
阅读: 14
一、背景知识介绍
本部分对DE(将DeepExploit简称为DE)利用到的核心工具做简单介绍,分为metasploit介绍和强化学习算法介绍,均为入门介绍,熟悉的读者可自行忽略。
1.1 metasploit简介
Metasploit是一款非常流行的渗透测试框架,里面包含了大量知名软件漏洞利用工具,其payload利用效率非常高效,并且还支持用户自定义开发漏洞利用模块。在使用metasploit时需要设置一些比较重要的参数:
漏洞利用模块(exploit模块),不同的漏洞需要选择不同的模块进行利用,而同一服务,往往存在多种漏洞,为了验证漏洞存在,往往需要设置不同漏洞利用模块进行测试。
target,每个exploit模块都需要设置很多参数,其中target为比较重要的参数(metasploit会设定一个默认值),代表不同的操作系统类型,如图1所示,target值为0代表设定目标的操作系统为 Windows 2000 SP4。

payload, 该参数为exploit模块中需要设置的另一个重要参数(也会有默认值),意为攻击进入目标主机后需要在远程系统中运行的恶意代码,其中,Shellcode是payload中的精髓部分,攻击者可以通过shellcode建立与目标系统的shell连接,方便地控制目标机。图2为payload样例。

以上3个参数为DE框架在运用强化学习算法进行渗透测试时所需选择的重要参数。
1.2 强化学习算法简介
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益,是除了监督学习和非监督学习之外的第三种基本的机器学习方法。其基本框架如图3所示,基本流程为:智能体(agent)通过观察环境(Environment)的状态(State)做出行动(action),该行动会作用于环境,改变环境的状态,并且产生相关联的奖励(reward),智能体通过观察新的状态和奖励来进行下一步动作,由此循环。在这个过程中,智能体会不断得到奖励(有好的有坏的),从而不断进化,最终能以利益最大的目标实施行动。
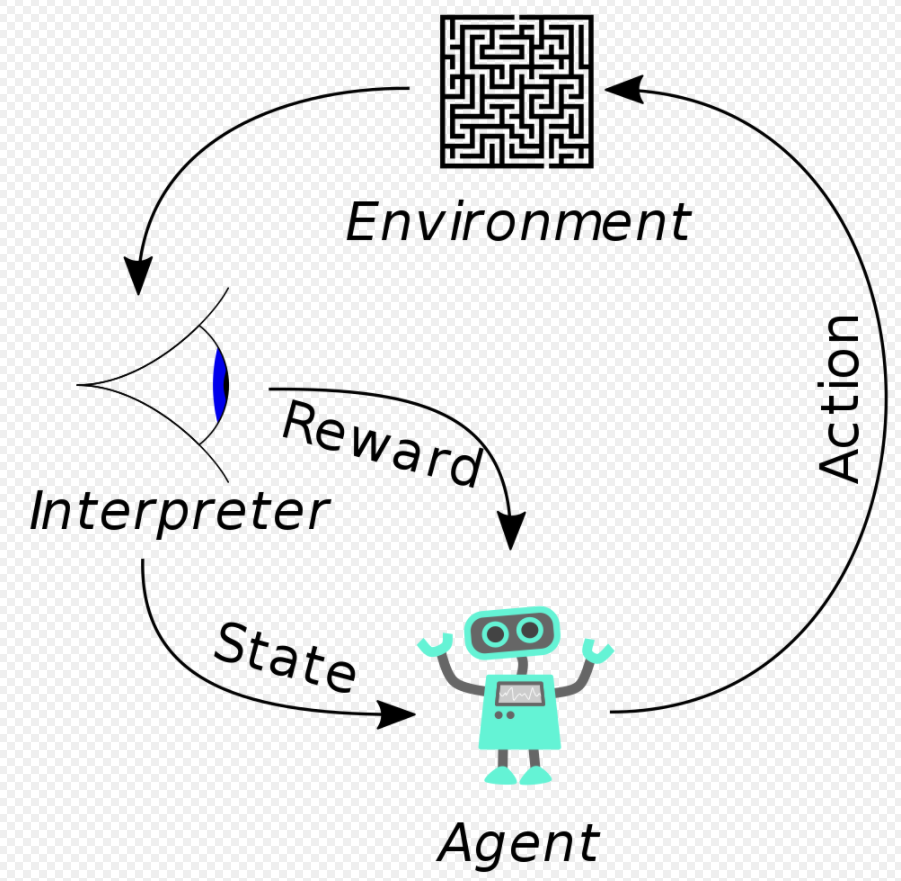
强化学习有几大要素,这些要素的定义至关重要,不同场景下,要素的定于也不尽相同,而这些要素的合理定义往往也决定这强化学习算法能否生效。具体来说,想要使用强化学习来求解一个问题,首先需要定义如下3大要素:
- State(状态空间),state通常是算法的输入,包含agent作出action所需要的所有信息,需要满足马尔科夫性质,即agent可以仅根据当前做出动作,无需考虑过去的状态。
- Action(动作空间),action一般就是算法的输出,action是agent能够对环境产生影响的手段,所以一个任务的action设置的最基本要求是能够对environment产生有效影响。
- Reward(收益),reward是算法学习的指导,reward的设置往往决定了算法的最终效果是否理想,因此如何有效的设置reward也成为了强化学习应用的一个重要问题。
