阅读: 35
一、概述
随着机器学习模型在各个领域的应用任务变得复杂,模型的训练对计算能力和数据集的质量提出了更高的需求,这也阻碍了个人用户自己训练大型复杂的神经网络。在这种困境下,出现了以联邦学习为代表的新的训练模式。
联邦学习下,参与训练的用户能够操纵本地模型的训练过程,并对最终的聚合模型产生影响。当用户中出现恶意的攻击者时,攻击者可能通过后门攻击、数据投毒等攻击方式劣化模型的性能。
作者提出一种新的训练阶段攻击,叫做模型劫持攻击(Model hijacking attack)[1]。在这种攻击下,攻击者设定一个与目标模型原任务不同的任务,通过数据投毒劫持该目标模型,在模型拥有者没有发觉的情况下,让目标模型成功执行攻击者设定的任务。
模型劫持攻击有很强的隐蔽性,然而一旦攻击成功,如果攻击者选择劫持目标模型以提供某种非法服务,模型拥有者可能因此承担一些法律风险。攻击也会导致作为API的黑盒模型从私有变为公用,攻击者无需付费就可以使用模型来实现自己的任务,损害了模型提供者的经济利益。
二、模型劫持攻击
- 模型劫持攻击的实施过程
在模型劫持的过程中,伪装数据集是关键。该方法引入一个伪装器,经过训练后,伪装器可以生成满足要求的伪装数据,伪装数据被用于模型的训练。攻击实施过程主要包含两个步骤:
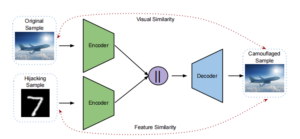
1)设计伪装器,如下图1所示:

图 1 伪装器
将原始样本与劫持样本(攻击者想要进行分类的样本)进行编码,连接编码器的输出并交给解码器,解码器生成伪装样本作为投毒样本。伪装样本在视觉上与原始样本保持一致,在特征上又接近劫持样本。可以看出该伪装器是模型无关的。
在伪装器的训练方法上,该文章设计了两种方案:
方案一:Chameleon attack
伪装器的目标函数包含了两个损失函数,即视觉损失和语义损失,这两个损失函数分别用于约束伪装样本在视觉上与原始数据保持一致、在语义特征上与劫持数据接近。
视觉损失定义为:

语义损失定义为:
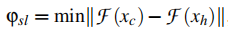
这种攻击方案更擅长劫持数据与原始数据分布差异较大的场景。实验表明,原始数据
集为CIFAR-10和CelebA、劫持数据集为MNIST时,模型在MNIST分类任务上的准确率达到了99%,而在CelebA分类任务与CIFAR-10分类任务上的表现分别是精度无损失和精度下降不到1%。
方案二:Adverse Chameleon attack
解决了 Chameleon在面对原始数据集与劫持数据集分布接近时表现不好的问题。这种方案在Chameleon的基础上添加了一个损失,该损失会增大伪造样本与原始样本之间的特征差距,从而提高伪造样本的攻击效果。损失定义如下:

这种攻击方案擅长原始数据集与劫持数据集都很复杂且相似度较高的场景。
使用方案一生成的部分伪装样本图2中(d)(e)所示:

图 2 伪装样本示例
从图中可以看出,伪装样本上还是能看到一些模糊的类似水印的图案,但是作为第一次提出模型劫持攻击的文章,可以将重点放在这篇文章的攻击设计思路上。
2)投毒和训练
如下图3所示,训练好伪装器后,进行数据投毒,并训练目标模型:

图 3 模型劫持中的数据投毒和训练过程
攻击者将 Hijackee 数据(Hijackee 数据集和原始数据集是同分布的)和劫持数据作为输入交给伪装器,伪装器输出伪装数据并投毒到原始数据中,使用原始数据和伪装数据一起训练目标模型。模型训练结束后,劫持完成。
- 模型劫持后,攻击者如何实现自己的任务
以分类任务为例,攻击者要实现的劫持任务与目标模型执行的原始任务不同,现在攻击者想要利用目标模型对自己的数据集进行预测。如图4所示,模型被劫持(投毒并训练)后:

首先,攻击者在原始任务的标签label、劫持任务的标签label’之间建立映射,以便在得到模型预测类别后可以映射回劫持任务的标签;
随后,攻击者将自己的数据集进行伪装,使其在视觉上和目标模型使用的原始数据集没有差异,在语义上又保持了自己数据集的特征;
接着,攻击者用伪装数据查询模型,并得到模型输出的类别label;
最后根据label和label’之间的映射关系,得到攻击者自己分类任务的标签。
三、实验效果
- 实验一:模型可用性和攻击成功率
这部分实验采用了两个评价指标:
1、Utility:目标模型在干净原始数据集上的准确率,越高越好。
2、Attack Success Rate:伪装数据在目标模型上的攻击准确率,越高越好。

图 5 模型可用性和攻击成功率实验
实验结果如上图5所示,能够得到结论:(1)伪装后的劫持方案在模型可用性上的影响是可忽略的,在目标模型在干净样本上的准确率和没有受到攻击的模型表现几乎一样。(2)伪装操作对劫持攻击成功率几乎无影响。
- 实验二:攻击隐蔽性
经过伪装后(Chameleon)的数据,从视觉上看,要比不经伪装的劫持攻击(Naïve)更接近干净数据(Original),视觉上几乎达到了“属于同一分布”。采用t-SNE降维后的可视化数据分布如下图6所示:

图 6 攻击隐蔽性实验
四、总结
- 模型劫持攻击与其他攻击的对比
在AI安全领域,一些攻击方式和模型劫持攻击存在相似的特性,例如,后门攻击也会避免影响到模型本身的可用性,对抗样本也要求经过改动的样本中在视觉上不易被察觉。模型劫持攻击与这些攻击方式的对比如表1所示:
表1 模型劫持攻击和其他攻击的对比

- 模型劫持攻击的特点与优缺点
模型劫持攻击发生在模型的训练阶段,有两个重要特点:
1、在视觉上,伪装样本要和目标模型原本的训练数据看起来属于相同的分布;
2、攻击不会影响到目标模型在原始任务上的效果。
这两个特点使得模型劫持具有较强的隐蔽性,不易被模型拥有者察觉到攻击的存在。此外,模型劫持不需要攻击者自己去训练和维护一个模型,省去了这部分开销。而模型劫持攻击仅依靠数据投毒来实现,能够进行数据投毒的场景都有实施模型劫持攻击空间。
尽管具备上述优点,作为最近提出的攻击手段,模型劫持攻击尚未在商业机器学习模型上证明其攻击效果。而文章中生成的伪装样本在视觉上与原始样本还不够贴近,需要后续研究和设计更合适的优化算法。
参考文献
[1] Salem A, Backes M, Zhang Y. Get a Model! Model Hijacking Attack Against Machine Learning Models[J]. arXiv preprint arXiv:2111.04394, 2021.
[2] Battista Biggio, Blaine Nelson, and Pavel Laskov. Poisoning Attacks against Support Vector Machines. In International Conference on Machine Learning (ICML).icml.cc / Omnipress, 2012. 1, 3, 13
[3] Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Grag. Badnets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. CoRR abs/1708.06733, 2017. 1, 4, 13
[4] Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
[5] Gamaleldin F. Elsayed, Ian J. Goodfellow, and Jascha Sohl-Dickstein. Adversarial Reprogramming of Neural Networks. In International Conference on Learning Representations (ICLR), 2019. 13
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。