
Author:w7ay@Knownsec 404 Team
Time: November 20, 2019
Chinese version: https://paper.seebug.org/1078/
QL is an object-oriented query language used to retrieve data from relational database management systems. It supports C/C++, C#, Java, JavaScript, Python and Go.
I have made simple research on finding XSS through JavaScript semantic analysis before, so I have a strong interest in this engine.
Installation
1.Download analyzer program:https://github.com/github/codeql-cli-binaries/releases/latest/download/codeql.zip
The Analyzer program supports the major operating systems such as Windows,Mac and Linux.
2.Download the core library files:https://github.com/Semmle/ql
The library files are open source, and what we're going to do is write QL scripts based on them.
3.Download the latest version of VScode and install the CodeQL extension:https://marketplace.visualstudio.com/items?itemName=GitHub.vscode-codeql
-
With the extension of vscode, we can easily analyze the code
-
Then go to the extension center to configure the parameters
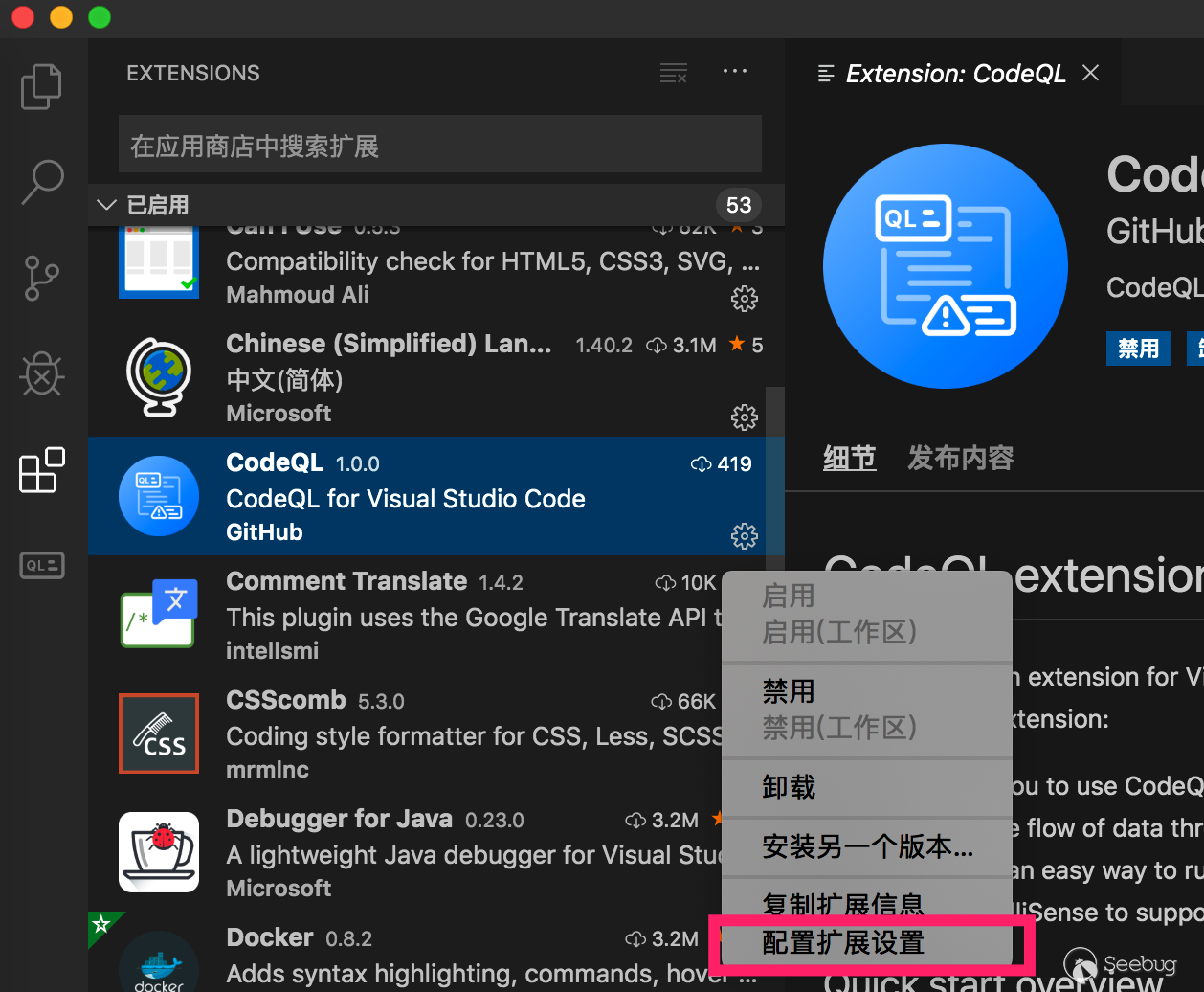
4.
