2022-8-6 08:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:76 收藏
Published at 2022-08-06 | Last Update 2022-08-06
TL; DR
Try to answer several quick questions with a long post:
- On creating a pod in Kubernetes, if
somaxconnis not specified, what the default value will be, and who will set it? - If changing node’s sysctl settings, will they be propagated to pods?
- Are all sysctl parameters are equal in terms of initialization and propagation?

- TL; DR
- 1 Background
- 2 Dig inside
- 2.1
kube-apiserver -> kubelet - 2.2
kubelet -> dockerd - 2.3 Skip
k8s/kubelet/cni: create container right fromdocker - 2.4 Skip
docker: create container right fromcontainerd - 2.5 Skip
containerd: create container right fromrunc - 2.6 Skip
runc: create container netns right fromiproute2 - 2.7 Skip
iproute2: locate the kernel code of init new netns
- 2.1
- 3 Conclusion & discussion
- References
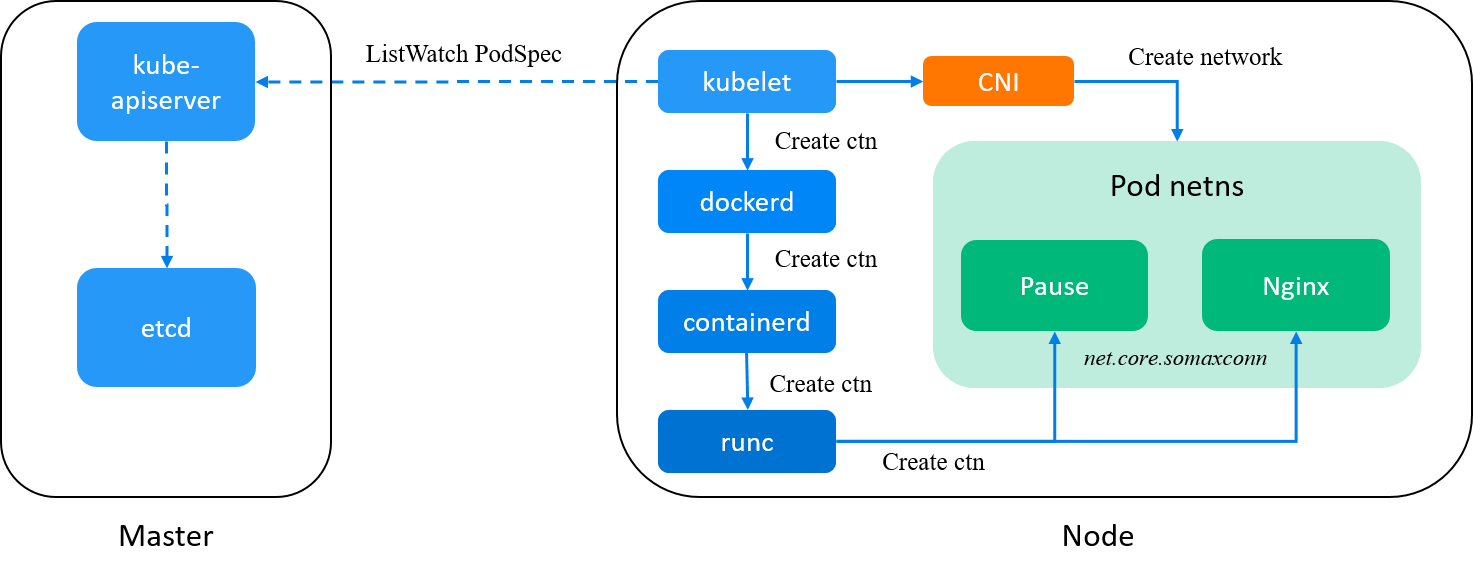
1.1 Journey of components when creating a pod
In our environment, when creating a pod in Kubernetes (e.g. with k apply -f pod.yaml),
the request will go through the following components in sequence,
kube-apiserver -> kubelet -> dockerd -> containerd (-> containerd-shim) -> runc,
as shown below:
Fig. Journey of components when creating a pod in Kubernetes
A few words about each component:
-
kube-apiserver: accept and validate the pod creation request; -
kubelet: watchkube-apiserver, on receiving a new Pod spec, calldockerdto create containers for the Pod (and later call CNI plugins to init pod network); -
dockerd: a user-facing wrapper overcontainerd, which just delegate most jobs tocontainerd;Actually,
dockercan be removed from the stack, which results in a simpler chain:kube-apiserver -> kubelet -> containerd -> runc. But for historical reasons, we still have it in place now (may remove it later though). -
containerd: a less user-facing container manager;containerd: a daemon that manages the complete container lifecycle on the host: creates, starts, stops containers, pulls and stores images, configures mounts, networking, etc. [1]ctr: the command line tool ships withcontainerd, which has similar commands and options asdockerdoes, we’ll see it later.containerd-shim: a child process of containerd that serves a single container and takes care of the container lifecycle and exposes its functions to containerd through containerd-shim API. [2]
-
runc: the eventual container runtime in using, which creates containers by Linux namespaces; -
cni-plugin: this is a binary, by default located at/opt/cni/bin/, and will be called bykubeletafterpausecontainer is created, which is responsible for allocating IP addresses, configuring network interface, … for the pod. Refer to [5] if you would like to see what Cilium CNI does.
