
- Origin
- About This Tool
- Serialization and Deserialization
- Serialization and Deserialization Libraries in Java
- Control Data Type => Control Code
- Magic Method
- Gadgetinspector Workflow
- Sample Analysis
- Sink->Source?
- Defect
- Conceive and Improve
- At last
- Reference
- About Knownsec & 404 Team
Author:Longofo@Knownsec 404 Team
Time: September 4, 2019
Chinese version: https://paper.seebug.org/1034/
Origin
I first learned about this tool through @Badcode, which was putted forward in an topic in Black Hat 2018.This is a static-based analysis of bytecodes that uses known tricks to automatically find the deserialization chain tool from source to sink. I watched the author's speech video and PPT on Black Hat several times, I want to get more information about the principle of this tool from the author's speech and PPT, but some places are really confusing. However, the author has open sourced this tool, but did not give detailed documentation, and there are very few analytical articles on this tool. I saw an analysis of the tool by Ping An Group. From the description of the article, they should have this tool a certain understanding and some improvements, but did not explain too much detail in the article. Later, I tried to debug this tool and roughly clarified the working principle of this tool. The following is the analysis process of this tool, as well as the idea of my future work and improvement.
About This Tool
- This tool does not use to find vulnerabilities. Instead, it uses the known source->...->sink tricks or its similar features to discover branch utilization chains or new utilization chains.
- This tool is looking for a chain in the classpath of the entire application.
- This tool performs some reasonable risk estimation (stain judgment, taint transfer, etc.).
- This tool will generate false positives and not false negatives (in fact, it will still be missed, which is determined by the strategy used by the author and can be seen in the analysis below).
- This tool is based on bytecode analysis. For Java applications, many times we don't have source code, only War package, Jar package or class file.
- This tool does not generate Payload that can be directly utilized. The specific utilization structure also requires manual participation.
Serialization and Deserialization
Serialization is a process of converting the state information of an object into a form that can be stored or transmitted. The converted information can be stored on a disk. In the process of network transmission, it can be in the form of byte, XML, JSON, etc. The reverse process of restoring information in bytes, XML, JSON, etc into objects is called deserialization.
In Java, object serialization and deserialization are widely used in RMI (remote method invocation) and network transmission.
Serialization and Deserialization Libraries in Java
- JDK(ObjectInputStream)
- XStream(XML,JSON)
- Jackson(XML,JSON)
- Genson(JSON)
- JSON-IO(JSON)
- FlexSON(JSON)
- Fastjson(JSON)
- ...
Different deserialization libraries have different behaviors when deserializing different classes. Different "magic methods" will be called automatically, and these automatically called methods can be used as deserialization entry point(source). If these automatically called methods call other sub-methods, then a sub-method in the call chain can also be used as the source, which is equivalent to knowing the front part of the call chain, starting from a sub-method to find different branches. Some dangerous methods (sink) may be reached through layer calls of methods.
- ObjectInputStream
For example, a class implements the Serializable interface, then ObjectInputStream.readobject will automatically finds the readObject、readResolve and etc methods of the class when deserialization.
For example, a class implements the Externalizable interface, then ObjectInputStream.readobject will automatically finds the readExternal and etc methods of this class when deserialization.
- Jackson
When ObjectMapper.readValue deserialization one class, it will automatically finds the no-argument constructor of the deserialization class、the constructor that contains a base type parameter、the setter of the property、the getter of the property, and so on.
- ...
In the next analysis, I used the JDK's own ObjectInputStream as an example.
Control Data Type => Control Code
The author said that in the deserialization vulnerability, if we control the data type, we control the code. What does it mean? According to my understanding, I wrote the following example:
public class TestDeserialization { interface Animal { public void eat(); } public static class Cat implements Animal,Serializable { @Override public void eat() { System.out.println("cat eat fish"); } } public static class Dog implements Animal,Serializable { @Override public void eat() { try { Runtime.getRuntime().exec("calc"); } catch (IOException e) { e.printStackTrace(); } System.out.println("dog eat bone"); } } public static class Person implements Serializable { private Animal pet; public Person(Animal pet){ this.pet = pet; } private void readObject(java.io.ObjectInputStream stream) throws IOException, ClassNotFoundException { pet = (Animal) stream.readObject(); pet.eat(); } } public static void GeneratePayload(Object instance, String file) throws Exception { //Serialize the constructed payload and write it to the file File f = new File(file); ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f)); out.writeObject(instance); out.flush(); out.close(); } public static void payloadTest(String file) throws Exception { //Read the written payload and deserialize it ObjectInputStream in = new ObjectInputStream(new FileInputStream(file)); Object obj = in.readObject(); System.out.println(obj); in.close(); } public static void main(String[] args) throws Exception { Animal animal = new Dog(); Person person = new Person(animal); GeneratePayload(person,"test.ser"); payloadTest("test.ser"); // Animal animal = new Cat(); // Person person = new Person(animal); // GeneratePayload(person,"test.ser"); // payloadTest("test.ser"); } }
For convenience I write all classes in a class for testing. In the Person class, there is an attribute pet of the Animal class, which is the interface between Cat and Dog. In serialization, we can control whether Per's pet is a Cat object or a Dog object, so in the deserialization, the specific direction of pet.eat() in readObject is different. If pet is a Cat class object, it will not go to the execution of the harmful code Runtime.getRuntime().exec("calc");, but if pet is a Dog class object, it will go to the harmful code.
Even though sometimes a class property has been assigned a specific object when declaration, it can still be modified by reflection in Java. as follows:
public class TestDeserialization { interface Animal { public void eat(); } public static class Cat implements Animal, Serializable { @Override public void eat() { System.out.println("cat eat fish"); } } public static class Dog implements Animal, Serializable { @Override public void eat() { try { Runtime.getRuntime().exec("calc"); } catch (IOException e) { e.printStackTrace(); } System.out.println("dog eat bone"); } } public static class Person implements Serializable { private Animal pet = new Cat(); private void readObject(java.io.ObjectInputStream stream) throws IOException, ClassNotFoundException { pet = (Animal) stream.readObject(); pet.eat(); } } public static void GeneratePayload(Object instance, String file) throws Exception { //Serialize the constructed payload and write it to the file File f = new File(file); ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(f)); out.writeObject(instance); out.flush(); out.close(); } public static void payloadTest(String file) throws Exception { //Read the written payload and deserialize it ObjectInputStream in = new ObjectInputStream(new FileInputStream(file)); Object obj = in.readObject(); System.out.println(obj); in.close(); } public static void main(String[] args) throws Exception { Animal animal = new Dog(); Person person = new Person(); //Modify private properties by reflection Field field = person.getClass().getDeclaredField("pet"); field.setAccessible(true); field.set(person, animal); GeneratePayload(person, "test.ser"); payloadTest("test.ser"); } }
In the Person class, you can't assign a value to pet through a constructor or setter method or other methods. The attribute is already defined as an object of the Cat class when it is declared, but use reflection can modify pet to the object of the Dog class, so when deserialization, it still go to the harmful code.
This is just my own view for author: "Control the data type, you control the code". In Java deserialization vulnerability, in many cases is to use Java's polymorphic feature to control the direction of the code and finally achieve the purpose of malicious.
Magic Method
In the above example, we can see that the readobject method of Person is not called by manually when deserializing. It is called automatically when the ObjectInputStream deserializes the object. The author call the methods that will be automatically to "Magic method".
Several common magic methods when deserializing with ObjectInputStream:
- Object.readObject()
- Object.readResolve()
- Object.finalize()
- ...
Some serializable JDK classes implement the above methods and also automatically call other methods (which can be used as known entry points):
- HashMap
- Object.hashCode()
- Object.equals()
- PriorityQueue
- Comparator.compare()
- Comparable.CompareTo()
- ...
Some sinks:
- Runtime.exec(), the simplest and straightforward way to execute commands directly in the target environment
- Method.invoke(), which requires proper selection of methods and parameters, and execution of Java methods via reflection
- RMI/JNDI/JRMP, etc., indirectly realize the effect of arbitrary code execution by referencing remote objects
- ...
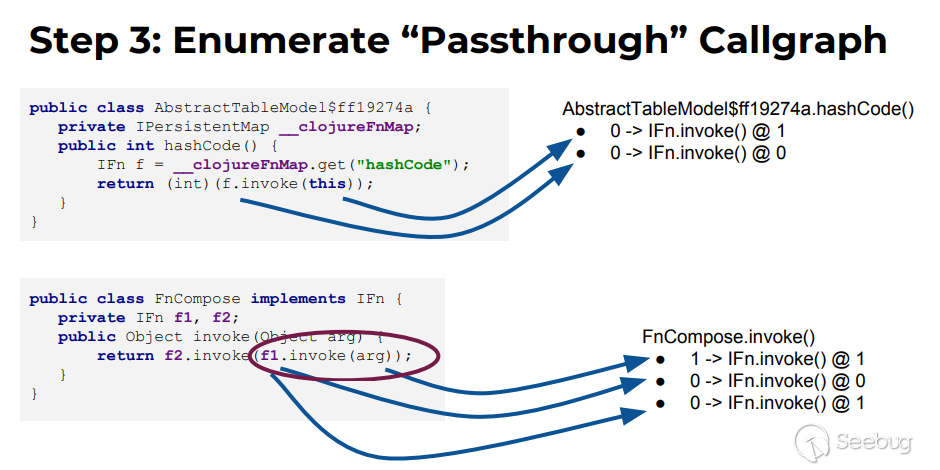
The author gives an example from Magic Methods(source)->Gadget Chains->Runtime.exec(sink):