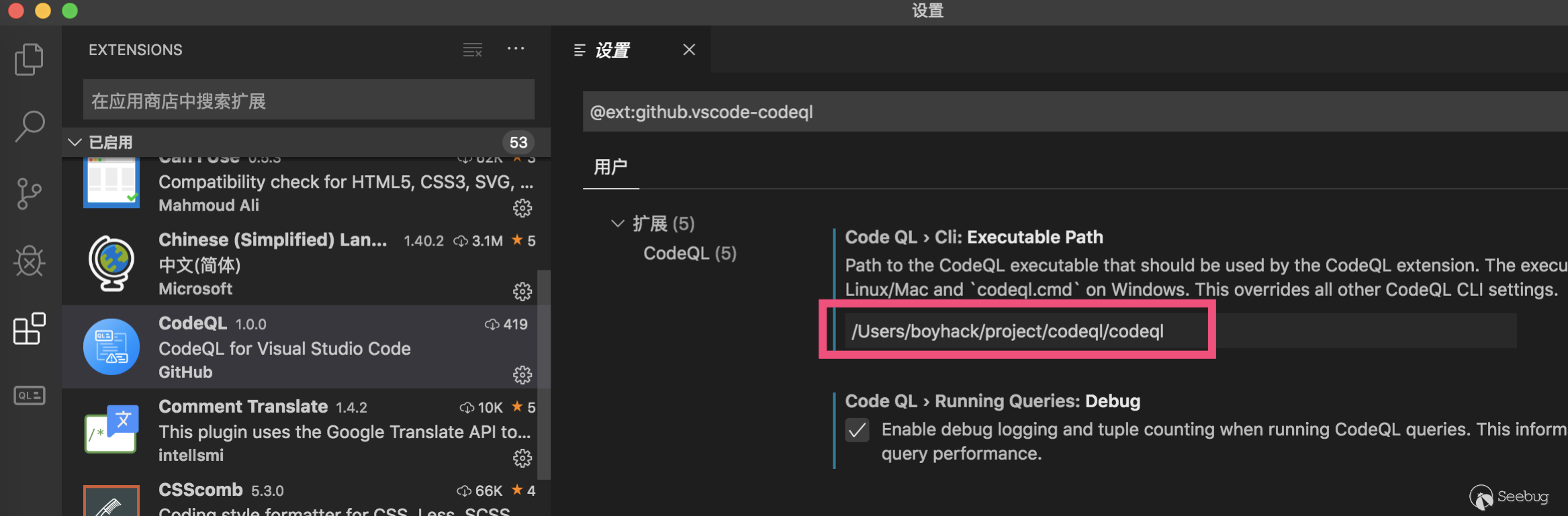
-
Cli to fill in the executable path. Windows can use codeql.cmd
-
Other options by default
Create A Database
Take JavaScript as an example - to build an analysis database is to analyze the source code. To do this, we have to get to the root directory and run the command codeql database create jstest --language=javascript
