2023-3-19 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:163 收藏
Published at 2023-03-19 | Last Update 2023-03-19
TL; DR
Modern kernels by default enable a TCP option called Tail Loss Probe (TLP), which actively sends the so-called “probe” packets to achieve TCP fast recovery. A side effect is that a large part of those probe packets is classified as TCP retransmissions (in good quality networks such as data center network), which may be misleading for networking stack monitoring and troubleshooting.
![]()
- TL; DR
- 1 Problem statement
- 2 Kernel stats for TCP retransmission
- 3 Differentiate three types of TCP retransmissions
- 4 Back to question
- 5 Issues and advanced topics
- References
The problem starts from an observation: on monitoring kernel networking stack, we noticed that almost all pods in our on-premises k8s clusters have continuous TCP retransmissions,
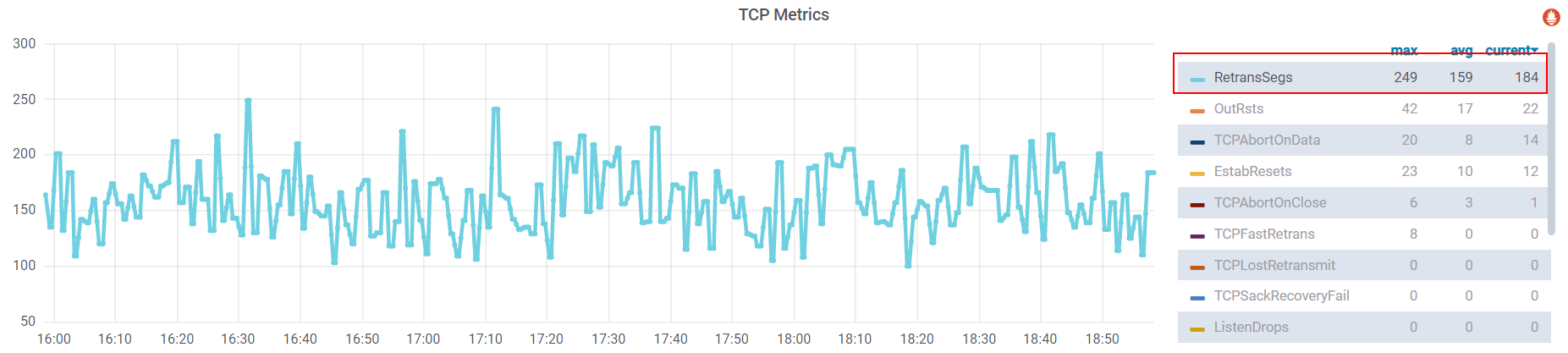
The data source of this metric comes from kernel TCP statistics for this pod (we’ll detail this in the next section).
On capturing the traffic, we noticed that lots of TCP retransmissions are
triggered in a very short time window, e.g. 5ms,
as shown below:
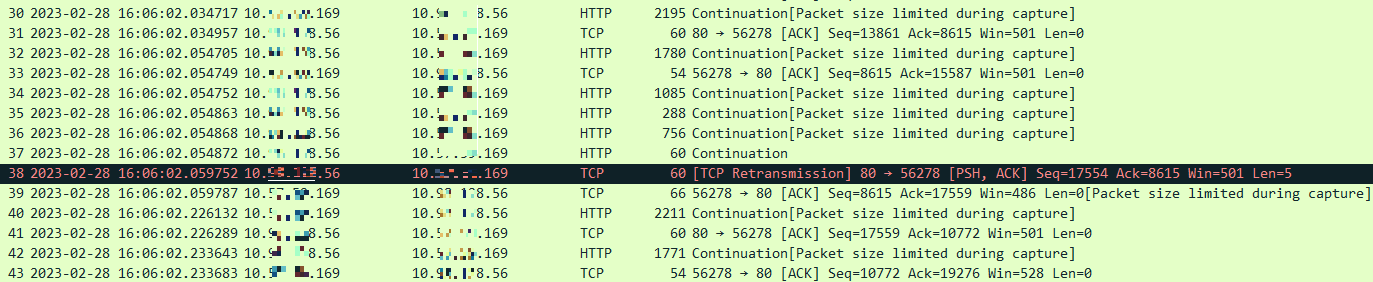
A quick analysis:
#30: client send request to server#31: server ACK #30#32: client send request to server#33: server ACK #32#34 ~ #37: client send request to server-
#38: client retransmit#37, two weird phenomenons:#34 ~ #36not ACK-ed by server either, but the client skipped them and retransmitted the last segment (#38) directly;- Elasped time between
#38and#37/#36/#35/#34is about 5ms.
