
阅读: 18
一、背景知识介绍
为了比较agent的性能,主要查看了两个指标:为实现其目标而采取的模拟步骤数,以及跨训练时期模拟步骤的累积奖励。通过步骤梳理与累计的分数,评估最先进的强化算法,以研究自主代理如何与它们交互并从中学习。
强化学习的目标是希望个体从环境中获得的总奖励最大,即我们的目标不是短期的某一步行动之后获得最大的奖励,而是希望长期地获得更多的奖励。比如一个婴儿可能短期的偷吃了零食,获得了身体上的愉悦(即获取了较大的短期奖励),但是这一行为可能在某一段时间之后会导致父母的批评,从而降低了长期来的总奖励。
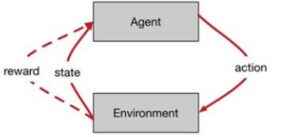
图1 个体与环境相互作用
二、CyberBattleSim框架介绍
- 抽象级别高,只需要建模系统重要的方面;例如应用层网络通信相比于包级别的网络模拟,忽略了低层的信息。
- 灵活性:定义一个新的机器是很容易的,不需要考虑底层的驱动等,可以限制动作空间为可以管理且相关的子集。
- 全局的状态可以有效地捕获,从而简化调试与诊断。
- 轻量:运行在一台机器/进程的内存中。
CyberBattleSim的仿真固然简单,但是简单是具有优势的。高度抽象的性质使得无法直接应用于现实系统,从而防止了潜在的恶意训练的自动化代理使用。同时,可以使我们更专注于特定的安全性方面,例如研究和快速实验最新的机器学习和AI算法。
当前的内网渗透实现方式侧重于横向移动,希望理解网络拓扑和配置并施加影响。基于这一目标,没有必要对实际的网络流量进行建模。
该项目主要采用了免模型学习(Model-Free),虽然在效率上不如有模型学习(Model-Based)(缺点是如果模型跟实际场景不一致,那么在实际使用场景下会表现的不好),但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。
CyberBattleSim中的强化学习建模:
- 有向图,结点表示计算机,边表示其他结点的知识或节点间通信。
- 环境:状态就是网络,单个代理,部分可观测(代理无法观测到所有的结点和边),静态的,确定性的,离散的,post-breach
- 行动空间(代理可以逐步探索网络):本地攻击,远程攻击,认证连接
- 观测空间:发现结点,获取结点,发现凭证,特权提升,可用攻击
-
奖励:基于结点的内在价值,如SQL server比测试机器重要

图2 强化学习建模
- 网络中结点的属性:如Windows,Linux,ApacheWebSite,MySql,nginx/1.10.3,SQLServer等。
- 开放的ports:如HTTPS,SSH,RDP,PING,GIT等。
- 本地漏洞包括:CredScanBashHistory,CredScan-HomeDirectory,CredScan-HomeDirectory等。
- 远程漏洞包括:ScanPageContent,ScanPageSource,NavigateWebDirectoryFurther,NavigateWebDirectory等。
- 防火墙配置为:允许进出的服务为RDP,SSH,HTTPS,HTTP,其他服务默认不允许。
- 定义了部分奖励与惩罚:发现新结点奖励,发现结点属性奖励,发现新凭证奖励,试图连接未打开端口的处罚,重复使用相同漏洞的惩罚等。
本地agent如下,定义了其包含的漏洞,漏洞类型,漏洞描述,端口,价值,花费,服务等。
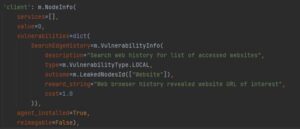
图3 agent定义
每一个step中,都会执行下图中的action(行动),observation(观察状态),wrapper(通过当前状态反馈做出改变)。
在强化学习训练的时候,一开始会让Agent更偏向于探索Explore,并不是哪一个Action带来的reward最大就执行该Action,选择Action时具有一定的随机性,目的是为了覆盖更多的Action,尝试每一种可能性。等训练很多轮以后各种状态下的各种Action基本尝试完以后,这时候会大幅降低探索的比例,尽量让Agent更偏向于利用Exploit,哪一个Action返回的reward最大,就选择哪一个Action。