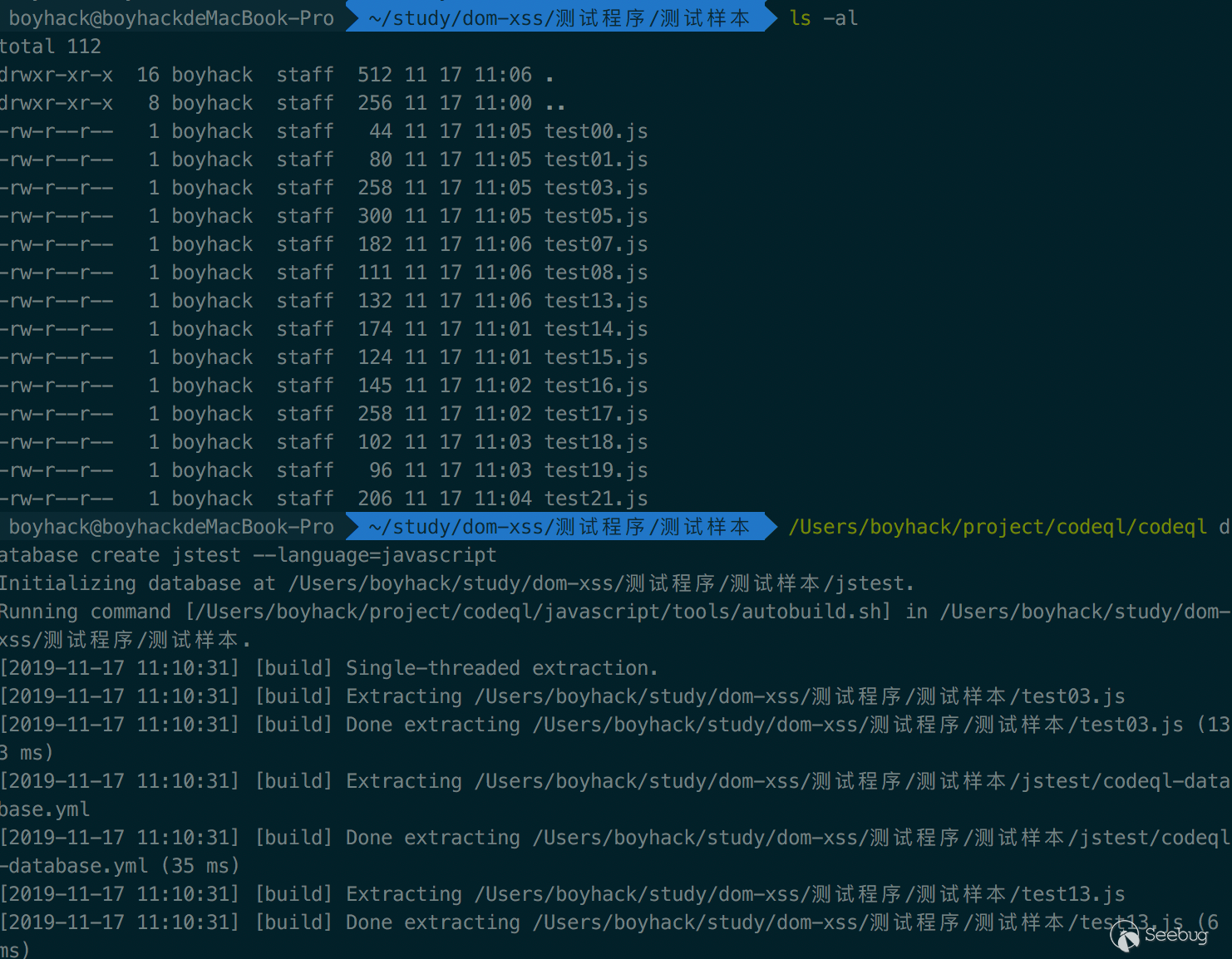
Then a folder named 'jstest' will be created in that directory, which is the database folder.
Then open the previously downloaded ql library file with vscode, add the database file into the ql selection folder, and set it as the current database.