Besides, we could also conclude that #38 is not fast retransmission,
which should be triggered by duplicated ACKs. Then, according to textbooks,
the minimum waiting interval before retransmitting a packet should be
RTOmin, which is a hard limit (kernel
macro) 200ms for most modern kernels and
doesn’t fit our observation.
So, the question is: what's the mechanism of this retransmission, and how does it work?
To understand this problem, we need some background knowledge of kernel TCP stack.
Linux kernel maintains tons of statistic counters for TCP, among which
several are used for retransmission purposes. Users can get these statistics
via SNMP protocol or /proc file system.
Two kinds of MIBs (Management information base):
TCP_MIB_*: a small set of TCP metrics counters defined by RFC 1213 & RFC 2012;LINUX_MIB_*: an extension defined by Linux, which provides more counters related to the Linux TCP implementation.
2.1 Standard MIBs and /proc/net/snmp
Types definition:
// https://github.com/torvalds/linux/blob/v5.10/include/uapi/linux/snmp.h#L120
// tcp mib definitions
// RFC 1213: MIB-II TCP group
// RFC 2012 (updates 1213): SNMPv2-MIB-TCP
enum {
TCP_MIB_NUM = 0,
TCP_MIB_RTOALGORITHM, /* RtoAlgorithm */
TCP_MIB_RTOMIN, /* RtoMin */
TCP_MIB_RTOMAX, /* RtoMax */
TCP_MIB_MAXCONN, /* MaxConn */
TCP_MIB_ACTIVEOPENS, /* ActiveOpens */
TCP_MIB_PASSIVEOPENS, /* PassiveOpens */
TCP_MIB_ATTEMPTFAILS, /* AttemptFails */
TCP_MIB_ESTABRESETS, /* EstabResets */
TCP_MIB_CURRESTAB, /* CurrEstab */
TCP_MIB_INSEGS, /* InSegs */
TCP_MIB_OUTSEGS, /* OutSegs */
TCP_MIB_RETRANSSEGS, /* RetransSegs */
TCP_MIB_INERRS, /* InErrs */
TCP_MIB_OUTRSTS, /* OutRsts */
TCP_MIB_CSUMERRORS, /* InCsumErrors */
__TCP_MIB_MAX
};
Access these counters from userspace via /proc file system:
$ cat /proc/net/snmp | grep Tcp
Tcp: RtoAlgorithm RtoMin RtoMax MaxConn ActiveOpens PassiveOpens AttemptFails EstabResets CurrEstab InSegs OutSegs RetransSegs InErrs OutRsts InCsumErrors
Tcp: 1 200 120000 -1 22432878 9645244 1320167 4077672 2501 7823669861 9712198857 8493997 10 18640759 5
Note that there are also stats for other protocols in /proc/net/snmp, such as UDP, ICMP, IP.
2.2 Linux extended MIBs and /proc/netstat
The Linux extended MIBs (a fairly long list):
// https://github.com/torvalds/linux/blob/v5.10/include/uapi/linux/snmp.h#L120
/* linux mib definitions */
enum {
LINUX_MIB_NUM = 0,
...
LINUX_MIB_TCPLOSTRETRANSMIT, /* TCPLostRetransmit */
...
LINUX_MIB_TCPFASTRETRANS, /* TCPFastRetrans */
LINUX_MIB_TCPSLOWSTARTRETRANS, /* TCPSlowStartRetrans */
LINUX_MIB_TCPTIMEOUTS, /* TCPTimeouts */
LINUX_MIB_TCPLOSSPROBES, /* TCPLossProbes */
LINUX_MIB_TCPLOSSPROBERECOVERY, /* TCPLossProbeRecovery */
...