在对以上3大要素进行合理定义后,算法(如A3C算法)才算有使用的基础。由于强化学习算法众多,也不是本文的关键,笔者将不再展开论述。总之,强化学习任务中,3大要素的定义至关重要,定义越合理,问题的解决程度就越高。
温馨提示:读者可以通过对DE框架对3大要素的定义,判断其合理性。
二、自动化渗透测试与DeepExploit框架
- 自动化渗透测试
随着安全市场的不断扩大,渗透测试的需求也在不断增长,有研究预估到2025年,全球渗透测试的市场份额将会达到45亿美元(2020年17亿美元),相应的,渗透人才也极度短缺 [1],在这种背景下,国内外很多很多公司都有研发自动化渗透测试工具来满足市场需求、缓解人才短缺的压力。
自动化渗透测试,顾名思义,即自动化完成渗透测试的过程。从内容上讲,一般来说人工渗透测试需要包含:信息收集、漏洞探测、漏洞利用、权限维持、后渗透、生成报告等常规步骤,一般市面上自动化渗透测试产品也都包含这些功能,从能力上讲,自动化工具需要回答两个核心问题:1. 自动化工具能发现多少风险点;2. 自动化工具对渗透测试的效率提升有多大。这两个问题的解决程度决定了自动化工具的优劣。
在渗透测试的过程中,“漏洞探测”往往是最耗时的一步。为了发现目标系统的安全问题,渗透测试工程师一般先用漏扫工具对目标系统进行扫描测试,若未发现问题,则需要进行长期的人工渗透过程。理论上讲,为了提升渗透效率,那么自动化渗透的核心价值应体现于现实中最耗时耗力的部分(漏洞探测)上,将上述长期的人工渗透过程进行自动化。但是就目前来讲,大部分自动化渗透产品的做法是简单地将漏扫的结果与相关的利用工具相结合,从而达到自动化渗透的效果,而“人工渗透的过程”并未有效实现自动化。
自动化渗透工具能多大程度解决上述问题呢?我们通过一个开源的自动化渗透框架DeepExploit来分析自动化渗透测试领域当前的前沿进展(DeepExploit应该具有代表性)。
- DeepExploit框架简介
DeepExploit是一种基于强化学习的自动化渗透框架,由日本的一家名为MBSD的公司研发,在自动化渗透方向为大众所熟知,在github上的star数量高达1600+,其开发人员曾在很多知名大会上介绍过该工具,如:DEFCON 2018,Black Hat 2018等,这些演讲进一步拓展了该工具的知名度。
DeepExploit底层使用Metasploit进行渗透,使用强化学习技术来提升渗透效率,可以达到“给定目标IP,输出反弹shell”的效果,除了“权限维持”功能外,其他步骤均已实现全自动,根据github页面介绍,特点如下:
- 高效渗透。利用机器学习,最佳情况下,只需一次利用便可成功getshell;
- 深度渗透。可以内网扩散;
- 自学习。利用强化学习进行自学习,无需准备数据;
- 学习时间快。利用A3C算法加速学习;
- 强大的情报收集能力;包含:端口扫描,服务及版本识别(包含nmap识别,机器学习识别,爬虫识别)
针对这些特点,本文将给出详细的分析,以向读者展现该工具的适用性与实用性。