1.2 sysctls in container and unsafe sysctls in k8s
When creating a container, each sysctl parameter of the container has its default value; to customize those settings on container creation, you can pass them via command line arguments or API parameters. Such as, with docker CLI,
$ docker run --sysctl net.ipv4.ip_forward=1 <image>
In Kubernetes, some of these parameters are named "unsafe sysctls" parameters,
and must be explicitly enabled in kubelet if you’d like to customize them on Pod creation:
adding --allowed-unsafe-sysctls=<list> option to kubelet,
such as --allowed-unsafe-sysctls=net.core.somaxconn;
then, you can specify the desired value in pod spec’s securityContext
section, an example:
apiVersion: v1
kind: Pod
metadata:
name: smoke-pod-with-k8s
labels:
app: smoke-pod-with-k8s
spec:
securityContext:
sysctls: # <--- Put your custom sysctls in this section
- name: net.core.somaxconn
value: "1024"
containers:
- name: nginx
image: nginx-slim:0.8
ports:
- containerPort: 80
name: nginx
The securityContext claim will go through the pod security validation procedure in kube-apiserver; if validates, the request will be accepted.
1.3 The net.core.somaxconn parameter of pods/containers
As shown in the above spec, somaxconn is just one of those “unsafe sysctls” parameters in Kubernetes.
What is this parameter used for? According to kernel Documentation/networking/ip-sysctl.txt,
somaxconn - INTEGER
Limit of socket listen() backlog, known in userspace as SOMAXCONN.
Defaults to 4096. (Was 128 before linux-5.4)
See also tcp_max_syn_backlog for additional tuning for TCP sockets.
For server side applications, if this parameter is
too small, such as 128 traditionally, new TCP connecting requests from clients
may be rejected on encountering ingress requests bursts.
Refer to Cloudflare’s wonderful post [3] for more information.
1.4 Problem statement
With all the above introductions, we can now describe the problem that we’re going to talk about:
if you’re running a Kubernetes cluster, you may have noticed that when somaxconn is not specified in Pod specs,
some pods will have a value of 128, while some others may have a value of 4096, and it seems these
values are not inherited from the corresponding node’s settings,
as a node may have a somaxconn setting of 128, 1024, 2048, 4096, etc (but pods on the same host have the same default value).
So our question is: if net.core.somaxconn is not specified in Pod spec,
- What the parameter will be initialized for the pod? And,
- Who (kubelet, dockerd, containerd, runc, …) will be in responsible for the initialization?
By looking at the source code from kubelet all the way down to runc, we didn’t find any place that initiated the parameter explicitly: all they do is just passing this parameter to the down stream component if it were provided, and do nothing if the parameter is missing - meaning that the parameter is opaque to them.
But to confirm this behavior, let’s get our hands dirty and do some testings along the journey.
What we’ve already seen is that
some pods will get their somaxconn set as 128, and some as 4096; to see clearly if
this initial setting has any relationship with the host’s one,
we set somaxconn=2048 for the hosts, which is different from the both;
hence, if there is somewhere that inherits this value from the host,
we can immediately recognize it.