__LINUX_MIB_MAX
};
Retrieve corresponding stats from userspace:
$ cat /proc/net/netstat | grep "^Tcp"
TcpExt: SyncookiesSent SyncookiesRecv SyncookiesFailed EmbryonicRsts PruneCalled RcvPruned OfoPruned OutOfWindowIcmps LockDroppedIcmps ArpFilter TW TWRecycled TWKilled PAWSActive PAWSEstab DelayedACKs DelayedACKLocked DelayedACKLost ListenOverflows ListenDrops TCPHPHits TCPPureAcks TCPHPAcks TCPRenoRecovery TCPSackRecovery TCPSACKReneging TCPFACKReorder TCPSACKReorder TCPRenoReorder TCPTSReorder TCPFullUndo TCPPartialUndo TCPDSACKUndo TCPLossUndo TCPLostRetransmit TCPRenoFailures TCPSackFailures TCPLossFailures TCPFastRetrans TCPSlowStartRetrans TCPTimeouts TCPLossProbes TCPLossProbeRecovery TCPRenoRecoveryFail TCPSackRecoveryFail TCPRcvCollapsed TCPDSACKOldSent TCPDSACKOfoSent TCPDSACKRecv TCPDSACKOfoRecv TCPAbortOnData TCPAbortOnClose TCPAbortOnMemory TCPAbortOnTimeout TCPAbortOnLinger TCPAbortFailed TCPMemoryPressures TCPMemoryPressuresChrono TCPSACKDiscard TCPDSACKIgnoredOld TCPDSACKIgnoredNoUndo TCPSpuriousRTOs TCPMD5NotFound TCPMD5Unexpected TCPMD5Failure TCPSackShifted TCPSackMerged TCPSackShiftFallback TCPBacklogDrop PFMemallocDrop TCPMinTTLDrop TCPDeferAcceptDrop IPReversePathFilter TCPTimeWaitOverflow TCPReqQFullDoCookies TCPReqQFullDrop TCPRetransFail TCPRcvCoalesce TCPOFOQueue TCPOFODrop TCPOFOMerge TCPChallengeACK TCPSYNChallenge TCPFastOpenActive TCPFastOpenActiveFail TCPFastOpenPassive TCPFastOpenPassiveFail TCPFastOpenListenOverflow TCPFastOpenCookieReqd TCPFastOpenBlackhole TCPSpuriousRtxHostQueues BusyPollRxPackets TCPAutoCorking TCPFromZeroWindowAdv TCPToZeroWindowAdv TCPWantZeroWindowAdv TCPSynRetrans TCPOrigDataSent TCPHystartTrainDetect TCPHystartTrainCwnd TCPHystartDelayDetect TCPHystartDelayCwnd TCPACKSkippedSynRecv TCPACKSkippedPAWS TCPACKSkippedSeq TCPACKSkippedFinWait2 TCPACKSkippedTimeWait TCPACKSkippedChallenge TCPWinProbe TCPKeepAlive TCPMTUPFail TCPMTUPSuccess
TcpExt: 477 430 80552 695 18077 0 0 0 1873 0 10924422 0 0 0 2460 191860995 154086 1093354 79209 79209 3697245368 750332106 2977467265 0 1215116 0 0 339065 0 903 434 885 16697 1315 92987 0 817 73 3534586 32745 115891 7503473 6197 0 5175 41586 1093375 341 4296177 114 10507201 202560 0 91194 0 0 0 0 0 28 3407557 2 0 0 0 2210026 3498483 2699590 3 0 0 0 0 0 477 0 1280 410803303 559295 0 341 20618 15 0 0 0 0 0 0 0 3637 0 697051 11506 11506 20065 557297 7045525996 911349 16726487 293 11508 25 127 2450 1 1 24 300158 113548680 0 0
Note that these statistics are classified as "TcpExt" (TCP Extension), to distinguish them from the standard RFC SNMP counters.
On Linux, a network tool called netstat can read both the above metric counters
and format the output slightly:
$ netstat -s
Tcp:
22439328 active connections openings
9648211 passive connection openings
1320355 failed connection attempts
4078996 connection resets received
2501 connections established
7826306153 segments received
9715338732 segments send out
8496768 segments retransmited
10 bad segments received.