The above HashMap implements the "magic method" of readObject and calls the hashCode method. Some classes implement the equals method to compare equality between objects (generally the equals and hashCode methods are implemented simultaneously). It can be seen from the figure that AbstractTableModel$ff19274a implements the hashCode method, which calls the f.invoke method, f is the IFn object, and f can be obtained by the attribute __clojureFnMap. IFn is an interface. As mentioned above, if the data type is controlled, the code direction is controlled. So if we put an object of the implementation class FnCompose of the IFn interface in __clojureFnMap during serialization, we can control the f.invoke method to walk the FnCompose.invoke method, and then control the f1 and f2 in FnCompose.invoke. FnConstant can reach FnEval.invoke (for the f.invoke in AbstractTableModel$ff19274a.hashcode, which implementation class of IFn is selected, according to the test of this tool and the analysis of the decision principle, the breadth priority will be selected. The short path, which is FnEval.invoke, this is why human participation can be seen in the later sample analysis).
With this chain, we only need to find the vulnerability point that triggered the chain. Payload uses the JSON format as follows:
{ "@class":"java.util.HashMap", "members":[ 2, { "@class":"AbstractTableModel$ff19274a", "__clojureFnMap":{ "hashcode":{ "@class":"FnCompose", "f1":{"@class","FnConstant",value:"calc"}, "f2":{"@class":"FnEval"} } } } ] }
Gadgetinspector Workflow
As the author said, it took exactly five steps:
// Enumerate all classes and all methods of the class if (!Files.exists(Paths.get("classes.dat")) || !Files.exists(Paths.get("methods.dat")) || !Files.exists(Paths.get("inheritanceMap.dat"))) { LOGGER.info("Running method discovery..."); MethodDiscovery methodDiscovery = new MethodDiscovery(); methodDiscovery.discover(classResourceEnumerator); methodDiscovery.save(); } //Generate passthrough data flow if (!Files.exists(Paths.get("passthrough.dat"))) { LOGGER.info("Analyzing methods for passthrough dataflow..."); PassthroughDiscovery passthroughDiscovery = new PassthroughDiscovery(); passthroughDiscovery.discover(classResourceEnumerator, config); passthroughDiscovery.save(); } //Generate passthrough call graph if (!Files.exists(Paths.get("callgraph.dat"))) { LOGGER.info("Analyzing methods in order to build a call graph..."); CallGraphDiscovery callGraphDiscovery = new CallGraphDiscovery(); callGraphDiscovery.discover(classResourceEnumerator, config); callGraphDiscovery.save(); } //Search for available sources if (!Files.exists(Paths.get("sources.dat"))) { LOGGER.info("Discovering gadget chain source methods..."); SourceDiscovery sourceDiscovery = config.getSourceDiscovery(); sourceDiscovery.discover(); sourceDiscovery.save(); } //Search generation call chain { LOGGER.info("Searching call graph for gadget chains..."); GadgetChainDiscovery gadgetChainDiscovery = new GadgetChainDiscovery(config); gadgetChainDiscovery.discover(); }
Step1 Enumerates All Classes and All Methods of Each Class
To perform a search of the call chain, you must first have information about all classes and all class methods:
public class MethodDiscovery { private static final Logger LOGGER = LoggerFactory.getLogger(MethodDiscovery.class); private final List<ClassReference> discoveredClasses = new ArrayList<>();//Save all class information private final List<MethodReference> discoveredMethods = new ArrayList<>();//Save all methods information ... ... public void discover(final ClassResourceEnumerator classResourceEnumerator) throws Exception { //classResourceEnumerator.getAllClasses() gets all the classes at runtime (JDK rt.jar) and all classes in the application to be searched for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) { try (InputStream in = classResource.getInputStream()) { ClassReader cr = new ClassReader(in); try { cr.accept(new MethodDiscoveryClassVisitor(), ClassReader.EXPAND_FRAMES);//Save the method information to discoveredMethods by manipulating the bytecode through the ASM framework and saving the class information to this.discoveredClasses } catch (Exception e) { LOGGER.error("Exception analyzing: " + classResource.getName(), e); } } } } ... ... public void save() throws IOException { DataLoader.saveData(Paths.get("classes.dat"), new ClassReference.Factory(), discoveredClasses);//Save class information to classes.dat DataLoader.saveData(Paths.get("methods.dat"), new MethodReference.Factory(), discoveredMethods);//Save method information to methods.dat Map<ClassReference.Handle, ClassReference> classMap = new HashMap<>(); for (ClassReference clazz : discoveredClasses) { classMap.put(clazz.getHandle(), clazz); } InheritanceDeriver.derive(classMap).save();//Find all inheritance relationships and save } }
Let's see what classes.dat and methods.dat look like:
classes.dat
two more characteristic ones:
| class name | Parent class name | All interfaces | Is interface? | member |
|---|---|---|---|---|
| com/sun/deploy/jardiff/JarDiffPatcher | java/lang/Object | com/sun/deploy/jardiff/JarDiffConstants,com/sun/deploy/jardiff/Patcher | false | newBytes!2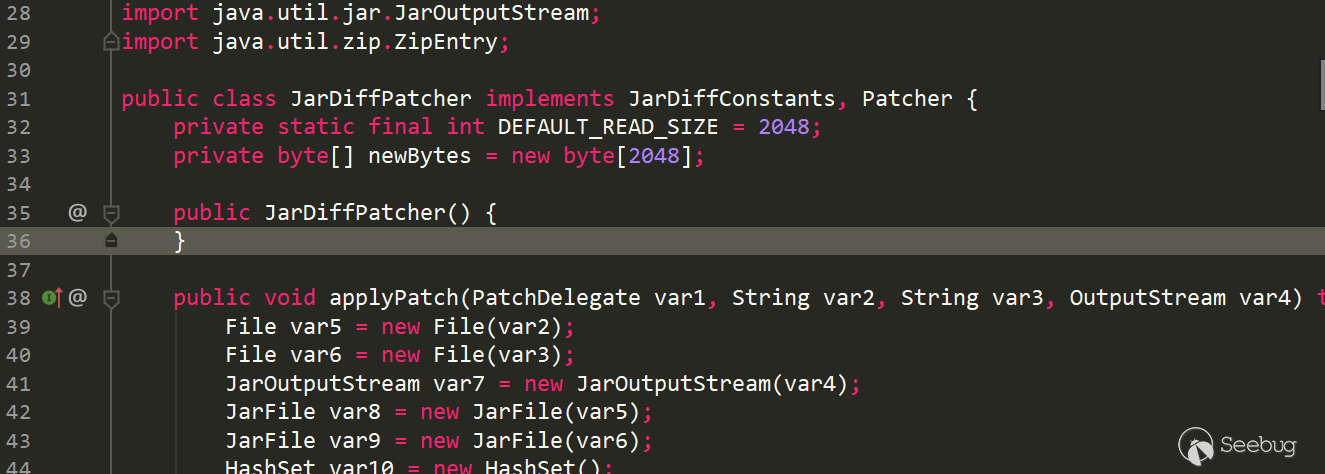
Corresponding to the table information above, it is consistent.
- class name:com/sun/deploy/jardiff/JarDiffPatcher
- Parent class: java/lang/Object,If a class does not explicitly inherit other classes, the default implicitly inherits java/lang/Object, and java does not allow multiple inheritance, so each class has only one parent class.
- All interfaces:com/sun/deploy/jardiff/JarDiffConstants、com/sun/deploy/jardiff/Patcher
- is interfaces or not:false
- member:newBytes!2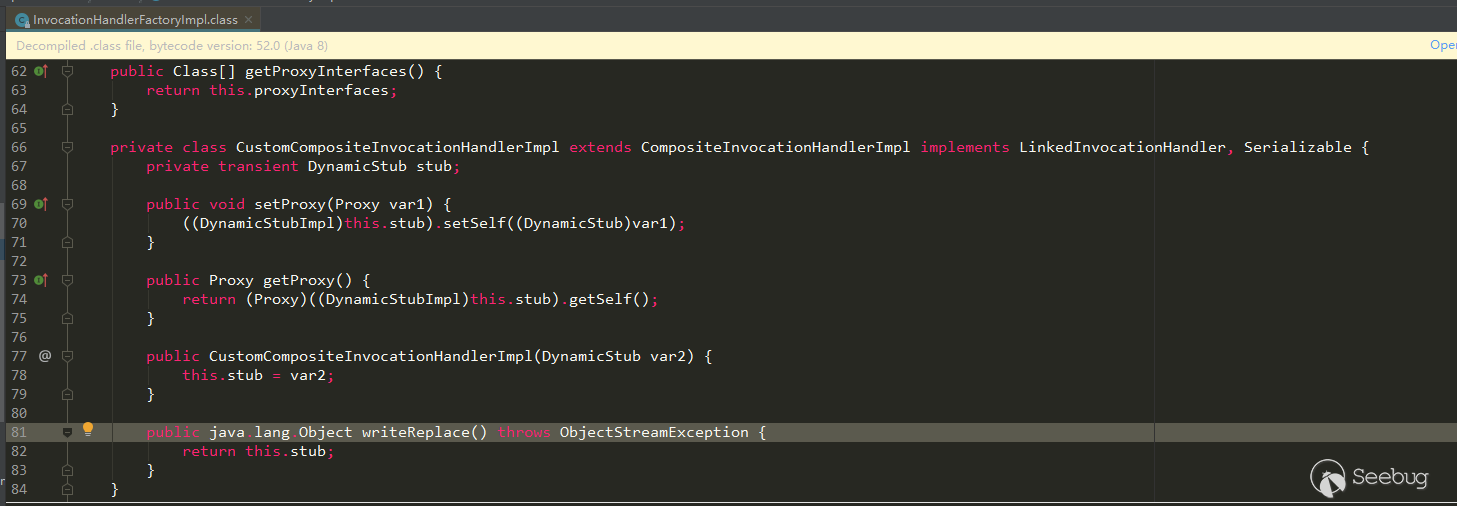
Corresponding to the table information above, it is also consistent.
- class name:com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl$CustomCompositeInvocationHandlerImpl,it is an inner class
- Parent class:com/sun/corba/se/spi/orbutil/proxy/CompositeInvocationHandlerImpl
- All interfaces:com/sun/corba/se/spi/orbutil/proxy/LinkedInvocationHandler,java/io/Serializable
- is interfaces or not:false
- member:stub!130!com/sun/corba/se/spi/presentation/rmi/DynamicStub!this$0!4112!com/sun/corba/se/impl/presentation/rmi/InvocationHandlerFactoryImpl,!*! can be temporarily understood as a separator,it has a member stub,type is com/sun/corba/se/spi/presentation/rmi/DynamicStub。Because it is an inner class, so there is a more
thismember,thispoints to the outer class.
methods.dat
two more characteristic ones:
| class name | method name | method info | is static method |
|---|---|---|---|
| sun/nio/cs/ext/Big5 | newEncoder | ()Ljava/nio/charset/CharsetEncoder; | false |
| sun/nio/cs/ext/Big5_HKSCS$Decoder | \<init> | (Ljava/nio/charset/Charset;Lsun/nio/cs/ext/Big5_HKSCS$1;)V | false |
sun/nio/cs/ext/Big5#newEncoder:
- class name:sun/nio/cs/ext/Big5
- method name: newEncoder
- method info:()Ljava/nio/charset/CharsetEncoder; no params,return java/nio/charset/CharsetEncoder object
- is static method:false
sun/nio/cs/ext/Big5_HKSCS$Decoder#\<init>:
- class name:sun/nio/cs/ext/Big5_HKSCS$Decoder
- method name:\<init>
- method info:
(Ljava/nio/charset/Charset;Lsun/nio/cs/ext/Big5_HKSCS$1;)VParameter 1 is java/nio/charset/Charset type, parameter 2 is sun/nio/cs/ext/Big5_HKSCS$1 type, and the return value is void. - is static method:false
Generate Inheritance relationship
The inheritance relationship is used later to determine whether a class can be serialized by a library and searched for subclass methods.
public class InheritanceDeriver { private static final Logger LOGGER = LoggerFactory.getLogger(InheritanceDeriver.class); public static InheritanceMap derive(Map<ClassReference.Handle, ClassReference> classMap) { LOGGER.debug("Calculating inheritance for " + (classMap.size()) + " classes..."); Map<ClassReference.Handle, Set<ClassReference.Handle>> implicitInheritance = new HashMap<>(); for (ClassReference classReference : classMap.values()) { if (implicitInheritance.containsKey(classReference.getHandle())) { throw new IllegalStateException("Already derived implicit classes for " + classReference.getName()); } Set<ClassReference.Handle> allParents = new HashSet<>(); getAllParents(classReference, classMap, allParents);//Get all the parent classes of the current class implicitInheritance.put(classReference.getHandle(), allParents); } return new InheritanceMap(implicitInheritance); } ... ... private static void getAllParents(ClassReference classReference, Map<ClassReference.Handle, ClassReference> classMap, Set<ClassReference.Handle> allParents) { Set<ClassReference.Handle> parents = new HashSet<>(); if (classReference.getSuperClass() != null) { parents.add(new ClassReference.Handle(classReference.getSuperClass()));//父类 } for (String iface : classReference.getInterfaces()) { parents.add(new ClassReference.Handle(iface));//Interface class } for (ClassReference.Handle immediateParent : parents) { //Get the indirect parent class, and recursively get the parent class of the indirect parent class ClassReference parentClassReference = classMap.get(immediateParent); if (parentClassReference == null) { LOGGER.debug("No class id for " + immediateParent.getName()); continue; } allParents.add(parentClassReference.getHandle()); getAllParents(parentClassReference, classMap, allParents); } } ... ... }
The result of this step is saved to inheritanceMap.dat:
| class | Direct parent class + indirect parent class |
|---|---|
| com/sun/javaws/OperaPreferencesPreferenceEntryIterator | java/lang/Object、java/util/Iterator |
| com/sun/java/swing/plaf/windows/WindowsLookAndFeel$XPValue | java/lang/Object、javax/swing/UIDefaults$ActiveValue |
Step2 Generate Passthrough Data Flow
The passthrough data flow here refers to the relationship between the return result of each method and the method parameters. The data generated in this step will be used when generating the passthrough call graph.
Take the demo given by the author as an example, first judge from the macro level:

The relationship between FnConstant.invoke return value and parameter this(Parameter 0, because all members of the class can be controlled during serialization, so all member variables are treated as 0 arguments):
- relationship with this param: returned this.value, which is related to 0
- relationship with arg param: The return value has no relationship with arg, that is, it has no relationship with 1 parameter.
- The conclusion is that FnConstant.invoke is related to parameter 0 and is represented as FnConstant.invoke()->0
The relationship between the Fndefault.invoke return value and the parameters this (parameter 0), arg (parameter 1): - relationship with this param: The second branch of the return condition has a relationship with this.f, that is, it has a relationship with 0. - relationship with arg param: The first branch of the return condition has a relationship with arg, that is, it has a relationship with 1 argument - The conclusion is that FnConstant.invoke has a relationship with 0 parameters and 1 parameter, which is expressed as Fndefault.invoke()->0, Fndefault.invoke()->1
In this step, the gadgetinspector uses ASM to analyze the method bytecode. The main logic is in the classes PassthroughDiscovery and TaintTrackingMethodVisitor. In particular, TaintTrackingMethodVisitor, which traces the stack and localvar of the JVM virtual machine when it executes the method, and finally returns whether the returned result can be contaminated by the parameter marker.
Core implementation code (TaintTrackingMethodVisitor involves bytecode analysis, temporarily ignored):
public class PassthroughDiscovery { private static final Logger LOGGER = LoggerFactory.getLogger(PassthroughDiscovery.class); private final Map<MethodReference.Handle, Set<MethodReference.Handle>> methodCalls = new HashMap<>(); private Map<MethodReference.Handle, Set<Integer>> passthroughDataflow; public void discover(final ClassResourceEnumerator classResourceEnumerator, final GIConfig config) throws IOException { Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();//load Methods.dat Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses();//load classes.dat InheritanceMap inheritanceMap = InheritanceMap.load();//load inheritanceMap.dat Map<String, ClassResourceEnumerator.ClassResource> classResourceByName = discoverMethodCalls(classResourceEnumerator);//Find the submethod contained in a method List<MethodReference.Handle> sortedMethods = topologicallySortMethodCalls();//Perform inverse topology sorting on graphs composed of all methods passthroughDataflow = calculatePassthroughDataflow(classResourceByName, classMap, inheritanceMap, sortedMethods, config.getSerializableDecider(methodMap, inheritanceMap));//Compute and generate passthrough data flow, involving bytecode analysis } ... ... private List<MethodReference.Handle> topologicallySortMethodCalls() { Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences = new HashMap<>(); for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodCalls.entrySet()) { MethodReference.Handle method = entry.getKey(); outgoingReferences.put(method, new HashSet<>(entry.getValue())); } // Perform inverse topology sorting on graphs composed of all methods LOGGER.debug("Performing topological sort..."); Set<MethodReference.Handle> dfsStack = new HashSet<>(); Set<MethodReference.Handle> visitedNodes = new HashSet<>(); List<MethodReference.Handle> sortedMethods = new ArrayList<>(outgoingReferences.size()); for (MethodReference.Handle root : outgoingReferences.keySet()) { dfsTsort(outgoingReferences, sortedMethods, visitedNodes, dfsStack, root); } LOGGER.debug(String.format("Outgoing references %d, sortedMethods %d", outgoingReferences.size(), sortedMethods.size())); return sortedMethods; } ... ... private static void dfsTsort(Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences, List<MethodReference.Handle> sortedMethods, Set<MethodReference.Handle> visitedNodes, Set<MethodReference.Handle> stack, MethodReference.Handle node) { if (stack.contains(node)) {//Prevent entry into the loop in a method call chain of dfs return; } if (visitedNodes.contains(node)) {//Prevent reordering of a method and submethod return; } Set<MethodReference.Handle> outgoingRefs = outgoingReferences.get(node); if (outgoingRefs == null) { return; } stack.add(node); for (MethodReference.Handle child : outgoingRefs) { dfsTsort(outgoingReferences, sortedMethods, visitedNodes, stack, child); } stack.remove(node); visitedNodes.add(node); sortedMethods.add(node); } }
Topological sorting
Topological sorting is only available for directed acyclic graphs (DAGs), and non-DAG graphs have no topological sorting. When a directed acyclic graph meets the following conditions: - every vertex appears and only appears once - If A is in front of B in the sequence, there is no path from B to A in the figure.
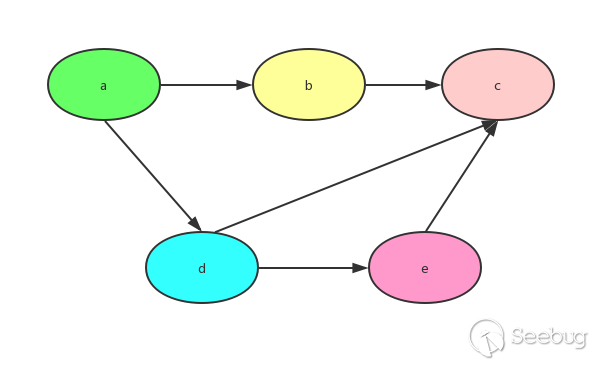
Such a graph is a topologically ordered graph. Tree structures can actually be transformed into topological sorting, while topological sorting does not necessarily translate into trees.
Take the above topological sorting diagram as an example, use a dictionary to represent the graph structure:
graph = { "a": ["b","d"], "b": ["c"], "d": ["e","c"], "e": ["c"], "c": [], }
Implementation code:
graph = { "a": ["b","d"], "b": ["c"], "d": ["e","c"], "e": ["c"], "c": [], } def TopologicalSort(graph): degrees = dict((u, 0) for u in graph) for u in graph: for v in graph[u]: degrees[v] += 1 #Insert queue with zero degree of entry queue = [u for u in graph if degrees[u] == 0] res = [] while queue: u = queue.pop() res.append(u) for v in graph[u]: # Remove the edge, the intrinsic degree of the current element related element -1 degrees[v] -= 1 if degrees[v] == 0: queue.append(v) return res print(TopologicalSort(graph)) # ['a', 'd', 'e', 'b', 'c']
But in the method call, we hope that the final result is c, b, e, d, a, this step requires inverse topological sorting, forward sorting using BFS, then the opposite result can use DFS. Why do we need to use inverse topology sorting in method calls, which is related to generating passthrough data streams. Look at the following example:
... public String parentMethod(String arg){ String vul = Obj.childMethod(arg); return vul; } ...
So is there any relationship between arg and the return value? Suppose Obj.childMethod is:
... public String childMethod(String carg){ return carg.toString(); } ...
Since the return value of childMethod is related to carg, it can be determined that the return value of parentMethod is related to parameter arg. So if there is a submethod call and passed the parent method argument to the submethod, you need to first determine the relationship between the submethod return value and the submethod argument. Therefore, the judgment of the submethod needs to be preceded, which is why the inverse topological sorting is performed.
As you can see from the figure below, the data structure of outgoingReferences is:
{ method1:(method2,method3,method4), method5:(method1,method6), ... }
And this structure is just right for inverse topological sorting.
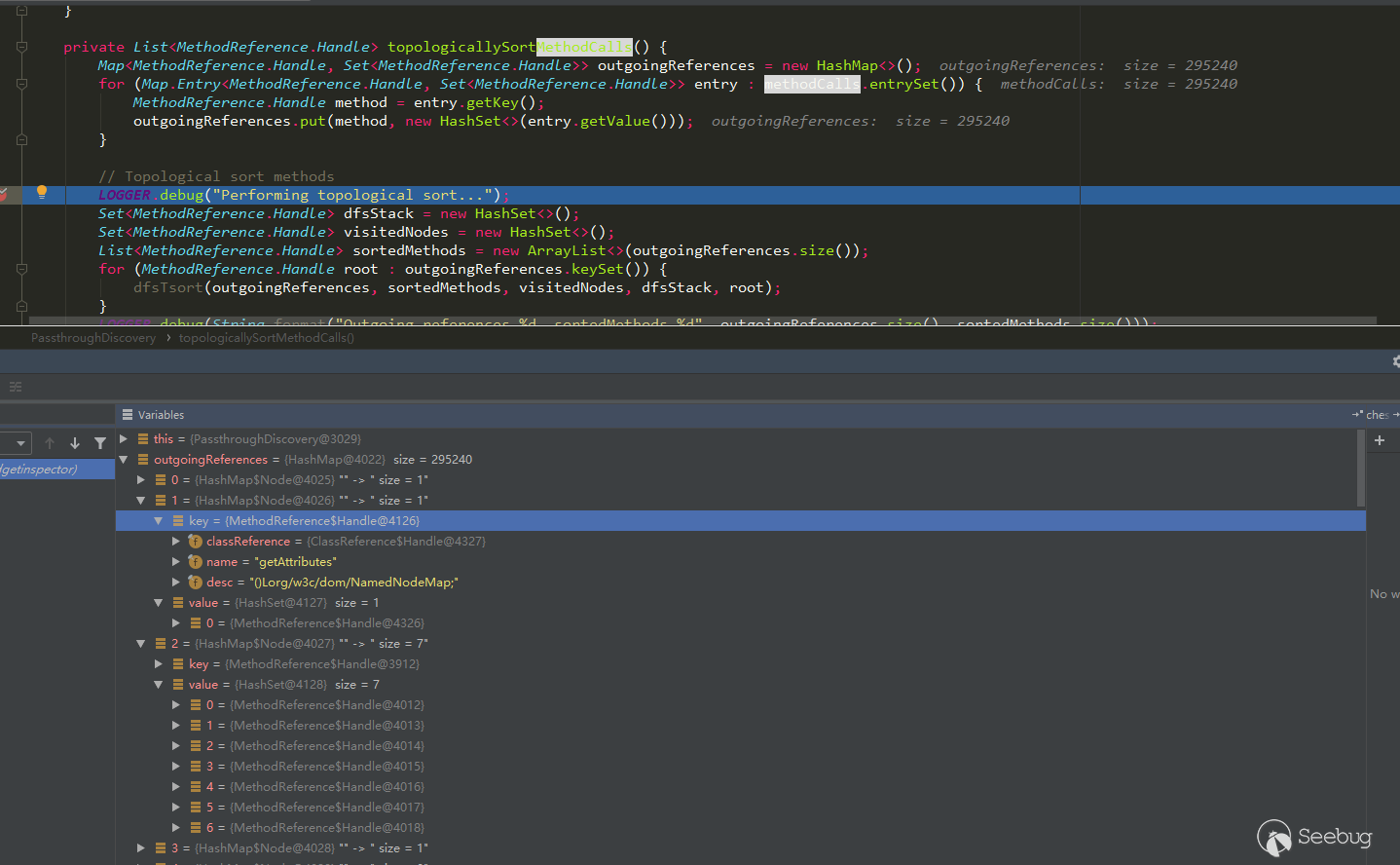
But the above said that the topology can not form a ring when sorting, but there must be a ring in the method call. How is the author avoided?
In the above dfsTsort implementation code, you can see that stack and visitedNodes are used. Stack ensures that loops are not formed when performing reverse topology sorting, and visitedNodes avoids repeated sorting. Use the following call graph to demonstrate the process:
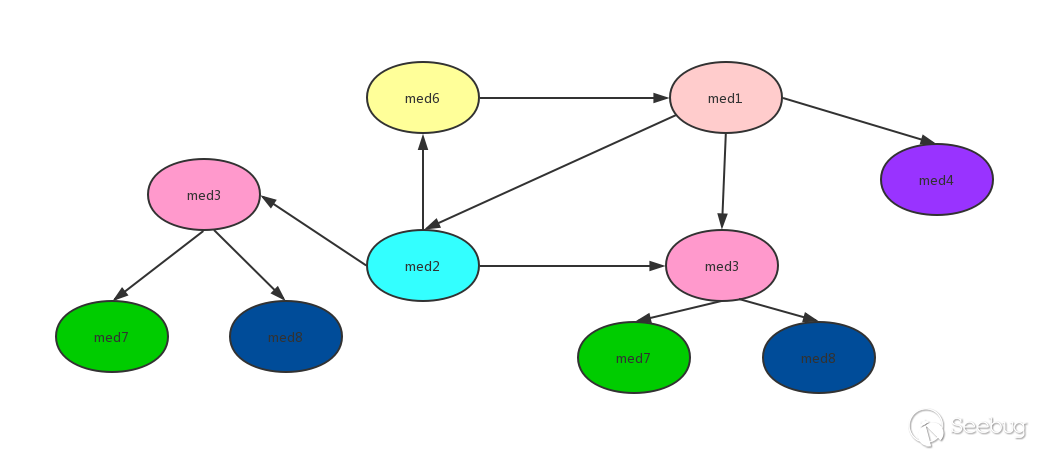
From the figure, we can see that there are rings med1->med2->med6->med1, and there are repeated calls to med3. Strictly speaking, it cannot be sorted by inverse topology, but it can be realized by the method of stack and visited records. For the convenience of explanation, the above diagram is represented by a tree:
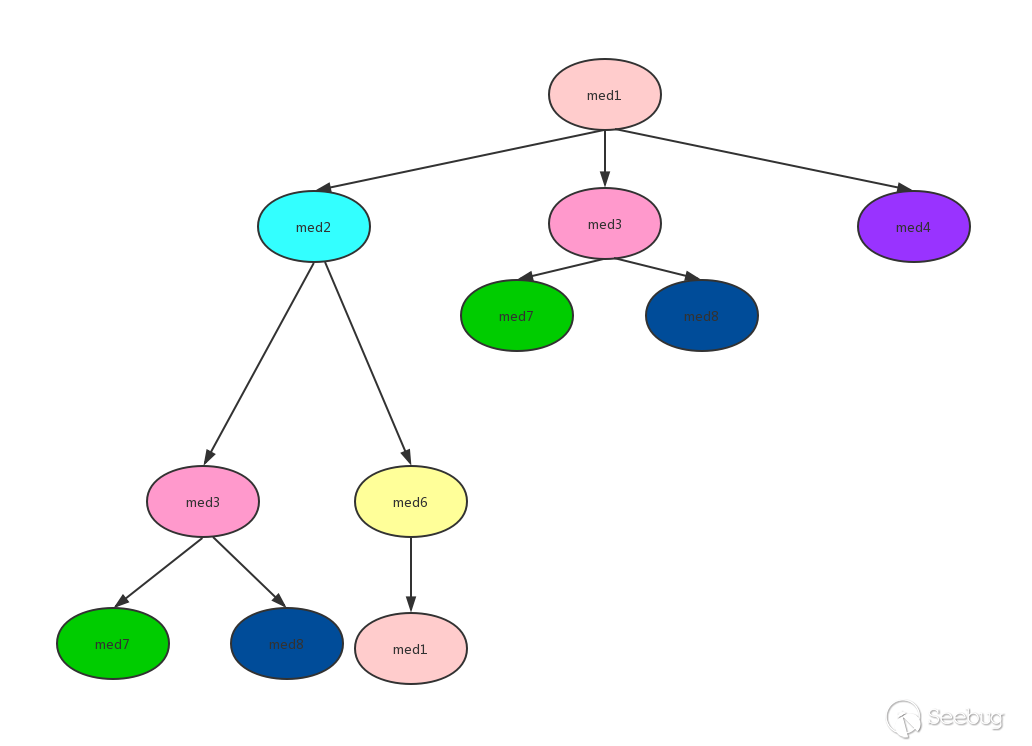
Perform inverse topology sorting (DFS mode) on the above image:
Starting from med1, first add med1 to the stack. At this time, the status of stack, visited, and sortedmethods is as follows:

Is there a submethod for med1? Yes, continue deep traversal. Put med2 into the stack, the state at this time:

Does med2 have submethods? Yes, continue deep traversal. Put med3 into the stack, the state at this time:

Does med3 have submethods? Yes, continue deep traversal. Put med7 into the stack, the state at this time:

Does med7 have submethods? No, pop med7 from the stack and add visited and sortedmethods, the state at this time:

Going back to the previous level, is there any other submethod for med3? Yes, med8, put med8 into the stack, the state at this time:

Is there a submethod for med8? No, pop up the stack, add visited and sortedmethods, the state at this time:

Going back to the previous level, is there any other submethod for med3? No, pop up the stack, add visited and sortedmethods, the state at this time:

Going back to the previous level, is there any other submethod for med2? Yes, med6, add med6 to the stack, the state at this time:

Is there a submethod for med6? Yes, med1, med1 in the stack? Do not join, discard. The state is the same as the previous step.
Going back to the previous level, is there any other submethod for med6? No, pop up the stack, add visited and sortedmethods, the status at this time:

Going back to the previous level, is there any other submethod for med2? No, pop up the stack, add visited and sortedmethods, the status at this time:

Going back to the previous level, is there any other submethod for med1? Yes, med3, med3 in visited? In, abandon.
Going back to the previous level, is there any other submethod for med1? Yes, med4, add med4 to the stack, the state at this time:

Is there any other submethod for med4? No, pop up the stack, add the visited and sortedmethods, the status at this time:

Going back to the previous level, is there any other submethod for med1? No, pop up the stack, join the visited and sortedmethods, the state at this time (ie the final state):