Changing the system setting of the node (we’ll schedule pods to this node later):
(node1) $ sysctl -w net.core.somaxconn=2048
net.core.somaxconn = 2048
Check the effective value:
(node1) $ sysctl net.core.somaxconn=2048
net.core.somaxconn = 2048
(node1) $ cat /proc/sys/net/core/somaxconn
2048
Now we’re ready to start our journey.
2.1 kube-apiserver -> kubelet
As the very beginning of a pod creation action, Kubernetes validates the pod spec and passes it to kubelet to perform the real creation.
So the first thing we want to be sure is: will Kubernetes (kube-apiserver or kubelet) choose a default value for a Pod if the parameter is missing from the Pod’s spec?
Well, we can find the answer in two places:
- Look at the final Pod spec in Kubernetes: to determine if Kubernetes would insert a default setting when
somaxconnis not specified; - Look at the kubelet log: check if there is
somaxconnrelated fields in the received Pod spec; kubelet will create pod according to this spec.
Now create a pod with spec (with no securityContext):
apiVersion: v1
kind: Pod
metadata:
name: smoke-pod-with-k8s
labels:
app: smoke-pod-with-k8s
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
tolerations:
- effect: NoSchedule
operator: Exists
containers:
- name: nginx
image: nginx-slim:0.8
ports:
- containerPort: 80
name: nginx
(master) $ k apply -f smoke-with-k8s.yaml
(master) $ k get pod smoke-pod-with-k8s -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
smoke-pod-with-k8s 1/1 Running 0 14s 10.2.4.32 node1 <none> <none>
Check if somaxconn will be automatically inserted if not provided in pod spec:
(master) $ k get pod smoke-pod-with-k8s -o yaml | grep -i somaxconn
# nothing here
No. Now check kubelet log on the node:
(node1) $ grep smoke-pod-with-k8s /var/log/kubernetes/kubelet.INFO
config.go ] Receiving a new pod "smoke-pod-with-k8s_default(ca66a1aa)"
kubelet.go ] SyncLoop (ADD, "api"): "smoke-pod-with-k8s_default(ca66a1aa)"
kubelet_pods.go ] Generating status for "smoke-pod-with-k8s_default(ca66a1aa)"
volume_manager.go ] Waiting for volumes to attach and mount for pod "smoke-pod-with-k8s_default(ca66a1aa)"
kubelet.go ] SyncLoop (RECONCILE, "api"): "smoke-pod-with-k8s_default(ca66a1aa)"
status_manager.go ] Patch status for pod "smoke-pod-with-k8s_default(ca66a1aa)" with
'{"metadata":{"uid":"ca66a1aa"},
"status":{"$setElementOrder/conditions":[{"type":"Initialized"},{"type":"Ready"},{"type":"ContainersReady"},{"type":"PodScheduled"}],"conditions":[{"message":"containers with unready status: [nginx]","reas
on":"ContainersNotReady","status":"False","type":"Ready"},{"message":"containers with unready status: [nginx]","reason":"ContainersNotReady","status":"False","type":"ContainersReady"}],"containerStatuses":[{"image":"nginx-slim:0.8","imageID":"","name":"nginx","ready":false,"restartCount":0,"started":false,"state":{"waiting":{"reason":"ContainerCreating"}}}]}}'
...
Well, we get lots of detailed configurations about the pod/container, but still no somaxconn related stuffs.

Fig. Kubernetes control plane (e.g. kube-apiserver) is eliminated from our suspects list
Kubernetes control plane components eliminated. Will kubelet add this parameter during its internal handling?
We can decide that by looking at the request it sends to dockerd.
2.2 kubelet -> dockerd
Will kubelet set a default value for somaxconn? Well, if it does, it must
pass this parameter to dockerd, as the real container creation is done by the latter.
So, we can check dockerd logs for this information.