18645348 resets sent
InCsumErrors: 5
TcpExt:
477 SYN cookies sent
430 SYN cookies received
80552 invalid SYN cookies received
695 resets received for embryonic SYN_RECV sockets
18077 packets pruned from receive queue because of socket buffer overrun
10924894 TCP sockets finished time wait in fast timer
2460 packets rejects in established connections because of timestamp
...
Where
Tcp:section includes counters for SNMP MIBs,TcpExt:section includes counters for Linux extended MIBs.
2.4 Retransmission stats in netstat output
If grep “retrans” from the netstat output, we’ll get several retransmission-related counters:
$ netstat -s | grep -i retrans
238919184 segments retransmited
85904 times recovered from packet loss due to fast retransmit
Detected reordering 616 times using reno fast retransmit
TCPLostRetransmit: 12954572
45666 timeouts after reno fast retransmit
78943926 fast retransmits
3751391 retransmits in slow start
18146 classic Reno fast retransmits failed
918290 SACK retransmits failed
TCPRetransFail: 508
TCPSynRetrans: 8180371
- “segments retransmitted”: total retransmitted segments
- “fast retransmits”: fast retransmission
- “TCPSynRetrans”: retransmission of TCP SYN packets
- …
So, if we’d like to monitor all the retransmissions of a pod, we can use the “segments retransmitted” counter; if we’d like to further distinguish different types of retransmissions, we can track the counters like “fast retransmits” and “TCPSynRetrans”, right?
Before answering this question, let’s first differentiate several major types of TCP retransmissions.
In TCP’s design, a sender will retransmit a packet after it thinks the packet has been lost, this is called lost recovery.
Regarding “how it thinks the packet has been lost”, there are several mechanisms. Let’s start from the easy ones to the hard ones.
3.1 RTO-based retransmission
TCP uses a retransmission timeout mechanism to recover (re-send) lost segments. If an ACK for a given segment is not received in a certain amount of time ( called Retransmission TimeOut, RTO), the segment is resent [RFC6298].
RTO range: [200ms, 120s], per-connection, updated by RTT
By default, RTO is initially initialized as 1 second and will decrease
according to the connection’s smoothed RTT (SRTT). A maximum and minimum RTO
is also specified by kernel constant, which is 200ms and 120s by default.
// include/net/tcp.h
// Initial RTO: 1 second
#define TCP_TIMEOUT_INIT ((unsigned)(1*HZ)) /* RFC6298 2.1 initial RTO value */
// Max and min RTO: 120s and 200ms (1s/5)
#define TCP_RTO_MAX ((unsigned)(120*HZ))
#define TCP_RTO_MIN ((unsigned)(HZ/5))
With kernel 4.13+, user can change the per-connection max/min RTO with BPF, see [1] for example. But, only few advanced users use this functionality.
Initial RTO and backoff
An example from Customize TCP initial RTO (retransmission timeout) with BPF:
$ sudo tcpdump -nn -i enp0s3 host 9.9.9.9 and port 9999
21:26:43.834860 IP 192.168.1.5.53844 > 9.9.9.9.9999: Flags [S], seq 281070166, ... length 0 # +0s
21:26:44.859801 IP 192.168.1.5.53844 > 9.9.9.9.9999: Flags [S], seq 281070166, ... length 0 # +1s
21:26:46.876328 IP 192.168.1.5.53844 > 9.9.9.9.9999: Flags [S], seq 281070166, ... length 0 # +2s
21:26:51.068268 IP 192.168.1.5.53844 > 9.9.9.9.9999: Flags [S], seq 281070166, ... length 0 # +4s
21:26:59.259304 IP 192.168.1.5.53844 > 9.9.9.9.9999: Flags [S], seq 281070166, ... length 0 # +8s
21:27:15.389522 IP 192.168.1.5.53844 > 9.9.9.9.9999: Flags [S], seq 281070166, ... length 0 # +16s
...
On establishing a new connection, the first retransmission timeout (RTO) will be 1s,
and if a retransmitted packet is lost, the subsequent retransmission timeout will be
exponentially backed off (1s -> 2s -> 4s -> ..), until it reaches the maximum allowed timeout value (120s).