So the final inverse topological sorting results are: med7, med8, med3, med6, med2, med4, med1.
Generate passthrough data stream
The sortedmethods are traversed in calculatePassthroughDataflow, and through the bytecode analysis, the passthrough data stream of the method return value and parameter relationship is generated. Note the following serialization determiner, the author built three: JDK, Jackson, Xstream, according to the specific serialization determiner to determine whether the class in the decision process meets the deserialization requirements of the corresponding library, jumps if it does not match Over:
- For JDK (ObjectInputStream), class inherits the Serializable interface.
- For Jackson, does the class have a 0 parameter constructor?
- For Xstream, can the class name be a valid XML tag?
Generate passthrough data stream code:
... private static Map<MethodReference.Handle, Set<Integer>> calculatePassthroughDataflow(Map<String, ClassResourceEnumerator.ClassResource> classResourceByName, Map<ClassReference.Handle, ClassReference> classMap, InheritanceMap inheritanceMap, List<MethodReference.Handle> sortedMethods, SerializableDecider serializableDecider) throws IOException { final Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = new HashMap<>(); for (MethodReference.Handle method : sortedMethods) {//The sortedmethods are traversed in turn, and the submethod of each method is always evaluated before this method, which is achieved by the above inverse topological sorting.。 if (method.getName().equals("<clinit>")) { continue; } ClassResourceEnumerator.ClassResource classResource = classResourceByName.get(method.getClassReference().getName()); try (InputStream inputStream = classResource.getInputStream()) { ClassReader cr = new ClassReader(inputStream); try { PassthroughDataflowClassVisitor cv = new PassthroughDataflowClassVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, Opcodes.ASM6, method); cr.accept(cv, ClassReader.EXPAND_FRAMES);//Determine the relationship between the return value of the current method and the parameter by combining the classMap, the inheritanceMap, the determined passthroughDataflow result, and the serialization determiner information. passthroughDataflow.put(method, cv.getReturnTaint());//Add the determined method and related pollution points to passthroughDataflow } catch (Exception e) { LOGGER.error("Exception analyzing " + method.getClassReference().getName(), e); } } catch (IOException e) { LOGGER.error("Unable to analyze " + method.getClassReference().getName(), e); } } return passthroughDataflow; } ...
Finally generated passthrough.dat:
| 类名 | 方法名 | 方法描述 | 污点 |
|---|---|---|---|
| java/util/Collections$CheckedNavigableSet | tailSet | (Ljava/lang/Object;)Ljava/util/NavigableSet; | 0,1 |
| java/awt/RenderingHints | put | (Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object; | 0,1,2 |
Step3 Enumeration Passthrough Call Graph
This step is similar to the previous step. The gadgetinspector scans all the Java methods again, but it is no longer the relationship between the parameters and the returned result, but the relationship between the parameters of the method and the submethod it calls, that is, whether the parameters of the submethod can be Affected by the parameters of the parent method. So why do we need to generate the passthrough data stream from the previous step? Since the judgment of this step is also in the bytecode analysis, here we can only make some guesses first, as in the following example:
... private MyObject obj; public void parentMethod(Object arg){ ... TestObject obj1 = new TestObject(); Object obj2 = obj1.childMethod1(arg); this.obj.childMethod(obj2); ... } ...
If the passthrough data stream operation is not performed, it is impossible to judge whether the return value of TestObject.childMethod1 is affected by parameter 1, and it is impossible to continue to judge the parameter transfer relationship between the parent method arg parameter and the child method MyObject.childmethod.
The author gives an example:
AbstractTableModel$ff19274a.hashcode and submethod IFn.invoke:
thisparameter(0 parameter) of AbstractTableModel$ff19274a.hashcode is passed to the 1 parameter of IFn.invoke, which is represented as 0->IFn.invoke()@1- Since f is obtained by this.__clojureFnMap(0 parameter), and f is this (0 parameter) of IFn.invoke(), the 0 parameter of AbstractTableModel$ff19274a.hashcode is passed to the 0 parameter of IFn.invoke. Expressed as 0->IFn.invoke()@0
FnCompose.invoke and submethod IFn.invoke:
- arg (1 argument) of FnCompose.invoked is passed to the 1 argument of IFn.invoke, expressed as 1->IFn.invoke()@1
- f1 is the property of FnCompose (this, 0 argument), which is passed as the this (0 parameter) of IFn.invoke, expressed as 0->IFn.invoke()@1
- f1.invoke(arg) is passed as a 1 parameter to IFn.invoke. Since f1 is serialized, we can control which implementation class is IFn. Therefore, the invoke of which implementation class is called. To be able to control, that is, f1.invoke(arg) can be regarded as a 0 parameter passed to the IFn.invoke 1 parameter (here is just a simple guess, the specific implementation in the bytecode analysis, may be also reflect the author's Reasonable risk judgment), expressed as 0->IFn.invoke()@1
In this step, the gadgetinspector also uses ASM for bytecode analysis. The main logic is in the classes CallGraphDiscovery and ModelGeneratorClassVisitor. The ModelGeneratorClassVisitor traces the stack and localvar of the JVM virtual machine in the execution of the method, and finally obtains the parameter transfer relationship between the method's parameters and the submethods it calls.
Generate passthrough call graph code (temporarily omit the implementation of ModelGeneratorClassVisitor, involving bytecode analysis):
public class CallGraphDiscovery { private static final Logger LOGGER = LoggerFactory.getLogger(CallGraphDiscovery.class); private final Set<GraphCall> discoveredCalls = new HashSet<>(); public void discover(final ClassResourceEnumerator classResourceEnumerator, GIConfig config) throws IOException { Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods();//load all methods Map<ClassReference.Handle, ClassReference> classMap = DataLoader.loadClasses();//load all classes InheritanceMap inheritanceMap = InheritanceMap.load();//load inheritance graph Map<MethodReference.Handle, Set<Integer>> passthroughDataflow = PassthroughDiscovery.load();//load passthrough data flow SerializableDecider serializableDecider = config.getSerializableDecider(methodMap, inheritanceMap);//Serialization decider for (ClassResourceEnumerator.ClassResource classResource : classResourceEnumerator.getAllClasses()) { try (InputStream in = classResource.getInputStream()) { ClassReader cr = new ClassReader(in); try { cr.accept(new ModelGeneratorClassVisitor(classMap, inheritanceMap, passthroughDataflow, serializableDecider, Opcodes.ASM6), ClassReader.EXPAND_FRAMES);//Determine the current method parameter and sub-method transfer call relationship by combining classMap, inheritanceMap, passthroughDataflow result, and serialization determiner information. } catch (Exception e) { LOGGER.error("Error analyzing: " + classResource.getName(), e); } } } }
Finally generated passthrough.dat:
| parent class name | parent method | parent method info | child method's class name | child method | child method info | parent method parameter index | which field of the parameter object is passed | child method parameter index |
|---|---|---|---|---|---|---|---|---|
| java/io/PrintStream | write | (Ljava/lang/String;)V | java/io/OutputStream | flush | ()V | 0 | out | 0 |
| javafx/scene/shape/Shape | setSmooth | (Z)V | javafx/scene/shape/Shape | smoothProperty | ()Ljavafx/beans/property/BooleanProperty; | 0 | 0 |
Search For Available Sources
This step checks all methods that can be triggered based on the entry to the known deserialization vulnerability. For example, when using a proxy in a utilization chain, any invoke method that can be serialized and is a subclass of java/lang/reflect/InvocationHandler can be considered source. It also determines whether the class can be serialized based on the specific deserialization library.
Search for available sources:
public class SimpleSourceDiscovery extends SourceDiscovery { @Override public void discover(Map<ClassReference.Handle, ClassReference> classMap, Map<MethodReference.Handle, MethodReference> methodMap, InheritanceMap inheritanceMap) { final SerializableDecider serializableDecider = new SimpleSerializableDecider(inheritanceMap); for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) { if (method.getName().equals("finalize") && method.getDesc().equals("()V")) { addDiscoveredSource(new Source(method, 0)); } } } // If the class implements readObject, the ObjectInputStream is considered to be trainted for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) { if (method.getName().equals("readObject") && method.getDesc().equals("(Ljava/io/ObjectInputStream;)V")) { addDiscoveredSource(new Source(method, 1)); } } } // Any classes that extend serializable and InvocationHandler are trainted when using proxy techniques. for (ClassReference.Handle clazz : classMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(clazz)) && inheritanceMap.isSubclassOf(clazz, new ClassReference.Handle("java/lang/reflect/InvocationHandler"))) { MethodReference.Handle method = new MethodReference.Handle( clazz, "invoke", "(Ljava/lang/Object;Ljava/lang/reflect/Method;[Ljava/lang/Object;)Ljava/lang/Object;"); addDiscoveredSource(new Source(method, 0)); } } // hashCode() or equals() is an accessible entry point for standard techniques for putting objects into a HashMap for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference()))) { if (method.getName().equals("hashCode") && method.getDesc().equals("()I")) { addDiscoveredSource(new Source(method, 0)); } if (method.getName().equals("equals") && method.getDesc().equals("(Ljava/lang/Object;)Z")) { addDiscoveredSource(new Source(method, 0)); addDiscoveredSource(new Source(method, 1)); } } } // Using the comparator proxy, you can jump to any groovy Closure call()/doCall() method, all args are contaminated // https://github.com/frohoff/ysoserial/blob/master/src/main/java/ysoserial/payloads/Groovy1.java for (MethodReference.Handle method : methodMap.keySet()) { if (Boolean.TRUE.equals(serializableDecider.apply(method.getClassReference())) && inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/Closure")) && (method.getName().equals("call") || method.getName().equals("doCall"))) { addDiscoveredSource(new Source(method, 0)); Type[] methodArgs = Type.getArgumentTypes(method.getDesc()); for (int i = 0; i < methodArgs.length; i++) { addDiscoveredSource(new Source(method, i + 1)); } } } } ...
The result of this step will be saved in the file sources.dat:
| class | method | method info | trainted arg |
|---|---|---|---|
| java/awt/color/ICC_Profile | finalize | ()V | 0 |
| java/lang/Enum | readObject | (Ljava/io/ObjectInputStream;)V | 1 |
Step5 Search Generation Call Chain
This step traverses all the sources and recursively finds all submethod calls that can continue to pass the taint parameter in callgraph.dat until it encounters the method in the sink.