三、DeepExploit框架深度分析
本小节中,我们首先介绍DE框架的整体运行流程,然后对照源码,说明每部分源码的作用,最后总结DE框架的优缺点,提出改进方向。
3.1 DeepExploit框架流程分析
我们先来通过官网[1]的架构图(图4)来了解DE的核心流程,从图中我们可以看到DE通过RPC协议与metasploit进行通信,调用metasploit进行渗透,其核心在于强化学习算法(A3C算法)的使用,该算法整体上分为两个步骤:训练(testing)和测试(training),在训练阶段,会利用框架对靶标进行渗透测试,并保存训练数据,训练好A3C模型,在测试阶段,根据训练好的强化学习模型,对目标进行高效的渗透(以足够少的尝试次数完成对目标的渗透)。
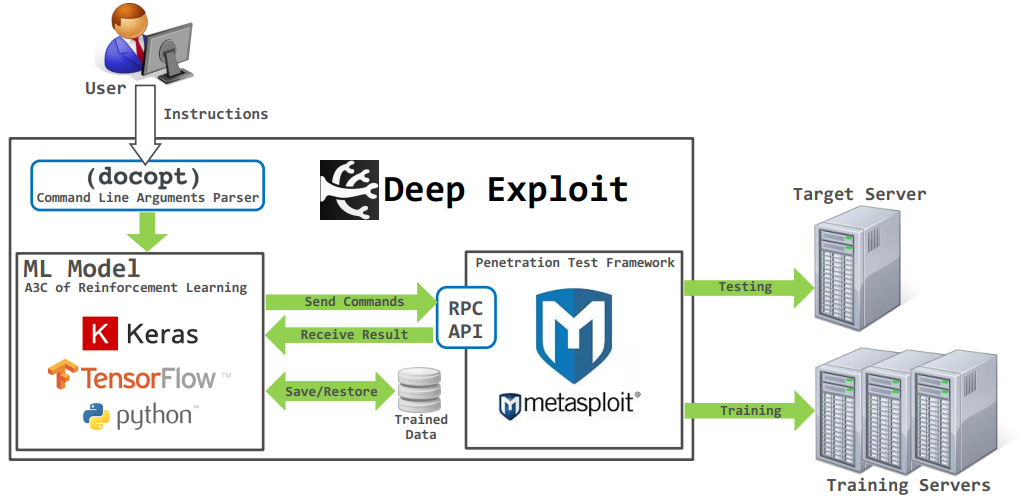
整体上该框架图看似符合其宣称的“利用强化学习算法进行高效渗透测试”,接下来我们通过对其源码的分析画出详细的框架流程图(图5),其中绿色方框为框架内置的支撑数据,蓝色方框代表主要流程,黄色方框为判断逻辑。框架整体上包含渗透测试过程的:信息收集、漏洞探测、漏洞利用、后渗透、生成报告的几个步骤。
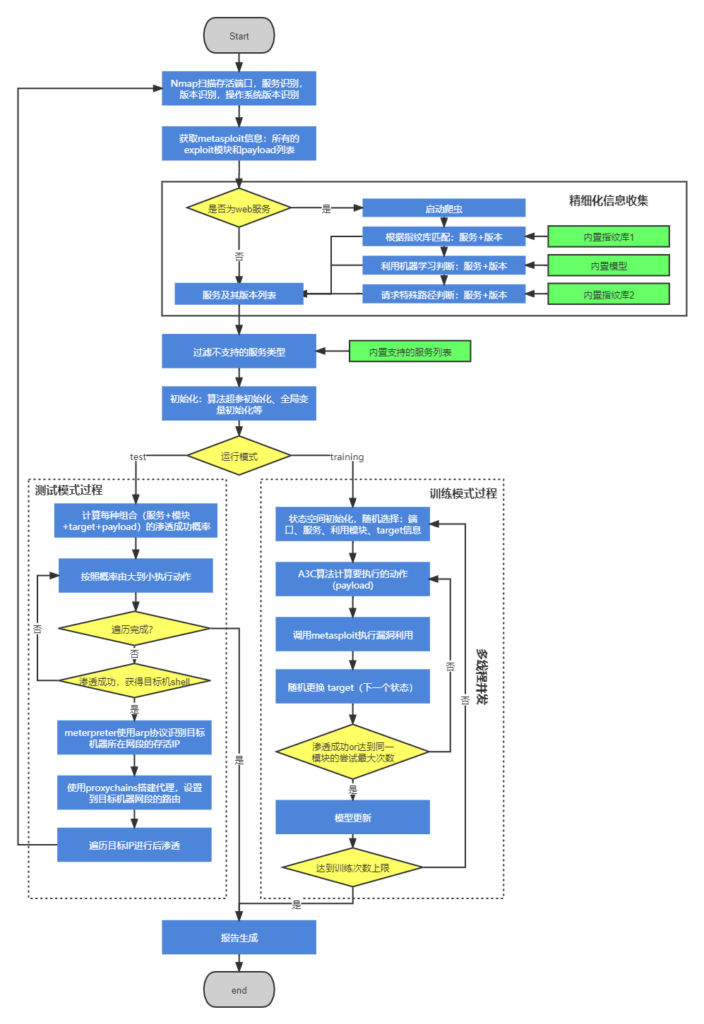
在信息收集过程中,主要目标是获取目标系统上运行的服务及其版本号,为了实现这一目标,DE首先使用nmap工具进行简单的服务识别,当遇到web服务时,会启动爬虫,爬取目标页面(默认只爬到第二层页面),通过内置的指纹库1和机器学习模型识别出页面背后的服务,并且为了避免爬虫的遗漏,会通过内置的指纹库2访问主流服务的路径,若路径存在则代表服务存在,从而得到目标机器完整的服务及其版本信息。框架只支持一些特定服务的渗透,会过滤掉不支持的服务类型,最终得到要进行渗透测试的服务列表。该部分为官网所说的特点5(强大的情报收集能力)。
图5所示的“测试模式过程”和“训练模式过程”为DE的核心部分,也是使用强化学习算法的部分。为了使用强化学习,DE框架将强化学习的3大要素中定义如下:
- 状态空间。 DE用5个状态表示其状态空间,在代码中表示为(ST_OS_TYPE,ST_SERV_NAME,ST_SERV_VER,ST_MODULE,ST_TARGET),分别代表:操作系统版本,端口上服务名称,服务版本,要利用msf的模块名称编号,模块中的target参数。
- 动作空间。DE的动作空间为metasploit模块中所有payload集合。笔者使用的metasploit版本为v6.1.9,payload总数为593个。
- 收益。DE将收益定义为3种:R_GREAT=100,R_GOOD = 1,R_BAD = -1,R_GREAT代表可以进行后渗透测试(返回的shell类型为meterpreter,而DE利用meterpreter进行后渗透),R_GOOD代表能返回shell但是不能获得meterpreter shell(意指无法利用该机器进行后渗透),R_BAD代表漏洞利用失败。实际上,在DE中,后渗透模块没有开发完善,只要能返回shell,都会被赋予最大收益GREAT。