However, for any established connection, the RTO will be dynamically adjusted
according to the RTT (round trip time) between the client and server, but the
adjusted result should still be capped by [200ms, 120s] - usually close to
the lower bound (otherwise the network quality would be so bad).
Effective RTO/RTT of a TCP connection: ss -i
You can check the currently effective RTO of a connection with ss:
$ ss -i
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
tcp ESTAB 0 0 10.0.2.15:ssh 10.0.2.2:50077
cubic rto:204 rtt:0.17/0.039 ato:40 mss:1460 pmtu:1500 rcvmss:1460 advmss:1460 cwnd:10 bytes_sent:5433 bytes_acked:5433 bytes_received:83303 segs_out:35 segs_in:101 data_segs_out:25 data_segs_in:74 send 687.1Mbps lastsnd:1187172 lastrcv:1187172 lastack:1187172 pacing_rate 1368.1Mbps delivery_rate 154.2Mbps delivered:26 app_limited busy:12ms rcv_rtt:206.938 rcv_space:60279 rcv_ssthresh:89532 minrtt:0.083
rto:204: current RTO of this connection is204ms;rtt:0.17/0.039: average0.17msand deviation0.039ms;
Drawback
RTO-based retransmission is very simple in concept and easy to understand.
But, as RTO is lower bound by 200ms, each sender has to wait
>= 200ms before retransmitting a packet, which is a fairly long time in the
networking world.
Any optimization? Yes! Fast retransmission.
3.2 Optimization: fast retransmission
As the name shows, fast retransmission would like to trigger retransmissions faster (than RTO-based mechanism). To achieve this, it needs a TCP option called selective ACK (SACK).
Dependency: SACK (Selective ACK)
From RFC 2018:
TCP may experience poor performance when multiple packets are lost from one window of data. With the limited information available from cumulative acknowledgments, a TCP sender can only learn about a single lost packet per round trip time. An aggressive sender could choose to retransmit packets early, but such retransmitted segments may have already been successfully received.
A Selective Acknowledgment (SACK) mechanism, combined with a selective repeat retransmission policy, can help to overcome these limitations. The receiving TCP sends back SACK packets to the sender informing the sender of data that has been received. The sender can then retransmit only the missing data segments.
Rational
The fast retransmit algorithm relies on incoming duplicate ACKs, which indicate that the peer is missing some data. After a required number (three typically) of duplicate ACKs have arrived at the sender, it will retransmit the first unacknowledged segment and continue with a loss recovery algorithm such as the SACK-based loss recovery [RFC6675].
Statistics in netstat output
In the output of cat /proc/net/netstat or netstat -s.
$ netstat -s | egrep -i "(segments retrans|fast retrans)"
8558346 segments retransmited # <-- total retransmited segements
3558751 fast retransmits # <-- included in "segments retransmited" in almost all cases
Kernel code: where the counter is updated
// net/ipv4/tcp_output.c
/* This gets called after a retransmit timeout, and the initially
* retransmitted data is acknowledged. It tries to continue
* resending the rest of the retransmit queue, until either
* we've sent it all or the congestion window limit is reached.
*/
void tcp_xmit_retransmit_queue(struct sock *sk) {
skb_rbtree_walk_from(skb) {
...
if (tp->retrans_out >= tp->lost_out) {
} else if (!(sacked & TCPCB_LOST)) {
if (!hole && !(sacked & (TCPCB_SACKED_RETRANS|TCPCB_SACKED_ACKED)))
hole = skb;
continue;
} else {
if (icsk->icsk_ca_state != TCP_CA_Loss)
mib_idx = LINUX_MIB_TCPFASTRETRANS; // Fast retrans
else
mib_idx = LINUX_MIB_TCPSLOWSTARTRETRANS; // Slow start retrans
}
if (tcp_retransmit_skb(sk, skb, segs)) // Inc total RetransSegs
break;
NET_ADD_STATS(sock_net(sk), mib_idx, tcp_skb_pcount(skb)); // Inc fast/slow-start retrans
}
}
This piece of code handles both fast retransmission and slow-start retransmission. Two steps in sequence:
- Retransmit a packet by calling
tcp_retransmit_skb(), which internally will increase the total retransmission counter; - On retransmission successful, increase the fast retransmission or slow-start retransmission counter.
