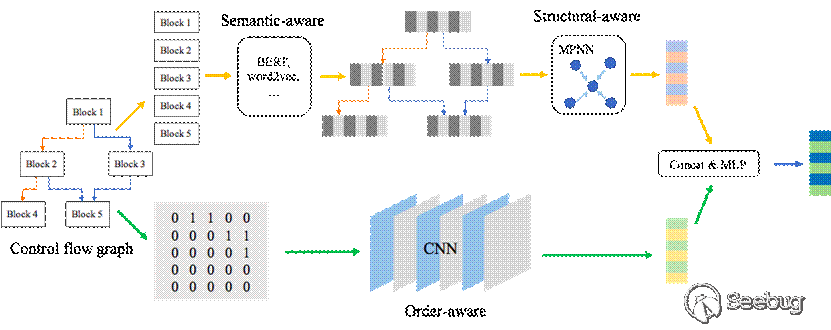
整体结构:模型的输入为二进制代码的控制流图,模型的整体结构如图4所示,包含semantic-aware 模块、structural-aware模块、order-aware模块。在semantic-aware模块,模型将控制流图作为输入,使用BERT[2]对token embedding作预训练,得到block embedding。在structural-aware模块,使用MPNN算法[3]得到graph semantic & structural embedding。在order-aware模块,模型将控制流图的邻接矩阵作为输入,并使用CNN计算graph order embedding。最后对两个向量使用concat和MLP得到最终的graph embedding,如公式1所示。
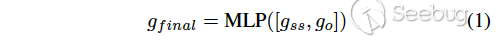
Semantic-aware 模块:在semantic-aware模块,可以使用BERT、word2vec等常用模型提取语义信息。本文中使用BERT对控制流图作预训练,从而获得block的语义信息。BERT原用于NLP领域中,对词语与句子作预训练。我们的任务与NLP任务相似,控制流图的block可以看作句子,block中的token可以看作词语。如图5所示,训练过程中BERT有4个任务:Masked language model(MLM)、Adjacency node prediction(ANP)、Block inside graph(BIG)和Graph classification(GC)。
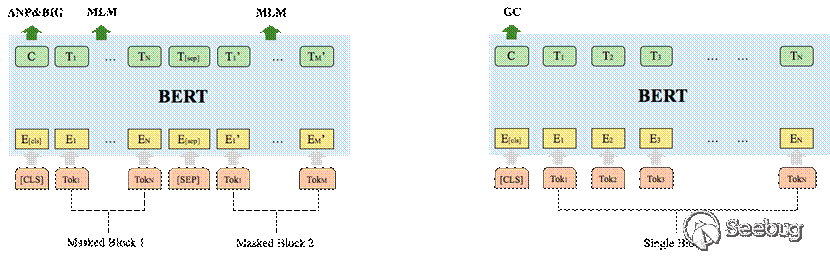
其中MLM和ANP是和BERT的原论文中相似的两个任务。MLM是一个token-level的任务,对block中的token进行mask操作并进行预测,和语言模型的方式相同。ANP任务是一个block-level的任务,虽然控制流图没有NLP领域中的语言顺序,但控制流图是一个有向图,也有节点的拓扑顺序,我们将控制流图中的所有相邻节点提取出来,当作相邻的“句子”。这些相邻的block pair作为ANP任务的正例,并随机选择同图内不相邻的block pair作为负例。
为了获得更多的graph-level的信息,我们加入了两个辅助的graph-level任务BIG和GC。BIG和ANP的方式类似,区别是pair的正负例选择方式不同。BIG任务的目的是让模型判断两个block是否在同一个图中,希望模型可以尽可能地学到此信息,从而对我们的graph-level task有帮助。因此,在BIG任务中同图的block pair为正例,不同图的block pair为负例。GC为graph-level的block分类任务,在我们的场景中,在不同平台、不同编译器、不同优化选项的条件下,得到的block信息有所不同,我们希望模型可以让block embedding中包含这种信息。GC对block进行分类,判断block属于哪个平台,哪个编译器,以及哪个优化选项。
Structural-aware 模块:经过BERT预训练后,使用MPNN计算控制流图的graph semantic & structural embedding。MPNN有三个步骤:message function(M),update function(U)以及readout function(R)。具体步骤如公式2-公式4所示。
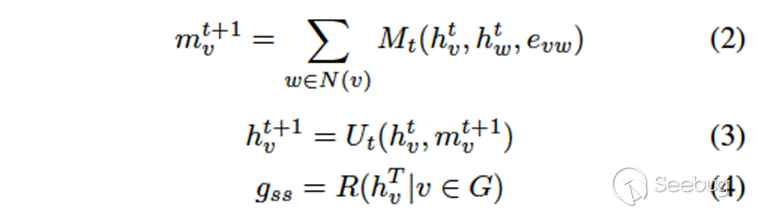
其中G代表整个图,v代表节点,N(v)代表v的邻居节点。在本文的场景中,节点即是控制流图中的block,图即是经过预训练后表示成block向量的控制流图。本文在message步骤使用MLP,update步骤使用GRU,readout步骤使用sum,如公式5-公式7所示。