(node1) $ grep smoke-pod-with-k8s /var/log/docker/dockerd.log
level=debug msg='Calling POST /containers/create?name=k8s_POD_smoke-pod-with-k8s_default_ca66a1aa'
level=debug msg='form data: {
"Entrypoint":null,
"Env":null,
"HostConfig":{"AutoRemove":false,"Binds":null,"BlkioDeviceReadBps":null,"BlkioDeviceReadIOps":null,"BlkioDeviceWriteBps":null,"BlkioDeviceWriteIOps":null,"BlkioWeight":0,"BlkioWeightDevice":null,"CapAdd":null,"CapDrop":null,"Capabilities":null,"Cgroup":"","CgroupParent":"/kubepods/besteffort/podca66a1aa","ConsoleSize":[0,0],"ContainerIDFile":"","CpuCount":0,"CpuPercent":0,"CpuPeriod":0,"CpuQuota":0,"CpuRealtimePeriod":0,"CpuRealtimeRuntime":0,"CpuShares":2,"CpusetCpus":"","CpusetMems":"","DeviceCgroupRules":null,"DeviceRequests":null,"Devices":null,"DiskQuota":0,"Dns":null,"DnsOptions":null,"DnsSearch":null,"ExtraHosts":null,"GroupAdd":null,"IOMaximumBandwidth":0,"IOMaximumIOps":0,"IpcMode":"shareable","Isolation":"","KernelMemory":0,"KernelMemoryTCP":0,"Links":null,"LogConfig":{"Config":null,"Type":""},"MaskedPaths":null,"Memory":0,"MemoryReservation":0,"MemorySwap":0,"MemorySwappiness":null,"NanoCpus":0,"NetworkMode":"none","OomKillDisable":null,"OomScoreAdj":-998,"PidMode":"","PidsLimit":null,"PortBindings":{},"Privileged":false,"PublishAllPorts":false,"ReadonlyPaths":null,"ReadonlyRootfs":false,"RestartPolicy":{"MaximumRetryCount":0,"Name":""},"SecurityOpt":["seccomp=unconfined"],"ShmSize":67108864,"UTSMode":"","Ulimits":null,"UsernsMode":"","VolumeDriver":"","VolumesFrom":null},
"Hostname":"smoke-pod-with-k8s",
"Image":"pause-amd64:3.1",
"Labels":{...},
"NetworkingConfig":null,
"OnBuild":null,"OpenStdin":false,"StdinOnce":false,"Tty":false,"User":"","Volumes":null,"WorkingDir":""}'
level=debug msg='Calling POST /containers/create?name=k8s_nginx_smoke-pod-with-k8s_default_ca66a1aa'
There are two POST /containers/create calls,
- the first one asks to create the
pausecontainer, which will hold the several namespaces for this Pod; - the second one asks to create the
nginxcontainer in the Pod spec.
No explicit somaxconn option in the POST body, otherwise we could see it in the
HostConfig.Sysctls field:
// https://github.com/moby/moby/blob/20.10/api/types/container/host_config.go#L426
// HostConfig the non-portable Config structure of a container.
// Here, "non-portable" means "dependent of the host we are running on".
// Portable information *should* appear in Config.
type HostConfig struct {
...
Sysctls map[string]string `json:",omitempty"` // List of Namespaced sysctls used for the container
...
}
As a comparison, this is how the HostConfig.Sysctls field looks like if the somaxconn
is provided in Pod spec’s securityContext:
level=debug msg='form data: {
"HostConfig":{
...
"Sysctls":{"net.core.somaxconn":"1024"},
...
},
...

Fig. kubelet is eliminated from our suspects list
kubelet eliminated. Will dockerd add this parameter in its internal handling?
2.3 Skip k8s/kubelet/cni: create container right from docker
Now we’ve narrows down the scope to dockerd and all its downstream components.
So, let’s forget all the stuffs around Kubernetes, and just start a clean container
directly with docker and see what the somaxconn will be. But before this,
we need to configure containerd to output more logs for us:
$ cat /etc/containerd/config.toml
...