Summary
Fast retransmission relies on duplicated ACKs and selective ACKs (SACKs). Suitable for “hole” loss (intermediate segments got lost). No improvement for “tail” loss (tail segments got lost).
Any further optimization for tail loss? Yes!
3.3 Optimiaztion: tail loss probe (kernel 3.10+)
An optimization from Google, Inc.
Dependency: SACK
TLP MUST NOT be used for non-SACK connections. SACK feedback allows senders to use the algorithm to infer whether any segments were lost.
https://datatracker.ietf.org/doc/html/draft-dukkipati-tcpm-tcp-loss-probe-01
Rational
Tail Loss Probe (TLP) is a sender-only algorithm to avoid long timeouts (e.g. RTO): if a connection doesn’t received any ACKs for a certain (short) period of time, TLP will retransmit the last segment that's has been sent, or the next segment in txq if possible, this is called loss probe.
Note: the transmitted segment, aka loss probe, can be either a new segment if available and the receive window permits, or a retransmission of the most recently sent segment, i.e., the segment with the highest sequence number.
- When there is tail loss, the ACK from the probe triggers fast recovery.
- In the absence of loss, there is no change in the congestion control or loss recovery state of the connection, apart from any state related to TLP itself.
The major difference from RTO triggered retransmission is that the
"wait period" is farely short: usually several ms.
TLP only modifies the TCP sender, and does not require any TCP options or changes to the receiver for its operation.
sysctl parameter
TLP option can be configured with sysctl, which is enabled by default:
tcp_early_retrans - INTEGER
Tail loss probe (TLP) converts RTOs occurring due to tail losses into fast recovery. Note thatTLP requires RACK to function properly (see tcp_recovery option) Possible values: * 0 disables TLP * 3 or 4 enables TLP Default: 3
Statistics in netstat output
# netstat -s | egrep -i "(segments send out|retrans|TCPLossProbe)"
233432022 segments send out
203858 segments retransmited # <-- total retrans
TCPLostRetransmit: 30599
3056 fast retransmits # <-- fast retrans
8 retransmits in slow start
TCPLossProbes: 150235 # <-- Tail Loss Probe
TCPLossProbeRecovery: 329
TCPSynRetrans: 48347
$ netstat -s | egrep -i "(segments retrans|fast retrans|lossprobes)"
8558571 segments retransmited
3558873 fast retransmits
TCPLossProbes: 7558422
Implementation (patch): 6ba8a3b19e764
Kernel code: where the counter is updated
Call stack, from kernel 5.10:
tcp_send_loss_probe(struct sock *sk)
|-skb = tcp_send_head(sk);
|-if (skb && tcp_snd_wnd_test(tp, skb, mss)) {
| pcount = tp->packets_out;
| tcp_write_xmit(sk, mss, TCP_NAGLE_OFF, 2, GFP_ATOMIC);
| if (tp->packets_out > pcount)
| goto probe_sent;
| }
|
|-__tcp_retransmit_skb(sk, skb, 1))
| |--NET_INC_STATS(sock_net(sk), TCP_MIB_RETRANSSEGS); // RetransSegs++
|
|probe_sent:
|-NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPLOSSPROBES); // TCPLossProbes++
When TLP is triggered,
- If it sends a new packet, only the
LINUX_MIB_TCPLOSSPROBEScounter will be increased; - Otherwise, it will retransmit the last sent segment, so both the
TCP_MIB_RETRANSSEGSandLINUX_MIB_TCPLOSSPROBEScounters will be increased;
Related code:
// net/ipv4/tcp_output.c
bool tcp_schedule_loss_probe(struct sock *sk, bool advancing_rto) {
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
u32 timeout, rto_delta_us;
int early_retrans;
/* Don't do any loss probe on a Fast Open connection before 3WHS finishes. */
if (rcu_access_pointer(tp->fastopen_rsk))
return false;
early_retrans = sock_net(sk)->ipv4.sysctl_tcp_early_retrans;
/* Schedule a loss probe in 2*RTT for SACK capable connections
* not in loss recovery, that are either limited by cwnd or application. */
if ((early_retrans != 3 && early_retrans != 4) ||
!tp->packets_out || !tcp_is_sack(tp) ||
(icsk->icsk_ca_state != TCP_CA_Open &&
icsk->icsk_ca_state != TCP_CA_CWR))
return false;
/* Probe timeout is 2*rtt. Add minimum RTO to account
* for delayed ack when there's one outstanding packet. If no RTT
* sample is available then probe after TCP_TIMEOUT_INIT.