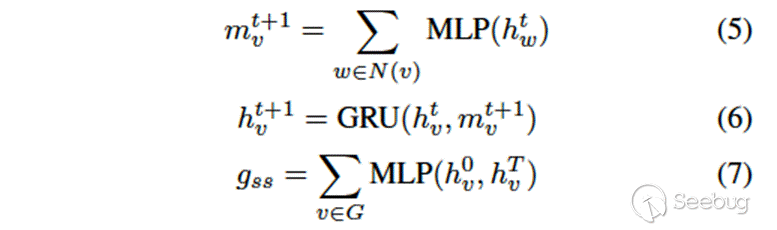
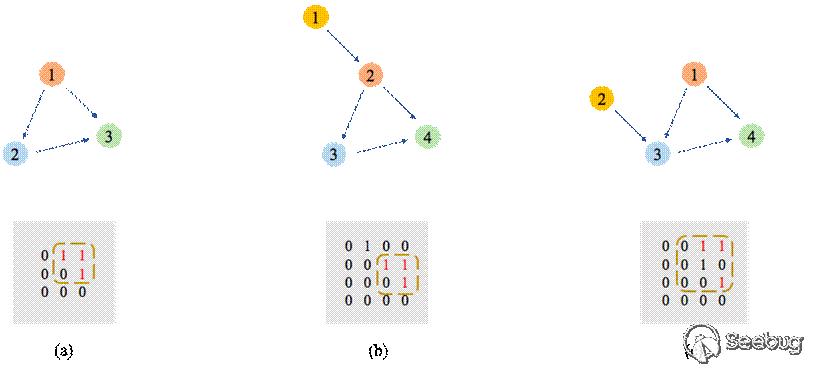
Order-aware 模块:本模块希望可以提取节点顺序的信息,本文中使用的是CNN模型。为什么使用CNN模型呢?首先考虑图6中的三个图(节点中无语义信息),以及它们的邻接矩阵。这三个图非常相似,每个图中都有一个三角形特征(图a的节点123,图b的节点234,图c的节点134),这个特征体现在它们的邻接矩阵中。首先对比图a和图b,与图a相比,图b加入了节点1,节点顺序依次后移一位,但三角形特征中三个节点的顺序还是连续的,这个特征在邻接矩阵中可以看到,这个1-1-0-1的2*2矩阵仍然存在。CNN在训练集中看过很多这种样例后,可以学习到这种平移不变性。再看图c,加入了节点2,打破了原有三角形的节点顺序,但在邻接矩阵中我们可以看到它实际上是把原来的2*2矩阵放大成了3*3矩阵,当我们移除第二行和第二列时,仍然可以得到一个1-1-0-1的2*2矩阵。这与图像中的image scaling类似,CNN在训练集中包含足够多样例的情况下,也是可以学到这种伸缩不变性的。
本文中使用的模型是11层的Resnet结构[4],包含3个residual block,所有的feature map大小均为3*3。之后用一个global max pooling层,得到graph order embedding。在此之前不用pooling层,因为输入的图的大小不同。具体如公式8所示。

实验
本文在两个任务上进行实验。任务1为跨平台二进制代码分析,同一份源代码在不同的平台上进行编译,我们的目标是使模型对同一份源代码在不同平台上编译的两个控制流图pair的相似度得分高于不同源代码pair的相似度得分。任务2为二进制代码分类,判断控制流图属于哪个优化选项。各数据集的情况如表1所示。任务1是排序问题,因此使用MRR10和Rank1作为评价指标。任务2是分类问题,因此使用准确率作为评价指标。
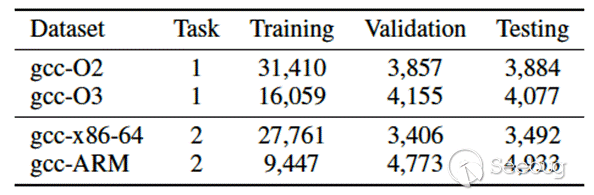
表2和表3分别对应任务1和任务2的实验结果。表中第一个分块是整体模型,包括graph kernel,Gemini以及MPNN模型。第二个分块是semantic-aware模块的对比实验,分别使用了word2vec[5],skip thought[6],以及BERT,其中BERT2是指原始BERT论文中的两个task(即MLM和ANP),BERT4是指在此基础上加入两个graph-level task(BIG和GC)。第三个分块是对order-aware模块的对比实验,基础CNN模型使用3层CNN以及7、11层的Resnet,CNN_random是对训练集中控制流图的节点顺序随机打乱再进行训练,MPNN_ws是去除控制流图节点中的语义信息(所有block向量设为相同的值)再用MPNN训练。最后是本文的最终模型,即BERT+MPNN+Resnet。
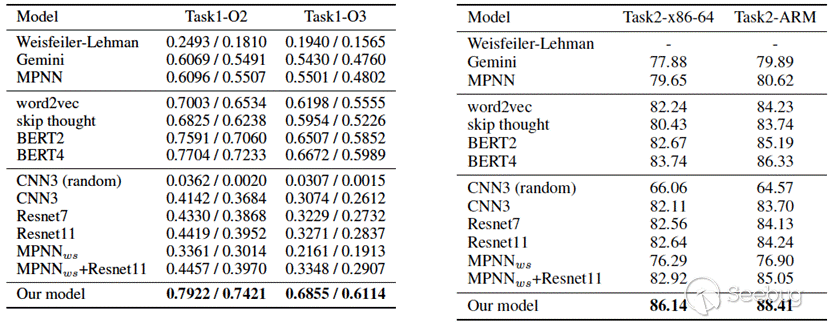
整体结果:本文提出的模型与Gemini模型相比,在任务1和任务2上的评价指标分数均大幅提升。semantic-aware模块使用NLP模型(word2vec,BERT等)均优于使用人工提取的特征。只使用order-aware时模型也取得了不错的效果。与其它所有模型相比,本文提出的模型均取得了更优的效果。
Semantic-aware:只看表中第二个分块,BERT的结果优于word2vec和skip thought,因为BERT能在预训练过程中提取更多的信息。加上BIG和GC任务后的BERT4效果略微提升,说明在预训练过程中加入graph-level的任务有所帮助。图7中是4个控制流图的block(左上,左下,右上,右下),我们使用K-means对预训练后的block embedding进行分类(K-means的类别数定为4),不同的类别颜色不同。从图7中可以看出,同一个控制流图中的block颜色大体相同,不同的控制流图的block的主颜色大体不同。