[debug]
...
level = "debug" # <--- set this
[plugins]
[plugins.linux]
shim = "containerd-shim"
runtime = "runc"
runtime_root = ""
no_shim = false
shim_debug = true # <--- set this
# WARNING: restart containerd will cause all containers on this node to restart,
# DO NOT do this in your production nodes
$ systemctl restart containerd
Now create a container with docker:
$ sudo docker run -d --name smoke-ctn-with-docker nginx-slim:0.8 sleep 10d
977e0b1
$ sudo docker exec smoke-ctn-with-docker cat /proc/sys/net/core/somaxconn
4096 # <-- container value
$ cat /proc/sys/net/core/somaxconn
2048 # <-- host value
Still 4096, while the node has a value of 2048. Since this is a docker container but not a Kubernetes pod, CNI plugin is not involved, so CNI plugin (and the specific Kubernetes networking solution) is also eliminated from our suspects list.

Fig. kubelet and CNI plugin is eliminated from our suspects list
Now check the logs of containerd:
$ jourctl -u containerd -f
level=debug msg="event published" ns=moby topic=/containers/create type=containerd.events.ContainerCreate
level=info msg="shim containerd-shim started" address=/containerd-shim/977e0b1.sock debug=true pid=957711
level=debug msg="registering ttrpc server"
level=debug msg="serving api on unix socket" socket="[inherited from parent]"
level=debug msg="garbage collected" d="826.031µs"
level=debug msg="event published" ns=moby topic=/tasks/create type=containerd.events.TaskCreate
level=debug msg="event published" ns=moby topic=/tasks/start type=containerd.events.TaskStart
Well, request body not captured, maybe there are other log settings that we need to adjust.
But by looking into docker (moby) source code, we confirmed that it would only pass
this sysctl parameter if it’s provided in HostConfig.Sysctls[] option, or provided via CLI --sysctl option.
Neither did we do. This indicates that, the initial value is set by somewhere
further behind.

Fig. docker is eliminated from our suspects list
Move on.
2.4 Skip docker: create container right from containerd
Again, let’s forget all the stuffs about Docker, and just start a container with containerd’s CLI and see what the somaxconn setting is.
But note that containerd is one layer lower than docker, so docker images/containers can not be
manipulated by containerd directly. However, the good news is that they are much the same:
Find the right containerd.sock file
[email protected]:~ $ ctr images ls # stuck then timed out
ctr: failed to dial "/run/containerd/containerd.sock": context deadline exceeded
[email protected]:~ $ ls /run/containerd/containerd.sock
ls: cannot access /run/containerd/containerd.sock: No such file or directory
Well, seems we need to find the right sock, there are several ways:
# method 1: get from process parameters
[email protected]:~ $ ps -ef | grep "\-shim"
root 121568 7930 0 Jul29 ? 00:00:05 containerd-shim -namespace moby \
-workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/4d0e1ac \
-address /var/run/docker/libcontainerd/docker-containerd.sock \ # <-- this parameter
-containerd-binary /usr/bin/containerd \
-runtime-root /var/run/docker/runtime-runc
# method 2: get from config file
$ cat /etc/containerd/config.toml
[grpc]
address = "/var/run/docker/libcontainerd/docker-containerd.sock" # <-- this parameter
...
# method 3: get from config dump
$ containerd config dump | grep address | fgrep ".sock"
address = "/var/run/docker/libcontainerd/docker-containerd.sock" # <-- this parameter
Now try to use /var/run/docker/libcontainerd/docker-containerd.sock,
$ ctr -a /run/docker/libcontainerd/docker-containerd.sock images ls
REF TYPE DIGEST SIZE PLATFORMS LABELS
Successful!
Pull image
Pull the same image with containerd:
$ ctr -a /run/docker/libcontainerd/docker-containerd.sock images pull nginx-slim:0.8
$ ctr -a /run/docker/libcontainerd/docker-containerd.sock images ls
REF TYPE DIGEST SIZE PLATFORMS LABELS
nginx-slim:0.8 application/vnd.docker.distribution.manifest.v2+json sha256:dca6396b... 50.0 MiB linux/amd64 -
Create a container
Create a container (just run in the foreground here):
$ ctr -a /run/docker/libcontainerd/docker-containerd.sock run --rm -t nginx-slim:0.8 tmp
In another window:
$ ctr -a /run/docker/libcontainerd/docker-containerd.sock task ls
TASK PID STATUS
tmp 162866 RUNNING
Check the somaxconn setting
$ ctr -a /run/docker/libcontainerd/docker-containerd.sock task exec -t --exec-id bash_1 tmp bash
(inside container) $ cat /proc/sys/net/core/somaxconn
4096
Still 4096. Does containerd set this parameter internally? We can check the parameters it sends to runc, and the answer will be: NO - we leave the contents to the next section.