*/
if (tp->srtt_us) {
timeout = usecs_to_jiffies(tp->srtt_us >> 2);
if (tp->packets_out == 1)
timeout += TCP_RTO_MIN;
else
timeout += TCP_TIMEOUT_MIN;
} else {
timeout = TCP_TIMEOUT_INIT;
}
/* If the RTO formula yields an earlier time, then use that time. */
rto_delta_us = advancing_rto ? jiffies_to_usecs(inet_csk(sk)->icsk_rto) :
tcp_rto_delta_us(sk); /* How far in future is RTO? */
if (rto_delta_us > 0)
timeout = min_t(u32, timeout, usecs_to_jiffies(rto_delta_us));
tcp_reset_xmit_timer(sk, ICSK_TIME_LOSS_PROBE, timeout, TCP_RTO_MAX);
return true;
}
Note that TLP timeout in initial patch was no smaller than 10ms, but later patches
have already relaxed that lower bound to 2*RTT, see the code above.
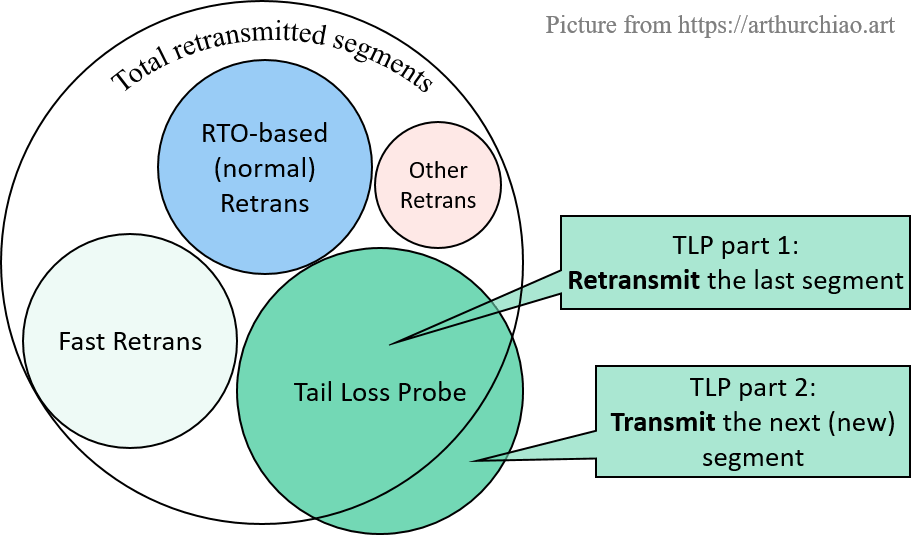
Based on our previous sections, we can draw a counters relationship picture like below:
![]()
Note: some corner cases not counted, such as, some errors in
__tcp_retransmit_skb()will inc RetransSegs but not FastRetrans.
Is there a way to tell the TLP part in "segments retransmited"? Sadly, NO.
3.5 Comparison of 3 types of retransmits
| RTO-based | Fast retransmission | Tail Loss Probe | |
|---|---|---|---|
| Retransmit which packet | the first un-acked | the first un-acked | the last un-acked or the next allowed packet |
| Tigger interval | RTO, [200ms, 120s] |
< 200ms |
typically < 10ms (2*SRTT+delta for kernel 4.1+) |
| Included in “segments retransmited” | Yes | Yes | (a large) Part |
4.1 Will TLP increase the counter of total retransmitted segments?
Case 1 will not, but case 2 will do:
tcp_send_loss_probe(struct sock *sk)
|-skb = tcp_send_head(sk);
|-if (skb && tcp_snd_wnd_test(tp, skb, mss)) {
| pcount = tp->packets_out;
| tcp_write_xmit(sk, mss, TCP_NAGLE_OFF, 2, GFP_ATOMIC); // TLP case 1: send the next (new) segment
| if (tp->packets_out > pcount)
| goto probe_sent;
| }
|
|-__tcp_retransmit_skb(sk, skb, 1)) // TLP case 2: retransmit the last segment
| |--NET_INC_STATS(sock_net(sk), TCP_MIB_RETRANSSEGS); // case 2 : RetransSegs++
|
|probe_sent:
|-NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPLOSSPROBES); // case 1 or 2: TCPLossProbes++
And according to our observation, case 2 is dominant (in data center network).