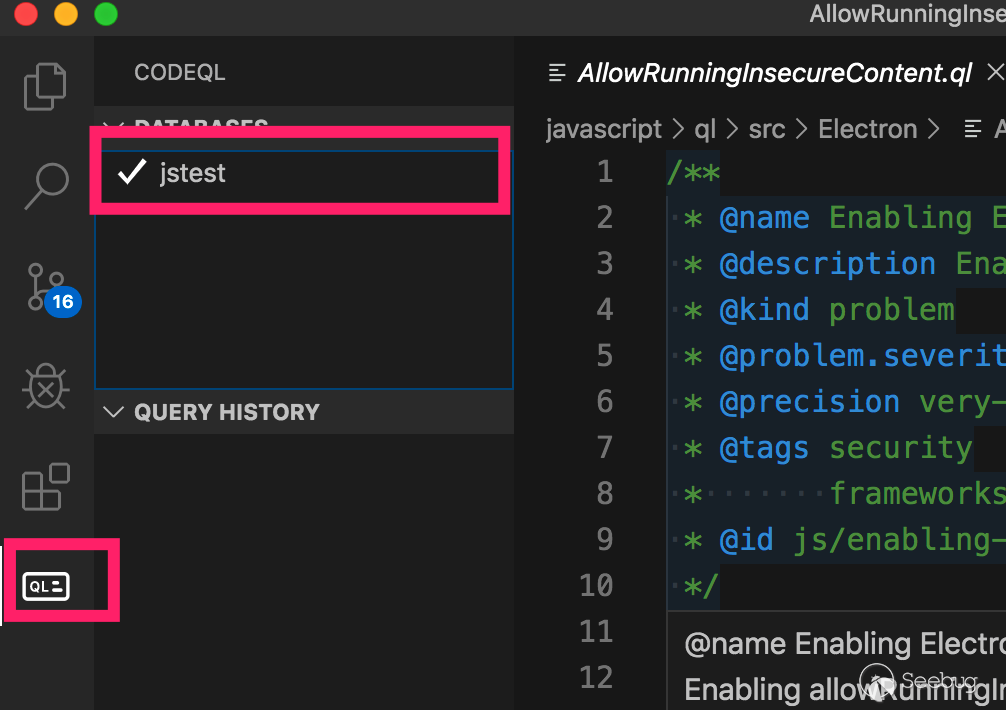
Then create a test.ql in the QL/javascript/ QL/ SRC directory for the QL script. Why do we create a file in this directory? Because import javascript cannot be imported when it is tested elsewhere. In this directory, javascript.qll is the base class library.
The library file basically supports every library used in JavaScript and every defined syntax in any other language.
Print 'Hello world'
Principle of Semantic Analysis Search
At first you may find ql a bit strange. Why is it designed this way? Then I have to talk about my previous research on how to find dom-xss based on JavaScript semantic analysis.
First, a piece of javascript code like this
var param = location.hash.split("#")[1]; document.write("Hello " + param + "!");
The general idea is that we first find the document.write function and trace back with its first argument. If it ends up with location.hashed. Split ("#")[1] then it means we have made it. We can call document.write sink and location.hash.split source. Semantic analysis is the process of finding source from sink (and vice versa, of course).
Based on this, we need to design a tool to understand the code context which the traditional regular search unable to.
The first step is to use pyjsparser to convert the JavaScript code into a syntax tree.
from pyjsparser import parse import json html = ''' var param = location.hash.split("#")[1]; document.write("Hello " + param + "!"); ''' js_ast = parse(html) print(json.dumps(js_ast)) # It outputs in python's dict format, which we convert to json for easy viewing
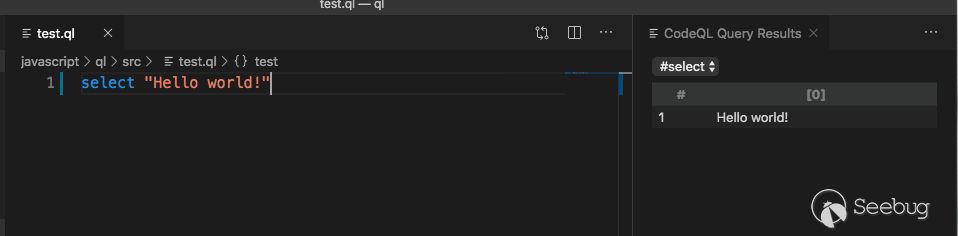
You end up with the following tree structure
Some definitions of tree structure can be referenced:https://esprima.readthedocs.io/en/3.1/syntax-tree-format.html
The variable param is Identifier type, and its initial definition is a MemberExpression expression, which is actually a CallExpression expression. The parameter of CallExpression expression is Literal type, and its specific definition is a MemberExpression expression.