在训练模式中,DE首先进行状态空间初始化,其中ST_OS_TYPE是固定不变的,ST_SERV_NAME和ST_SERV_VER会在随机选择信息收集阶段中识别到的设备上的服务和版本,确定ST_SERV_NAME后,在metasploit中根据语句“search name: + ST_SERV_NAME type:exploit app:server”返回的可利用模块列表,随机选择一个模块确定ST_MODULE,ST_TARGET在模块可选的target列表中随机选择;确定状态后,A3C算法会计算每个payload的概率,选择一个概率最高的payload后,利用以上信息调用metasploit进行漏洞利用;当渗透失败时,会随机更换target,由于不用target对应的可利用payload不一样,此时需要重新利用A3C算法计算概率最大的payload进行利用,当该步骤到一定次数还未成功,会再次进行状态空间初始化,对其他的服务、模块进行尝试。整个训练过程采用多线程并发的方式进行,线程之间没有任何通信机制,以此方式进行算法的并行化。
测试模式为在实际环境中使用的模式,相比于训练模式多了后渗透这一步。测试模式首先计算每种状态空间下,payload的概率,根据该概率由大到小的顺序调用metasploit进行渗透,一旦渗透成功,则进行后渗透;在后渗透的过程中,首先利用arp协议进行内网存活主机识别,然后调用metasploit框架中自带的代理模块“auxiliary/server/socks4a”搭建代理,对新识别的到的主机进行下一步渗透,直到没有新的主机出现。
在训练模式或测试模式结束后,会生成报告,内容包含渗透成功的主机上所有漏洞信息和相关metasploit的利用参数。
3.2 DeepExploit框架点评
不可否认,DeepExploit框架确实能够进行自动化渗透,但是通过对强化学习的介绍和DE框架详细流程的介绍,对于其号称的“高效”渗透,仍需打个问号。
笔者认为DE框架最大问题在于使用的是伪强化学习,虽然整个框架看起来是强化学习环境+智能算法+反馈 这样的路线,但是在问题定义上出现了根本性的问题:动作和状态之间完全割裂。在背景知识中我们提到,强化学习中,动作需要对环境产生有效影响,从而产生环境状态的改变,但是DE框架的状态转移完全是随机的,跟动作无关。这一点不仅与强化学习的概念相左,也无法契合渗透测试的流程,渗透测试中,渗透人员会根据上一步的执行情况来决定下一步要执行的动作,而DE框架的状态转移是随机的,意味着执行的动作也是随机的。
该问题也说明了DE框架对于状态空间和动作空间的定义是有问题的,在该定义下,强化学习算法并不能有效发挥作用。
除了该核心问题,DE框架在设计上仍然有些瑕疵,笔者将之枚举,使用该框架的读者朋友可以关注。