![]()
The sad news it that we could not exlude the TLP part from “segments retransmitted”.
4.2 Where does the 5ms timeout comes from?
TODO.
Some clues for later reference:
2*RTT + (inflight == 1 ? 200ms : 2ticks)
/* Address-family independent initialization for a tcp_sock.
*
* NOTE: A lot of things set to zero explicitly by call to
* sk_alloc() so need not be done here.
*/
void tcp_init_sock(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
tp->out_of_order_queue = RB_ROOT;
sk->tcp_rtx_queue = RB_ROOT;
tcp_init_xmit_timers(sk);
void tcp_init_xmit_timers(struct sock *sk)
{
inet_csk_init_xmit_timers(sk, &tcp_write_timer, &tcp_delack_timer, &tcp_keepalive_timer);
hrtimer_init(&tcp_sk(sk)->pacing_timer, CLOCK_MONOTONIC, HRTIMER_MODE_ABS_PINNED_SOFT);
tcp_sk(sk)->pacing_timer.function = tcp_pace_kick;
hrtimer_init(&tcp_sk(sk)->compressed_ack_timer, CLOCK_MONOTONIC, HRTIMER_MODE_REL_PINNED_SOFT);
tcp_sk(sk)->compressed_ack_timer.function = tcp_compressed_ack_kick;
}
static void tcp_write_timer(struct timer_list *t)
{
struct inet_connection_sock *icsk = from_timer(icsk, t, icsk_retransmit_timer);
struct sock *sk = &icsk->icsk_inet.sk;
bh_lock_sock(sk);
if (!sock_owned_by_user(sk)) {
tcp_write_timer_handler(sk);
} else {
/* delegate our work to tcp_release_cb() */
if (!test_and_set_bit(TCP_WRITE_TIMER_DEFERRED, &sk->sk_tsq_flags))
sock_hold(sk);
}
bh_unlock_sock(sk);
sock_put(sk);
}
/* Called with bottom-half processing disabled. Called by tcp_write_timer() */
void tcp_write_timer_handler(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
int event;
if (((1 << sk->sk_state) & (TCPF_CLOSE | TCPF_LISTEN)) ||
!icsk->icsk_pending)
goto out;
if (time_after(icsk->icsk_timeout, jiffies)) {
sk_reset_timer(sk, &icsk->icsk_retransmit_timer, icsk->icsk_timeout);
goto out;
}
tcp_mstamp_refresh(tcp_sk(sk));
event = icsk->icsk_pending;
switch (event) {
case ICSK_TIME_REO_TIMEOUT:
tcp_rack_reo_timeout(sk);
break;
case ICSK_TIME_LOSS_PROBE:
tcp_send_loss_probe(sk);
break;
case ICSK_TIME_RETRANS:
icsk->icsk_pending = 0;
tcp_retransmit_timer(sk);
break;
case ICSK_TIME_PROBE0:
icsk->icsk_pending = 0;
tcp_probe_timer(sk);
break;
}
out:
sk_mem_reclaim(sk);
}
5.1 SYN retransmits
Traced with an independent counter, can be seen in netstat output.
5.2 k8s/cadvisor and pod metrics
kubelet collects these TCP counters for pods via cadvisor, such as the TLP counter.
- Customize TCP initial RTO (retransmission timeout) with BPF
- Tail Loss Probe (TLP): An Algorithm for Fast Recovery of Tail Losses, IETF draft, 2013
- tcp: Tail loss probe (TLP), kernel patch, 2013
- tcp: TLP loss detection (patch 2), kernel patch, 2013
- Change TLP timeout to
2*SRTT+delta, tcp: adjust tail loss probe timeout, kernel patch, 2017
如有侵权请联系:admin#unsafe.sh