Second, we need to design a recursion to find every expression, every Identifier, every Literal type, and so on. We need to convert the previous document.write into a syntax tree。
{ "type":"MemberExpression", "object":{ "type":"Identifier", "name":"document" }, "property":{ "type":"Identifier", "name":"write" } }
location.hash is the same
{ "type":"MemberExpression", "object":{ "type":"Identifier", "name":"location" }, "property":{ "type":"Identifier", "name":"hash" } }
After we find these sink or source, we need to make forward or reverse retrospective analysis. Retrospective analysis can also encounter many problems, such as how to handle the transfer of objects and parameters. I have wrote an online demo based semantic analysis before.
QL Syntax
Although QL syntax hides the details of the syntax tree, it provides many concepts like class, function to help us find the relevant syntax.
Take the following code as an example
var param = location.hash.split("#")[1]; document.write("Hello " + param + "!");
Now that we have created the database, let's see how to find sink and source respectively, and how to find the relationship between them.
I have also read its document: https://help.semmle.com/QL/learn-ql/javascript/introduce-libraries-js.html My query statements are all based on the syntax tree query. There were a lot of convenient functions but I didn't look it through carefully, so it may have a better method for it .
Query document.write
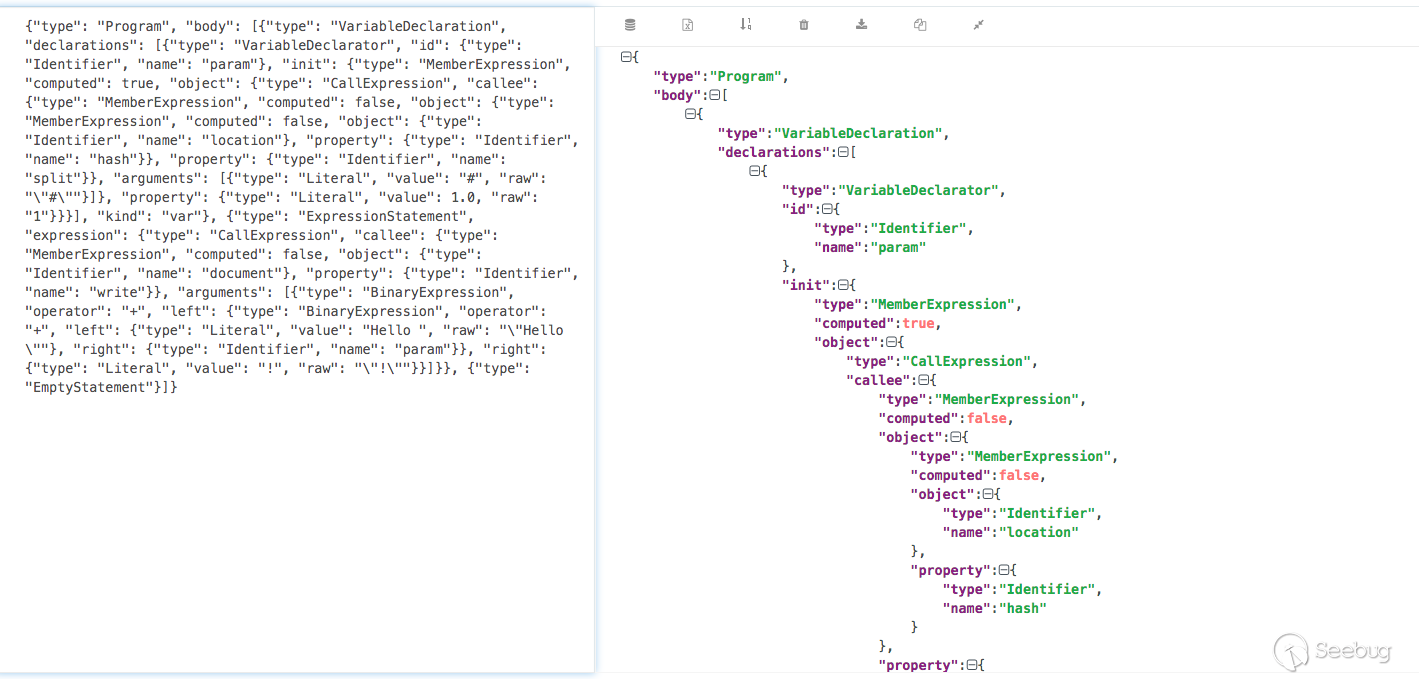
import javascript from Expr dollarArg,CallExpr dollarCall where dollarCall.getCalleeName() = "write" and dollarCall.getReceiver().toString() = "document" and dollarArg = dollarCall.getArgument(0) select dollarArg
Find document.write and output its first argument.
Query location.hash.split
import javascript from CallExpr dollarCall where dollarCall.getCalleeName() = "split" and dollarCall.getReceiver().toString() = "location.hash" select dollarCall
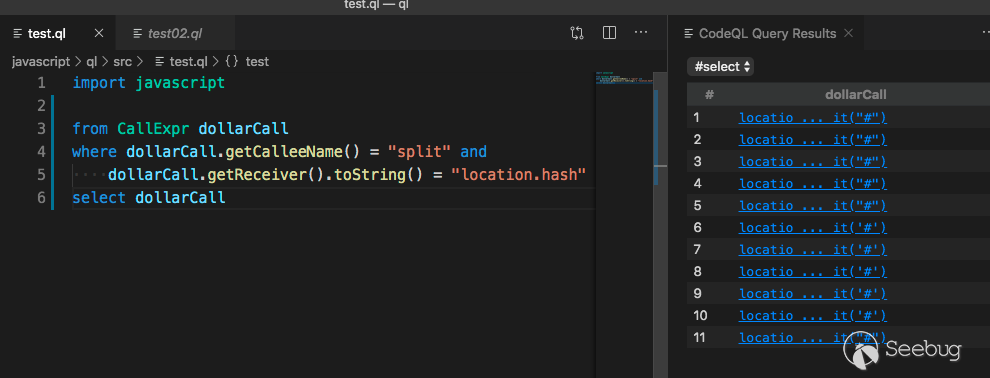
Data Flow Analysis
Then find source from sink. Combine the above statements as the official document says.