Search generation call chain:
public class GadgetChainDiscovery { private static final Logger LOGGER = LoggerFactory.getLogger(GadgetChainDiscovery.class); private final GIConfig config; public GadgetChainDiscovery(GIConfig config) { this.config = config; } public void discover() throws Exception { Map<MethodReference.Handle, MethodReference> methodMap = DataLoader.loadMethods(); InheritanceMap inheritanceMap = InheritanceMap.load(); Map<MethodReference.Handle, Set<MethodReference.Handle>> methodImplMap = InheritanceDeriver.getAllMethodImplementations( inheritanceMap, methodMap);//Get all subclass method implementations of methods (methods rewritten by subclasses) final ImplementationFinder implementationFinder = config.getImplementationFinder( methodMap, methodImplMap, inheritanceMap); //Save all subclass method implementations of the method to methodimpl.dat try (Writer writer = Files.newBufferedWriter(Paths.get("methodimpl.dat"))) { for (Map.Entry<MethodReference.Handle, Set<MethodReference.Handle>> entry : methodImplMap.entrySet()) { writer.write(entry.getKey().getClassReference().getName()); writer.write("\t"); writer.write(entry.getKey().getName()); writer.write("\t"); writer.write(entry.getKey().getDesc()); writer.write("\n"); for (MethodReference.Handle method : entry.getValue()) { writer.write("\t"); writer.write(method.getClassReference().getName()); writer.write("\t"); writer.write(method.getName()); writer.write("\t"); writer.write(method.getDesc()); writer.write("\n"); } } } //The method calls map, the key is the parent method, and the value is the sub-method and the parent method parameter. Map<MethodReference.Handle, Set<GraphCall>> graphCallMap = new HashMap<>(); for (GraphCall graphCall : DataLoader.loadData(Paths.get("callgraph.dat"), new GraphCall.Factory())) { MethodReference.Handle caller = graphCall.getCallerMethod(); if (!graphCallMap.containsKey(caller)) { Set<GraphCall> graphCalls = new HashSet<>(); graphCalls.add(graphCall); graphCallMap.put(caller, graphCalls); } else { graphCallMap.get(caller).add(graphCall); } } //exploredMethods saves the method node that the call chain has visited since the lookup process, and methodsToExplore saves the call chain Set<GadgetChainLink> exploredMethods = new HashSet<>(); LinkedList<GadgetChain> methodsToExplore = new LinkedList<>(); //Load all sources and use each source as the first node of each chain for (Source source : DataLoader.loadData(Paths.get("sources.dat"), new Source.Factory())) { GadgetChainLink srcLink = new GadgetChainLink(source.getSourceMethod(), source.getTaintedArgIndex()); if (exploredMethods.contains(srcLink)) { continue; } methodsToExplore.add(new GadgetChain(Arrays.asList(srcLink))); exploredMethods.add(srcLink); } long iteration = 0; Set<GadgetChain> discoveredGadgets = new HashSet<>(); //Use BFS to search all call chains from source to sink while (methodsToExplore.size() > 0) { if ((iteration % 1000) == 0) { LOGGER.info("Iteration " + iteration + ", Search space: " + methodsToExplore.size()); } iteration += 1; GadgetChain chain = methodsToExplore.pop();//Pop a chain from the head of the team GadgetChainLink lastLink = chain.links.get(chain.links.size()-1);//Take the last node of this chain Set<GraphCall> methodCalls = graphCallMap.get(lastLink.method);//Get the transfer relationship between all submethods of the current node method and the current node method parameters if (methodCalls != null) { for (GraphCall graphCall : methodCalls) { if (graphCall.getCallerArgIndex() != lastLink.taintedArgIndex) { //Skip if the pollution parameter of the current node method is inconsistent with the index of the current submethod that is affected by the parent method parameter continue; } Set<MethodReference.Handle> allImpls = implementationFinder.getImplementations(graphCall.getTargetMethod());//Get all subclass rewriting methods of the class in which the submethod is located for (MethodReference.Handle methodImpl : allImpls) { GadgetChainLink newLink = new GadgetChainLink(methodImpl, graphCall.getTargetArgIndex());//New method node if (exploredMethods.contains(newLink)) { //If the new method has been accessed recently, skip it, which reduces overhead. But this step skip will cause other chains/branch chains to pass through this node. Since this node has already been accessed, the chain will be broken here. So if this condition is removed, can you find all the chains? Removed here will encounter ring problems, resulting in an infinite increase in the path... continue; } GadgetChain newChain = new GadgetChain(chain, newLink);//The new node and the previous chain form a new chain if (isSink(methodImpl, graphCall.getTargetArgIndex(), inheritanceMap)) {//If the sink is reached, add the discoveredGadgets discoveredGadgets.add(newChain); } else { //New chain join queue methodsToExplore.add(newChain); //New node joins the accessed collection exploredMethods.add(newLink); } } } } } //Save the searched exploit chain to gadget-chains.txt try (OutputStream outputStream = Files.newOutputStream(Paths.get("gadget-chains.txt")); Writer writer = new OutputStreamWriter(outputStream, StandardCharsets.UTF_8)) { for (GadgetChain chain : discoveredGadgets) { printGadgetChain(writer, chain); } } LOGGER.info("Found {} gadget chains.", discoveredGadgets.size()); } ...
The sink method given by the author:
private boolean isSink(MethodReference.Handle method, int argIndex, InheritanceMap inheritanceMap) { if (method.getClassReference().getName().equals("java/io/FileInputStream") && method.getName().equals("<init>")) { return true; } if (method.getClassReference().getName().equals("java/io/FileOutputStream") && method.getName().equals("<init>")) { return true; } if (method.getClassReference().getName().equals("java/nio/file/Files") && (method.getName().equals("newInputStream") || method.getName().equals("newOutputStream") || method.getName().equals("newBufferedReader") || method.getName().equals("newBufferedWriter"))) { return true; } if (method.getClassReference().getName().equals("java/lang/Runtime") && method.getName().equals("exec")) { return true; } /* if (method.getClassReference().getName().equals("java/lang/Class") && method.getName().equals("forName")) { return true; } if (method.getClassReference().getName().equals("java/lang/Class") && method.getName().equals("getMethod")) { return true; } */ // If we can invoke an arbitrary method, that's probably interesting (though this doesn't assert that we // can control its arguments). Conversely, if we can control the arguments to an invocation but not what // method is being invoked, we don't mark that as interesting. if (method.getClassReference().getName().equals("java/lang/reflect/Method") && method.getName().equals("invoke") && argIndex == 0) { return true; } if (method.getClassReference().getName().equals("java/net/URLClassLoader") && method.getName().equals("newInstance")) { return true; } if (method.getClassReference().getName().equals("java/lang/System") && method.getName().equals("exit")) { return true; } if (method.getClassReference().getName().equals("java/lang/Shutdown") && method.getName().equals("exit")) { return true; } if (method.getClassReference().getName().equals("java/lang/Runtime") && method.getName().equals("exit")) { return true; } if (method.getClassReference().getName().equals("java/nio/file/Files") && method.getName().equals("newOutputStream")) { return true; } if (method.getClassReference().getName().equals("java/lang/ProcessBuilder") && method.getName().equals("<init>") && argIndex > 0) { return true; } if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("java/lang/ClassLoader")) && method.getName().equals("<init>")) { return true; } if (method.getClassReference().getName().equals("java/net/URL") && method.getName().equals("openStream")) { return true; } // Some groovy-specific sinks if (method.getClassReference().getName().equals("org/codehaus/groovy/runtime/InvokerHelper") && method.getName().equals("invokeMethod") && argIndex == 1) { return true; } if (inheritanceMap.isSubclassOf(method.getClassReference(), new ClassReference.Handle("groovy/lang/MetaClass")) && Arrays.asList("invokeMethod", "invokeConstructor", "invokeStaticMethod").contains(method.getName())) { return true; } return false; }
For each entrypoint node, all its sub-method calls, grandchild method calls, recursively form a tree. What the previous steps did is equivalent to generating the tree, and what this step does is to find a path to the leaf node from the root node, so that the leaf node is exactly the sink method we expect. . The gadgetinspector uses breadth-first (BFS) for the traversal of the tree, and skips the nodes that have already been checked, which reduces the running overhead and avoids loops, but throws away many other chains.
This process looks like this:
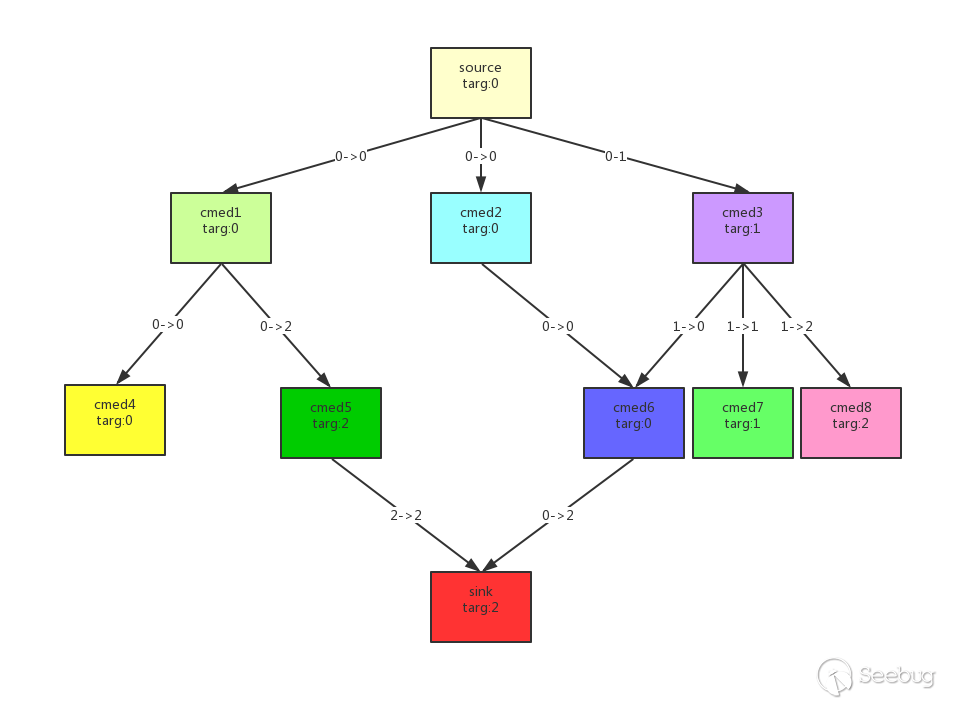
Through the transmission of the stain, the source chain from source->sink is finally found.
Note: targ indicates the index of the trainted parameter, 0->1 indicates that the 0 parameter of the parent method is passed to the 1 parameter of the child method.
Sample Analysis
Now write a concrete demo example based on the author's example to test the above steps.
The demo is as follows:
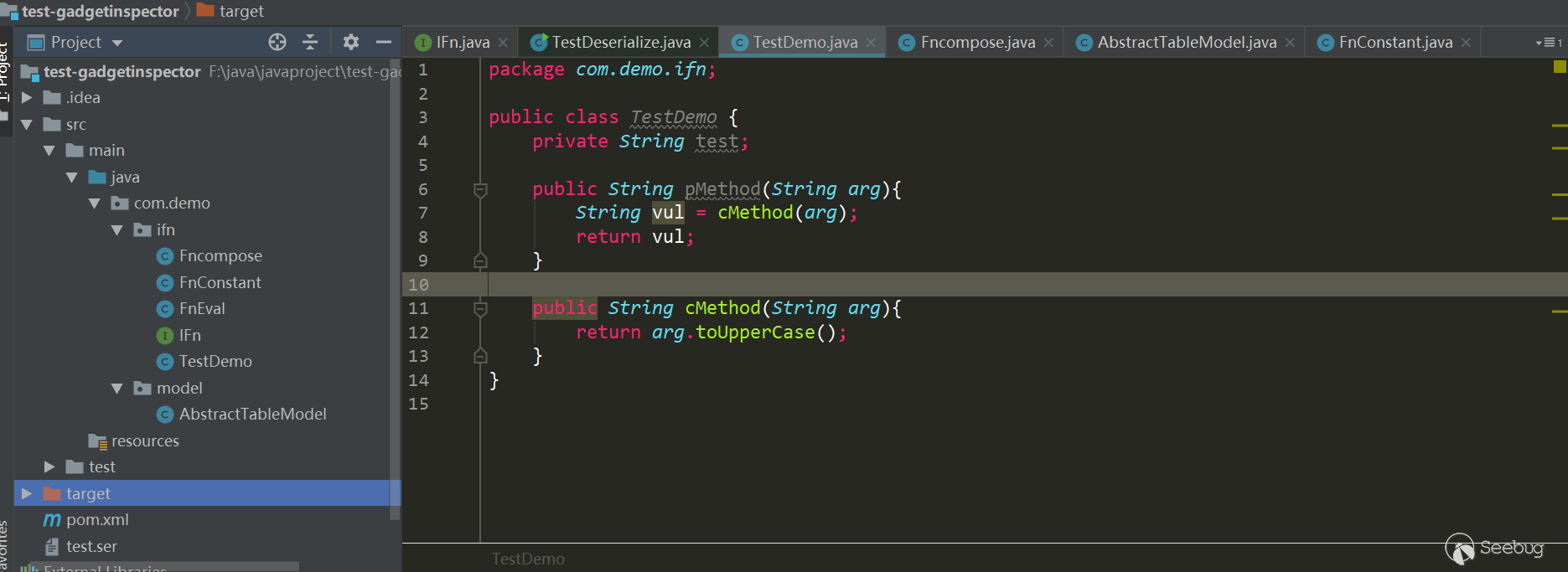
IFn.java: package com.demo.ifn; import java.io.IOException; public interface IFn { public Object invokeCall(Object arg) throws IOException; } FnEval.java package com.demo.ifn; import java.io.IOException; import java.io.Serializable; public class FnEval implements IFn, Serializable { public FnEval() { } public Object invokeCall(Object arg) throws IOException { return Runtime.getRuntime().exec((String) arg); } } FnConstant.java: package com.demo.ifn; import java.io.Serializable; public class FnConstant implements IFn , Serializable { private Object value; public FnConstant(Object value) { this.value = value; } public Object invokeCall(Object arg) { return value; } } FnCompose.java: package com.demo.ifn; import java.io.IOException; import java.io.Serializable; public class FnCompose implements IFn, Serializable { private IFn f1, f2; public FnCompose(IFn f1, IFn f2) { this.f1 = f1; this.f2 = f2; } public Object invokeCall(Object arg) throws IOException { return f2.invokeCall(f1.invokeCall(arg)); } } TestDemo.java: package com.demo.ifn; public class TestDemo { //测试拓扑排序的正确性 private String test; public String pMethod(String arg){ String vul = cMethod(arg); return vul; } public String cMethod(String arg){ return arg.toUpperCase(); } } AbstractTableModel.java: package com.demo.model; import com.demo.ifn.IFn; import java.io.IOException; import java.io.Serializable; import java.util.HashMap; public class AbstractTableModel implements Serializable { private HashMap<String, IFn> __clojureFnMap; public AbstractTableModel(HashMap<String, IFn> clojureFnMap) { this.__clojureFnMap = clojureFnMap; } public int hashCode() { IFn f = __clojureFnMap.get("hashCode"); try { f.invokeCall(this); } catch (IOException e) { e.printStackTrace(); } return this.__clojureFnMap.hashCode() + 1; } }
Note: The order of the data in the screenshot below is changed, and the data only gives the data in com/demo.
Step1 Enumerate All Classes and All Methods of Each Class
classes.dat:

Methods.dat:
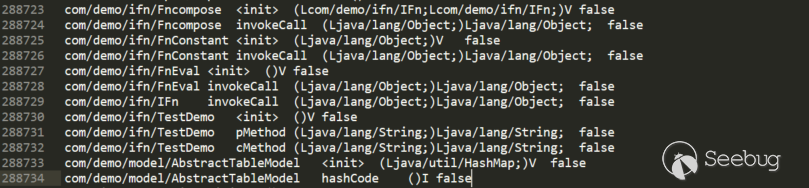
Step2 Generate Passthrough Data Stream
passthrough.dat:

It can be seen that only the FnConstant's invokeCall in the subclass of IFn is in the passthrough data stream, because several other static analysis cannot determine the relationship between the return value and the parameter. At the same time, TestMethod's cMethod and pMethod are in the passthrough data stream, which also explains the necessity and correctness of the topology sorting step.
Step3 Enumerate Passthrough Call Graph
callgraph.dat:
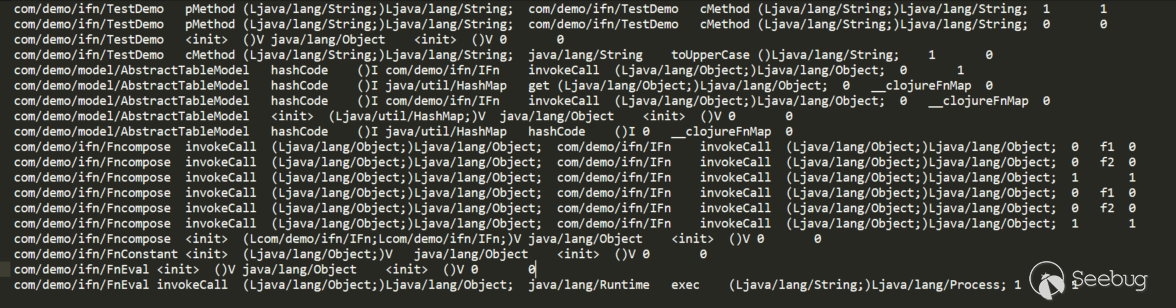
Step4 Search For Available Sources
sources.dat:

Step5 Search Generation Call Chain
The following chain was found in gadget-chains.txt:
com/demo/model/AbstractTableModel.hashCode()I (0) com/demo/ifn/FnEval.invokeCall(Ljava/lang/Object;)Ljava/lang/Object; (1) java/lang/Runtime.exec(Ljava/lang/String;)Ljava/lang/Process; (1)
It can be seen that the choice is indeed to find the shortest path, and did not go through the FnCompose, FnConstant path.
Loop Caused Path Explosion
In the fifth step of the above process analysis, what happens if you remove the judgment of the visited node, can you generate a call chain through FnCompose and FnConstant?
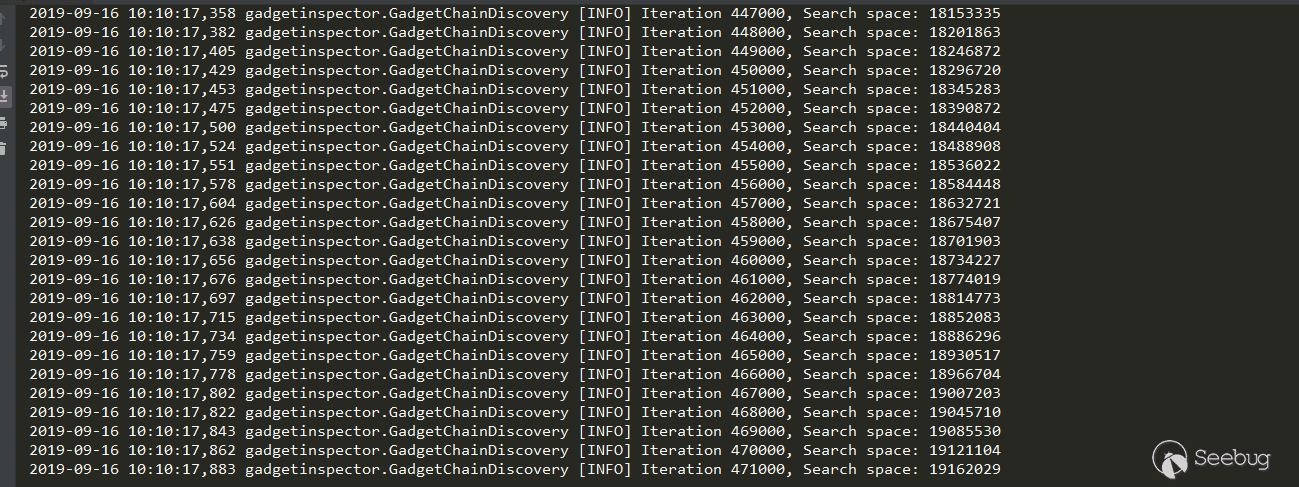
In the explosion state, the Search space is infinitely increased, and there must be a loop. The strategy used by the author is that the visited nodes are no longer accessed, thus solving the loop problem, but losing other chains.
For example, the above FnCompose class:
public class Fncompose implements IFn{ private IFn f1,f2; public Object invoke(Object arg){ return f2.invoke(f1.invoke(arg)); } }
Since IFn is an interface, it will look for a subclass of it in the call chain generation. If f1 and f2 are objects of the FnCompose class, this forms a loop.
Implicit Call
Test the implicit call to see if the tool can find out, and make some changes to FnEval.java:
FnEval.java package com.demo.ifn; import java.io.IOException; import java.io.Serializable; public class FnEval implements IFn, Serializable { private String cmd; public FnEval() { } @Override public String toString() { try { Runtime.getRuntime().exec(this.cmd); } catch (IOException e) { e.printStackTrace(); } return "FnEval{}"; } public Object invokeCall(Object arg) throws IOException { this.cmd = (String) arg; return this + " test"; } }
result:
com/demo/model/AbstractTableModel.hashCode()I (0) com/demo/ifn/FnEval.invokeCall(Ljava/lang/Object;)Ljava/lang/Object; (0) java/lang/StringBuilder.append(Ljava/lang/Object;)Ljava/lang/StringBuilder; (1) java/lang/String.valueOf(Ljava/lang/Object;)Ljava/lang/String; (0) com/demo/ifn/FnEval.toString()Ljava/lang/String; (0) java/lang/Runtime.exec(Ljava/lang/String;)Ljava/lang/Process; (1)
The toString method is implicitly called, indicating that this step of finding an implicit call is made in the bytecode analysis.
Not following Reflection Call
In the tool description of github, the author also mentioned the blind spot of this tool in static analysis, like FnEval.class.getMethod("exec", String.class).invoke(null, arg) is not Follow the reflection call, modify FnEval.java:
FnEval.java package com.demo.ifn; import java.io.IOException; import java.io.Serializable; import java.lang.reflect.InvocationTargetException; public class FnEval implements IFn, Serializable { public FnEval() { } public static void exec(String arg) throws IOException { Runtime.getRuntime().exec(arg); } public Object invokeCall(Object arg) throws IOException { try { return FnEval.class.getMethod("exec", String.class).invoke(null, arg); } catch (NoSuchMethodException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } return null; } }
After testing, it was not found. But change FnEval.class.getMethod("exec", String.class).invoke(null, arg) to `this.getClass().getMethod("exec", String.class).invoke(null, arg ) This kind of writing can be found.
Special Grammar
Test a special syntax, such as lambda syntax? Make some changes to FnEval.java:
FnEval.java: package com.demo.ifn; import java.io.IOException; import java.io.Serializable; public class FnEval implements IFn, Serializable { public FnEval() { } interface ExecCmd { public Object exec(String cmd) throws IOException; } public Object invokeCall(Object arg) throws IOException { ExecCmd execCmd = cmd -> { return Runtime.getRuntime().exec(cmd); }; return execCmd.exec((String) arg); } }
After testing, this chain of utilization was not detected. Explain that the current grammar analysis section has not yet analyzed the special grammar.
Anonymous Inner Class
Test the anonymous inner class and make some changes to FnEval.java:
FnEval.java: package com.demo.ifn; import java.io.IOException; import java.io.Serializable; public class FnEval implements IFn, Serializable { public FnEval() { } interface ExecCmd { public Object exec(String cmd) throws IOException; } public Object callExec(ExecCmd execCmd, String cmd) throws IOException { return execCmd.exec(cmd); } public Object invokeCall(Object arg) throws IOException { return callExec(new ExecCmd() { @Override public Object exec(String cmd) throws IOException { return Runtime.getRuntime().exec(cmd); } }, (String) arg); } }
After testing, this chain of utilization was not detected. Explain that the current parsing block does not yet have an analysis of anonymous inner classes.
Sink->Source?
Since source->sink, can we sink->source? Since source and sink are known when searching for source->sink, if sink and source are known when searching for sink->source, then source->sink and sink->source seem to be no different. If we can summarize the source as a parameter-controllable feature, the sink->source method is a very good way to not only be used in the deserialization vulnerability, but also in other vulnerabilities (such as templates injection and so on). But there are still some problems here. For example, deserialization treats this and the properties of the class as 0 arguments, because these are controllable during deserialization, but in other vulnerabilities these are not necessarily controllable. .
I still don't know how to implement it and what problems it will have. Don't write it for the time being.
Defect
At present, I have not done a lot of testing, I just have analyzed the general principle of this tool from a macro level. Combining Ping An Group analysis article and the above test can now summarize several shortcomings (not only these defects):
- callgraph generation is incomplete
- The call chain search result is incomplete due to the search strategy
- Some special grammars, anonymous inner classes are not yet supported
- ...
Conceive and Improve
-
Improve the above defects
-
Continuous testing in conjunction with known utilization chains (eg ysoserial, etc.)
-
List all chains as much as possible and combine them with manual screening. The strategy used by the author is that as long as there is a chain through this node, other chains will not continue to search through this node. The main solution is the last call chain loop problem, which is currently seen in several ways:
-
DFS+ maximum depth limit
- Continue to use BFS, manually check the generated call chain, remove the invalid callgraph, and repeat the run
- Calling the chain cache (this one has not yet understood how to solve the loop specifically, just saw this method)
My idea is to maintain a blacklist in each chain, checking for loops every time. If a loop occurs in this chain, the nodes that cause the loop will be blacklisted and continue to let it go. . Of course, although there is no ring, there will be an infinite growth of the path, so it is still necessary to add a path length limit.
- Try the implementation of sink->source
Multi-threaded simultaneous search for multiple use chains to speed up
- ...
At last
In the principle analysis, the details of the bytecode analysis are ignored. Some places are only the results of temporary guessing and testing, so there may be some errors. The bytecode analysis is a very important part. It plays an important role in the judgment of the stain and the transfer of the stain. If there is a problem in these parts, the whole search process will have problems. Because the ASM framework has high requirements for users, it is necessary to master the knowledge of the JVM to better use the ASM framework, so the next step is to start learning JVM related things. This article only analyzes the principle of this tool from a macro level, but also adds some confidence to yourself. At least understand that this tool is not incomprehensible and cannot be improved. At the same time, I will be separated from the tool afterwards. It is also convenient, and others can refer to it if they are interested in this tool. After I familiar with and can manipulate Java bytecode, go back and update this article and correct the possible errors.
If these ideas and improvements are really implemented and verified, then this tool is really a good helper. But there is still a long way to go before these things can be realized. I haven imagined so many problems before I started to implement them. I will encounter more problems when I realize them. But fortunately, there is a general direction, and the next step is to solve each link one by one.
Reference
- https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains.pdf>
- https://i.blackhat.com/us-18/Thu-August-9/us-18-Haken-Automated-Discovery-of-Deserialization-Gadget-Chains-wp.pdf
- https://www.youtube.com/watch?v=wPbW6zQ52w8
- https://mp.weixin.qq.com/s/RD90-78I7wRogdYdsB-UOg
About Knownsec & 404 Team
Beijing Knownsec Information Technology Co., Ltd. was established by a group of high-profile international security experts. It has over a hundred frontier security talents nationwide as the core security research team to provide long-term internationally advanced network security solutions for the government and enterprises.
Knownsec's specialties include network attack and defense integrated technologies and product R&D under new situations. It provides visualization solutions that meet the world-class security technology standards and enhances the security monitoring, alarm and defense abilities of customer networks with its industry-leading capabilities in cloud computing and big data processing. The company's technical strength is strongly recognized by the State Ministry of Public Security, the Central Government Procurement Center, the Ministry of Industry and Information Technology (MIIT), China National Vulnerability Database of Information Security (CNNVD), the Central Bank, the Hong Kong Jockey Club, Microsoft, Zhejiang Satellite TV and other well-known clients.
404 Team, the core security team of Knownsec, is dedicated to the research of security vulnerability and offensive and defensive technology in the fields of Web, IoT, industrial control, blockchain, etc. 404 team has submitted vulnerability research to many well-known vendors such as Microsoft, Apple, Adobe, Tencent, Alibaba, Baidu, etc. And has received a high reputation in the industry.
The most well-known sharing of Knownsec 404 Team includes: KCon Hacking Conference, Seebug Vulnerability Database and ZoomEye Cyberspace Search Engine.
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1046/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1046/