1. 服务支持问题。DE框架的“config.ini”文件中限定了DE只支持如下服务的渗透:[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@[email protected]@upnp。一方面,metasploit所支持的服务远远不止这些,笔者不理解DE为什么需要限定服务,因为DE调用metasploit的接口进行渗透,对于所有metasploit支持的服务,DE理论上也可以支持;另一方面,DE没有做不同软件对同一服务在名称上的映射,具体来说,DE使用nmap进行服务识别,将服务名称在metasploit中搜索可以利用的渗透模块,可nmap和metasploit对于同一服务往往使用不同名称进行表示,不同版本之间也有差异,如smb服务:在metasploit搜索关键词“smb”即可,而nmap对smb服务的识别结果为“microsoft-ds” ,该关键词在metasploit中无效。经过笔者的手动测试,大多数流行服务在两个软件中都存在服务名称不一致的问题,这也直接导致了DE框架可用性的大幅下降,甚至连传播甚广的“MS17-010”永恒之蓝漏洞都无法利用。
2. 服务识别问题。DE框架在遇到web服务时,会开启爬虫,默认只爬到第二层页面,按照:匹配指纹库1,机器学习识别,访问指纹库2的流程进行服务识别。整个流程特别耗时,并且机器学习算法(朴素贝叶斯)在笔者使用过程中几乎是0贡献,该流程与一般漏扫的服务流程基本一致, “强大的情报收集能力”能力(特点5)并未体现。
3. 算法逻辑问题。除了上述算法使用不符合强化学习的逻辑外,DE还有一些逻辑问题会影响渗透效果:第一,DE会随机选择target尝试进行渗透,但是根据前文介绍,target代表的是操作系统,而操作系统DE在信息收集阶段已经识别了,并且作为状态中的一个变量ST_OS_TYPE,那么还有什么必要进行所有target的尝试呢?第二,DE将“是否返回metepreter shell”作为漏洞是否利用成功的标志从而进行后渗透,既然如此为什么要尝试其他类型的payload呢?笔者使用metasploit中的payload共计593种,meterpreter shell共计167种。因为这两种逻辑问题,保守估计,DE起码进行了至少10倍以上的无效尝试;除却无效尝试,DE还存在“漏尝试”的情况,有些payload始终未被尝试,如图5所示,在训练模式下,A3C算法对每个payload计算概率,对利用成功率最大的payload进行尝试,这种方式直接导致,在同一模型、同一状态下,始终测试同一个payload,虽然模型在训练的时候会动态更新,但是这种设计思路仍会存在某些payload未曾测试的情况,遗漏有可能利用成功的payload。总结来说,DE的算法逻辑增加了大量的无效尝试,并且还有可能会漏掉能够利用成功的尝试。
4. 程序设计问题。DE在训练模式中使用了多线程进行加速,但是线程之间完全独立,metasploit渗透的各个参数(服务+模块+target)又都是随机的,这种设计机制会导致:同一线程内出现重复的尝试,不同线程直接出现重复的尝试。在一次使用情况中,笔者至少遇到了完全相同的利用尝试20次(默认开的20线程),这种大量的重复尝试极大降低了渗透效率。