class XSSTracker extends TaintTracking::Configuration { XSSTracker() { // unique identifier for this configuration this = "XSSTracker" } override predicate isSource(DataFlow::Node nd) { exists(CallExpr dollarCall | nd.asExpr() instanceof CallExpr and dollarCall.getCalleeName() = "split" and dollarCall.getReceiver().toString() = "location.hash" and nd.asExpr() = dollarCall ) } override predicate isSink(DataFlow::Node nd) { exists(CallExpr dollarCall | dollarCall.getCalleeName() = "write" and dollarCall.getReceiver().toString() = "document" and nd.asExpr() = dollarCall.getArgument(0) ) } } from XSSTracker pt, DataFlow::Node source, DataFlow::Node sink where pt.hasFlow(source, sink) select source,sink
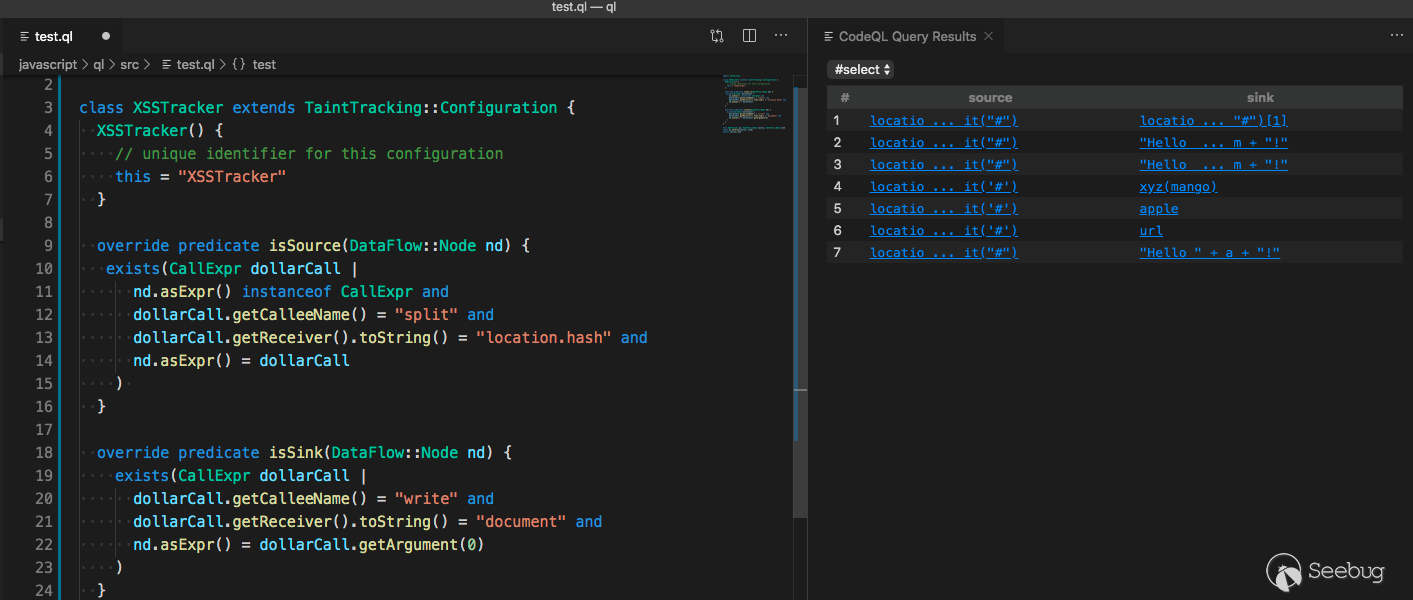
Print source and sink, and you'll find their specific definitions.
Here is the sample we found
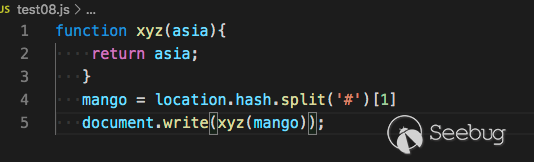
Its backtracking is based on the return value of the function.
Some difficulties may get in our way, and Ql official has provided solutions to solve them. In short, we should refine and improve the ql query code.
There are examples of queries that are not so accurate, and you can try to make them accurate.
var custoom = location.hash.split("#")[1]; var param = ''; param = " custoom:" + custoom; param = param.replace('<',''); param = param.replace('"',''); document.write("Hello " + param + "!");
quora = {
zebra: function (apple) {
document.write(this.params);
},
params:function(){
return location.hash.split('#')[1];
}
};
quora.zebra();
Summary
CodeQL pulls out the syntax tree and provides a way of using code to query code, increasing flexibility based on data analysis. The only regret is that it doesn't provide many rules for vulnerability query and we have to write on our own. It also reminds me of fortify, another powerful semantics-based code auditing tool. There may be some differences if we combine these two together.
Github announced that CodeQL would be used to search for problems in open source projects, and security researchers may use it to do something similar?
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1079/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1079/
如有侵权请联系:admin#unsafe.sh