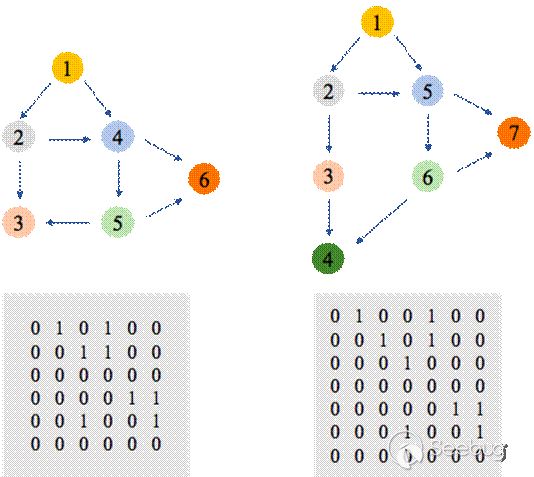
Order-aware:观察表中第三个分块,CNN模型在两个任务上都取得了不错的效果。Resnet11优于Resnet7和CNN3。与MPNN_ws相比,CNN效果更优。随机打乱节点顺序后,CNN模型效果大幅下降,这表示CNN模型确实可以学到节点顺序信息。图8是控制流图pair的例子,这个函数为“ZN12libfwbuilder15RuleElementRGtw13validateC-hildEPNS8FWObjectE“,左边是在gcc&x86-86上编译的控制流图,右边是在gcc&ARM上编译的控制流图。可以看到,左图的节点3在右图中被拆成节点3和节点4,除此之外其它节点的顺序与边的连接方式均相同。经过CNN模型的计算,这两个图的cosine相似度为0.971,排序rank的排名为1。这表明CNN模型可以从邻接矩阵中学到控制流图的节点顺序。
结论
本文提出了一个新的模型,用于解决二进制代码分析的问题。本文的模型中包含semantic-aware模块,structural-aware模块以及order-aware模块。我们观察到语义信息和节点顺序信息都是控制流图重要的特征。我们使用BERT预训练模型提取语义信息,并使用CNN模型提取节点顺序信息。实验结果表明,本文提出的模型与之前最优的模型相比,取得了更好的效果。
参考文献
[1] Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; and Song, D. 2017. Neural network-based graph embedding for crossplatform binary code similarity detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, 363–376. ACM.
[2] Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 .
[3] Gilmer, J.; Schoenholz, S. S.; Riley, P. F.; Vinyals, O.; and Dahl, G. E. 2017. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning-Volume 70 , 1263–1272. JMLR. org.
[4] He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
[5] Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G. S.; and Dean, J. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems , 3111–3119.
[6] R.; Zhu, Y.; Salakhutdinov, R. R.; Zemel, R.; Urtasun, R.; Torralba, A.; and Fidler, S. 2015. Skip-thought vectors. In Advances in neural information processing systems,3294–3302.
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1096/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1096/
如有侵权请联系:admin#unsafe.sh