2022-1-1 06:30:0 Author: research.nccgroup.com(查看原文) 阅读量:33 收藏
(Or, “Can large language models generate exploits?”)
While attacking machine learning systems is a hot topic for which attacks have begun to be demonstrated, I believe that there are a number of entirely novel, yet-unexplored attack-types and security risks that are specific to large language models (LMs), that may be intrinsically dependent upon things like large LMs’ unprecedented scale and the massive corpus of source code and vulnerability databases within their underlying training data. This blogpost explores the theoretical question of whether (and how) large language models like GPT-3 or their successors may be useful for exploit generation, and proposes an offensive security research agenda for large language models, based on a converging mix of existing experimental findings about privacy, learned examples, security, multimodal abstraction, and generativity (of novel output, including code) by large language models including GPT-3.
This post is organized as follows:
- Introduction to large language models
- GPT-3 as a Case Study:
- Known capability: GPT-3 can generate code
- Potential capability: Can GPT-3/Codex generate exploits?
- An Offensive Security Research Agenda for Large Language Models
- Thinking about Artificial General Intelligence
- Conclusions
- Note from the Author
- References & Further Reading
I would caution the reader that unlike the vast majority of what we publish on this blog, this post is purely theoretical and lacks working proofs-of-concept. Like many of the most interesting offensive security research topics related to machine learning and artificial intelligence right now, this one too involves large-scale systems in production that we do not own, which introduces legal, logistical, and ethical barriers against simply hacking on these systems, for which collaborative future research partnerships could be beneficial. Until then, here is an early sketch of some things I’ve been wondering about, why these attacks might be feasible, and speculation about what they might mean for the security of the internet.
1 — Large language models
Natural Language Processing (NLP) is an established subfield of computer science and linguistics which seeks to enable computers to both process and generate information within the natural human languages that people use to communicate. While research in NLP dates back to the mid-20th century, recent work in this field has increasingly over the past decade or so focussed on the use of large neural networks to represent natural languages (most commonly, English). For the purposes of this post, a language model is a type of machine learning model trained upon natural language data, which models the statistical properties of sequences of words in a given language, allowing for the probabilistic prediction of the “next” word in a sequence. (Readers interested in better working definitions of language modeling are directed to Yoshua Bengio’s overview of neural net language models [1]).
Over the last 3-5 years, substantial advancements in (increasingly large) language models have been demonstrated across several industrial research groups from OpenAI, Google, Microsoft, NVIDIA, Facebook, and others, which we’ll explore briefly in the section below. Perhaps the most recognizable of these models to the mainstream is OpenAI’s GPT-2 [2] and more recently GPT-3 [3].
The canonical paper describing GPT-3 is of course “Language Models are Few-Shot Learners” [3] version 1 of which was published in May 2020 by members of OpenAI. This paper describes the team’s approach to training and evaluating the GPT-3 language model, discusses the performance of GPT-3 across a number of NLP (Natural Language Processing) computational benchmarks in the zero/one/few-shot settings, and outlines three categories of “Broader Impacts” which include “Misuse of language models,” “Fairness, bias, and representation,” and “Energy usage.”
While these are clear indicators that the ethics of large language models are a serious consideration for the authors, in the 75-page original GPT-3 paper, the word “security” is mentioned only once – and even in that case, it is only used by analogy to apply threat modelling principles to study non-security threats.
In my view, this is emblematic of what we see across much of the ethical-AI subfield: security is too often merely an analogy or a footnote. The field of ethical AI has often overlooked or under-scoped security, or failed to focus on it at a sufficient level of granularity for it to be properly addressed in real-world systems. Security is critical to ethical artificial intelligence not because it is a parallel property that we should seek alongside things like fairness, but because it is a prerequisite to it. Specifically, security is a prerequisite to ethical artificial intelligence because you cannot make meaningful guarantees about a system that you do not control.
2 — GPT-3 as a Case Study
2.1 — Model & Architecture
As a large language model, GPT-3 has around 175 billion parameters at an estimated training cost of 355 years and at least 4.6 million dollars in 2020 [4]. This is significantly larger than GPT-2, which had around 1.5 billion parameters. This increased size has yielded increased capability in natural language processing. GPT-3 is able to generate texts of up to 50,000 characters, unsupervised, in a variety of styles [5]. GPT-3 is actually “only” three orders of magnitude smaller than the human brain, which has around 100 trillion synapses [4]. (However, there are many ways to functionally measure the “size” of the brain, and number of synapses is not necessarily the “best” way of representing the computational power of the brain – but a discussion of this is out of scope for this blog post.)