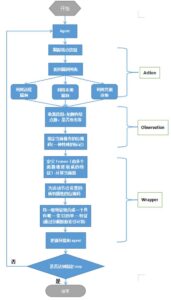
图4 强化学习步骤
三、 一个CyberBattleSim实例过程
该实例通过强化学习算法查找结点及其漏洞,由初始节点通过本地漏洞探测到一个Website节点,step=6,当前reward=6,其中的step如图5上所示,左下图横坐标为step,纵坐标为reward,右下图为网络拓扑图。此时结点client为红色已拥有,结点Website为绿色未拥有。
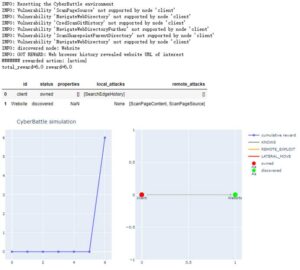
图5 强化学习过程1
再经过6个step后如图6,通过WEBSITE的漏洞ScanPageContent发现了结点GitHubProject,获得reward=6,当前总reward=12。(注意,这部分重复了三次step发现结点Website,说明该算法也有弊端)
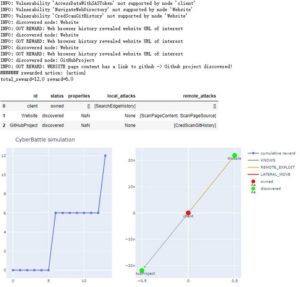
图6 强化学习过程2
最终从agent节点通过各种本地攻击,远程攻击和连接其他节点,获取到网络中存在漏洞的节点如图7,当前step=5600,reward=431。
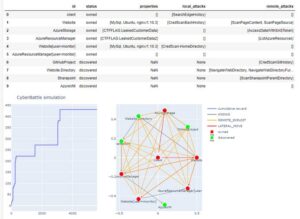
图7 强化学习过程3
四、项目中强化学习算法比较

图8 不同算法获取网络所有权的迭代次数
如图9提供了另一种比较方法,即跨训练时期模拟步骤的累积奖励。实线显示中位数,而阴影表示一个标准差。这再次显示了某些算法(红色Exploiting DQL、蓝色Tabular Q-learning和绿色DQL)的表现明显优于其他算法(橙色Credential lookups)。
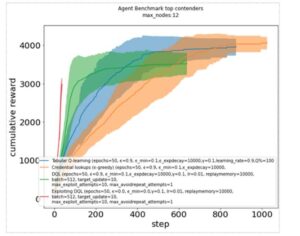
图9 不同算法经过训练后的奖励
五、CyberBattleSim评估
2.该项目的攻击方式包括本地攻击,远程攻击和连接其他节点,每种攻击只举了几个例子,然而实际过程中远远不止于此,需要学习训练就会是一个很耗时的过程。且该项目采用免模型学习(虽然该方法会更适用于当前网络环境),实际渗透中因为攻击方式众多,需要训练的时间也会更长,具体学习渗透的时间犹未可知。
3.CyberBattleSim项目提供的只是自动化攻击内网渗透项目当中必不可少的沙盒,只是一个用户产生虚拟攻防场景数据的工具,距离真实的项目还有很长的路要走,现有的强化学习最好的例子只存在于游戏(2016年:AlphaGo Master 击败李世石,使用强化学习的 AlphaGo Zero 仅花了40天时间;2019年4月13日:OpenAI 在《Dota2》的比赛中战胜了人类世界冠军),对于复杂的自动化攻击并不一定能胜任。
3.该项目相比于其他强化学习自动化渗透项目:如DEEPEXPLOIT框架,AutoPentest-DRL框架,这两个框架都使用了强化学习,nmap扫描,Metasploit攻击,但是他们并没有有效利用强化学习,主要原因在于他们的action只是根据各种漏洞对应相应的payload获取shell,该模式更像是监督学习,因为没有环境观察与反馈。CyberBattleSim项目有它自己的优势,虽然该项目并没有实现真实攻击,但是该项目完整地诠释了强化学习的步骤(包含观察环境与反馈),如果能开发出合适的工具使用,那么就可以实现更高效,准确度更高的渗透。
1.实现一个类似端口扫描操作(非确定性)的nmap,用来收集信息,而且该步骤不仅仅是渗透的开始工作,在渗透过程中也需要更新信息。
2.与现有的攻击工具结合或者开发更适合强化学习模型的攻击工具,用来真实的攻击。
3.奖励的定义也是强化学习中重要的一项内容,可以通过通用漏洞评分系统(CVSS)的组成部分所确定的漏洞得分来定义。
六、总结
本文针对自动化内网渗透这一方向对微软的开源项目CyberBattleSim做了介绍,通过对其内部原理和源码的分析,笔者指出了该项目的优势,存在的问题及其发展前景。该项目只是自动化攻击内网渗透项目中必不可少的沙盒,自动化渗透还有很长的路要走。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。