2.5 Skip containerd: create container right from runc
To get rid of containerd, we can create a container with runc directly. Well,
this is feasible of course, but not as straight forward as docker/containerd
does, as it needs file bundle rather than existing images as input:
$ runc create -h
USAGE:
runc create [command options] <container-id>
DESCRIPTION:
The create command creates an instance of a container for a bundle.
The bundle is a directory with a specification file named "config.json" and a root filesystem.
OPTIONS:
--bundle value, -b value path to the root of the bundle directory, defaults to the current directory
--console-socket value path to an AF_UNIX socket which will receive a file descriptor referencing the master end of the console's pseudoterminal
--pid-file value specify the file to write the process id to
--no-pivot do not use pivot root to jail process inside rootfs. This should be used whenever the rootfs is on top of a ramdisk
--no-new-keyring do not create a new session keyring for the container. This will cause the container to inherit the calling processes session key
--preserve-fds value Pass N additional file descriptors to the container (stdio + $LISTEN_FDS + N in total) (default: 0)
As the description said, runc reads a specification file named "config.json". The config.json for each container on the node:
(node1) $ find /run/containerd -name config.json
/run/containerd/io.containerd.runtime.v1.linux/moby/eedd634/config.json
/run/containerd/io.containerd.runtime.v1.linux/moby/3a92315/config.json
/run/containerd/io.containerd.runtime.v1.linux/moby/45e7479/config.json
/run/containerd/io.containerd.runtime.v1.linux/moby/25ac9be/config.json
/run/containerd/io.containerd.runtime.v1.linux/moby/54c3a57/config.json
Peek into one:
(node1) $ ls /run/containerd/io.containerd.runtime.v1.linux/moby/eedd6341c/
address config.json init.pid log.json rootfs shim.pid
(node1) $ cat /run/containerd/io.containerd.runtime.v1.linux/moby/eedd6341c/config.json | jq
{
"ociVersion": "1.0.1-dev",
"process": {
"user": {
"uid": 0,
"gid": 0
},
"args": [
"/pause"
],
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOSTNAME=smoke-pod-with-k8s"
],
...
"cgroupsPath": "/kubepods/besteffort/pod187acdb9/eedd6341c",
"namespaces": [
{
"type": "mount"
},
{
"type": "network"
},
...
],
"maskedPaths": [
"/proc/asound",
"/proc/acpi",
"/proc/kcore",
"/proc/keys",
"/proc/latency_stats",
"/proc/timer_list",
"/proc/timer_stats",
"/proc/sched_debug",
"/proc/scsi",
"/sys/firmware"
],
"readonlyPaths": [
"/proc/bus",
"/proc/fs",
"/proc/irq",
"/proc/sys",
"/proc/sysrq-trigger"
]
}
}
Still no somaxconn settings in the config.json.
Notice that runc mounts /proc/sys into the container as readonly.
However, proc files are not regular files, but read/write interfaces to the corresponding kernel parameters.
So this only indicates that we can read /proc/sys/net/core/somaxconn inside container, not that
the container inherits the current settings of the node.
But at this point, we still have gained something new: containerd didn’t set this for us, as config.json was created by containerd.

Fig. containerd is eliminated from our suspects list
Will runc initialize the parameter internally? The source code tells us that it won’t:
// libcontainer/standard_init_linux.go in runc
for key, value := range l.config.Config.Sysctl {
if err := writeSystemProperty(key, value); err != nil {
return err
}
}
It just writes those sysctl parameters specified by config.json to the container, and doesn’t not add any new values, or initialize default values of some fields are not provided.

Fig. runc is eliminated from our suspects list
So, it seems we’ve come to an end: no component picks and sets the default value for a newly created container.
What’s next to do? Well, runc will create namespaces based
on kernel capabilities, among those is the network namespace (netns).
Why not create a netns by hands and see what’s the value of somaxconn in that netns?
2.6 Skip runc: create container netns right from iproute2
Oh, still 4096.