5. 渗透目标问题。DE框架判定渗透成功的标志为“返回了meterpreter shell”,计算的是在“服务,模块,target”确定的情况下,不同payload的成功概率,但是在一般渗透测试过程中,需要判断的往往是“某种漏洞能否利用成功”,换句话说,即metasploit中的某个模块能否利用成功,至于利用成功后的动作(payload)不是重点。若能改变渗透目标,计算每个模块的成功概率,会更加符合实际需求。
上述问题会直接导致DE的可用性下降,所幸这些问题并不难解决,优化后可大幅提升漏洞利用效率。
最后,笔者对于官网所说特点2(深度渗透)和特点3(自学习)做一些补充说明:特点2中所说的深度渗透属于后渗透,DE框架并没有完全实现,功能尚不能顺利使用;自学习并不是说真的不需要训练数据,需要自己搭建靶场,程序运行过程中会自动产生所需数据。
3.3 DeepExploit改进方向
若需要基于DeepExploit进行自动化渗透,笔者认为可以按照如下顺序进行优化,进一步提升渗透效率。
- 解决上小节中所述的“瑕疵”,如无效尝试、重复尝试、遗漏尝试、服务支持问题等等,其中服务支持问题可能难度较大,不同软件之间对同一服务的命名往往存在一定差异,可以考虑机器学习的方式进行识别。
- 重新定义强化学习的3大要素。目前的定义方式不适合使用强化学习算法,需要对状态空间、动作空间,甚至收益做重新定义,从而使用强化学习算法。对于强化学习算法使用必要性,笔者认为强化学习算法与渗透测试的过程天然吻合,都需要根据当前状态来判断下一步的动作,且每一个动作是否成功、最终目标都相对明确,因此可以考虑进行周密设计。
- 使用传统机器学习算法。按照DE框架对状态和动作的定义(动作对状态不起作用),可以使用传统机器学习算法,计算每种状态下,不同动作的成功概率。相较于强化学习算法,传统机器学习算法更适用于DE框架。
3.4 小节
本小节详细介绍了DeepExploit框架的核心逻辑,并且分析了其优劣,给出了改进方向。总结来说DeepExploit在功能上能够实现自动化渗透,但其宣称的强化学习算法并没有被有效使用,框架整体上也有一些待完善的地方。从核心功能看,DeepExploit目前仅比传统漏扫多了漏洞利用这一步,并未将第一节所述的“长期的人工渗透过程”进行自动化,对渗透测试整体效率提升不大。
四、总结
本文介绍了自动化渗透领域广为大众所知的DeepExploit框架,并详细分析了其内部原理,通过对其源码的分析,笔者发现DeepExploit并不能实现其宣称的高效渗透,或者说有诸多待改进之处。对于影响渗透效率的非核心问题,如:服务支持问题,各种逻辑问题等等,笔者将其列出,这些问题不难解决,对于核心的算法问题,笔者给出可能的改进方向。而渗透测试最耗时的“人工渗透”部分,DeepExploit并未将其自动化,自动化渗透领域还有很长的路要走。
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。