But, this narrows things down quite a lot: maybe the parameter is specially handled/initialized by the kernel. With a quick search I found this question & answer at year 2014 [4]. Now let me explain it with kernel 5.10 code.
2.7 Skip iproute2: locate the kernel code of init new netns
In short, somaxconn is a special parameter that are registered per-netns:
// https://github.com/torvalds/linux/blob/v5.10/net/core/net_namespace.c#L375-L391
static int __net_init net_defaults_init_net(struct net *net) {
net->core.sysctl_somaxconn = SOMAXCONN; // <-- initialized with the kernel constant
return 0;
}
static struct pernet_operations net_defaults_ops = {
.init = net_defaults_init_net,
};
static __init int net_defaults_init(void) {
if (register_pernet_subsys(&net_defaults_ops))
panic("Cannot initialize net default settings");
return 0;
}
core_initcall(net_defaults_init);
When a new netns is created, .init = net_defaults_init_net
will be called to initialize the netns, and the init function actually does exactly one
thing as shown above, set somaxconn=SOMAXCONN for the netns, where SOMAXCONN is
a kernel built time constant, for kernel 5.4+, it’s 4096:
// https://github.com/torvalds/linux/blob/v5.10/include/linux/socket.h#L280
/* Maximum queue length specifiable by listen. */
#define SOMAXCONN 4096
And for kernel < 5.4, it’s set to 128. Suspect found!
3.1 Answers
-
When creating a pod in Kubernetes, if
somaxconnis not specified, what the default value will be and who sets it?The default value will be a kernel constant
SOMAXCONN, initialized during container’s network namespace (netns) creation, regardless of the node setting (effective only indefaultnetns). For kernel< 5.4, the constant is 128; for kernel5.4+, it’s 4096. -
If changing node’s sysctl settings, will they be propagated to pods?
It depends. Most values will, but as we’ve seen in this post,
somaxconnwon’t. -
Are all sysctl parameters are equal in terms of initialization and propagation?
No.
somaxconnis just such an exception.
The change was from Google:
net: increase SOMAXCONN to 4096
SOMAXCONN is /proc/sys/net/core/somaxconn default value.
It has been defined as 128 more than 20 years ago.
Since it caps the listen() backlog values, the very small value has
caused numerous problems over the years, and many people had
to raise it on their hosts after beeing hit by problems.
Google has been using 1024 for at least 15 years, and we increased
this to 4096 after TCP listener rework has been completed, more than
4 years ago. We got no complain of this change breaking any
legacy application.
Many applications indeed setup a TCP listener with listen(fd, -1);
meaning they let the system select the backlog.
Raising SOMAXCONN lowers chance of the port being unavailable under
even small SYNFLOOD attack, and reduces possibilities of side channel
vulnerabilities.
Signed-off-by: Eric Dumazet <[email protected]>
Cc: Willy Tarreau <[email protected]>
Cc: Yue Cao <[email protected]>
Signed-off-by: David S. Miller <[email protected]>
Cilium bandwidth manager: setting somaxconn=4096 on agent start
// https://github.com/cilium/cilium/blob/v1.10.7/pkg/bandwidth/bandwidth.go#L100-L109
baseSettings := []setting{
{"net.core.netdev_max_backlog", "1000"},
{"net.core.somaxconn", "4096"},
{"net.core.default_qdisc", "fq"},
{"net.ipv4.tcp_max_syn_backlog", "4096"},
// Temporary disable setting bbr for now until we have a kernel fix for pacing out of Pods as described in #15324.
// Then, kernels with the fix can use bbr, and others cubic.
{"net.ipv4.tcp_congestion_control", "cubic"},
}
But note that bandwidth manager could only be enabled on kernel 5.10+.
- Why and How to Use containerd From Command Line, https://iximiuz.com, 2022
- CVE-2020-15275: New Vulnerability Exploits containerd-shim API, https://blog.aquasec.com, 2020
- SYN packet handling in the wild, Cloudflare, 2018
- Refresh net.core.somaxcomm (or any sysctl property) for docker containers, Stackoverflow, 2014
- Cilium Code Walk Through: CNI Create Network
如有侵权请联系:admin#unsafe.sh