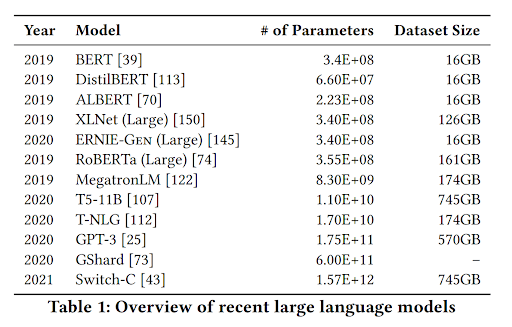
While GPT-3 is perhaps the best-known large language model, there are several models of comparative size currently in existence. This chart, borrowed from Bender, et al (2021) [6], offers a guide to other recent large LMs and their relative dataset sizes and numbers of parameters (below):

Other recent large language models include MegatronLM (NVIDIA) [7], Turing-NLG (Microsoft) [8], GShard (Google) [9], and Switch-C (Google Brain) [10], and RoBERTa (Facebook) [11], among others. Here we see in recent years an an order-of-magnitude scaling of the size of the largest language models – a noteworthy observation given the relationship between size and performance of these models.
Notably, GPT-3 – perhaps the most widely-discussed example of contemporary large language models – is in this blog post used as a lens through which to ask generic questions about the as-of-yet unexplored capabilities of large language models in general, including those listed above. Thus, the concepts in this post represent universal questions regarding large language models, including not only GPT-3, but also any of its’ derivatives or successors (including when trained on or optimized for security-relevant or code-generation-relevant codebases), as well as large language models of all other flavours. Here, the specifics of GPT-3 (and its’ training data and capabilities) are discussed simply so as to provide concreteness of examples.
The authors state in the introduction of the original GPT-3 paper that improvements in text synthesis and other natural language processing tasks observed in transformer-models – from those with 100 million parameters in a paper published in 2018, to those with 17 billion parameters in a paper published in 2020 – has improved in a reliable way with increasing scale of these models, and furthermore that “since in-context learning involves absorbing many skills and tasks within the parameters of the model, it is plausible that in-context learning abilities might show similarly strong gains with scale” [3]. Indeed, they proceed to state that testing this hypothesis was the express purpose of the development of GPT-3. This is powerful.
GPT-3 was benchmarked across several NLP datasets as well as some novel additional tasks, under each of three conditions [3]:
- “zero-shot learning” where no demonstration is given to the model – all it receives is an instruction in natural language
- “one-shot learning” where only one demonstration is allowed to be given to the model
- “few-shot learning” where a small number of demonstrations are given to the model (stated in the GPT-3 paper as, “in-context learning where we allow as many demonstrations as will fit in the model’s context window (typically 10 to 100)”)
Strikingly, they demonstrate that “Model performance improves with the addition of a natural language task description, and with the number of examples in the model’s context, K. Few-shot learning also improves dramatically with model size. Though the results in this case are particularly striking, the general trends with both model size and number of examples in-context hold for most tasks we study.” (p. 5) [3].
One of the things I found most interesting was that they find that in the few-shot setting, GPT-3 sometimes meets or surpasses the performance of models that have been fine-tuned on topic-specific models and data, which is intriguing because it suggests that sufficiently large generic LMs may soon be able to outperform even the best domain-specific models across a range of domains, and thus that it may be reasonable to think of large language models as “greater than the sum of their parts,” so to speak.
2.2 — Training Datasets
Arguably one of the most interesting things about GPT-3 from the perspective of a security researcher is not merely its’ size, but rather its’ size in conjunction with the specific datasets upon which it was trained. In particular, OpenAI’s published GPT-3 model card [12] notes that GPT-3 was trained on and evaluated against English-language wikipedia, two internet-based book corpora, and most notably, an expanded version of the Webtext dataset, and a version of the CommonCrawl dataset (“filtered based on similarity to high-quality reference corpora”).
The Webtext dataset [3], [12] is a 40 GB internal OpenAI dataset of 45 million links, obtained by scraping Reddit for all links (except Wikipedia, because it exists in other training data sources) with at least 3 karma [13]. The CommonCrawl dataset “contains petabytes of data collected over 12 years of web crawling. The corpus contains raw web page data, metadata extracts and text extracts” [14].
Consequently, the corpora for large LMs raise interesting questions: What types of security-relevant information is either explicitly or implicitly coded within those datasets, what has GPT-3 learned from that data, and what could it mean about the potential autonomous capabilities of large language models (LMs) like GPT-3 trained on these types of corpora?
Recent research has shown that for GPT-3’s predecessor, GPT-2, hundreds of verbatim text strings of training data can be extracted from the production GPT-2 model, which includes sensitive data elements including “(public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs” [15]. This, combined with the discussion of how to extract PII from LMs and find that it gets easier to extract PII as the language models get larger(!) [15], implies that the PII-extraction attacks possible on GPT-2 may very well be possible on its successor, GPT-3. This is certainly itself worthy of further study.
However, I am actually far more interested in a risk we didn’t observe with GPT-2 – namely, that GPT-3 can generate novel code samples, much like it has been shown to be able to generate complex, novel images and prose [3], discussed in the section below.
The semantic relationships and rich conjunctions of features that GPT-3 has been able to map through natural language for stimuli represented as images or text may even have the same underlying semantic relationships for code generation, which I’ll discuss below.
3 — Known capability: GPT-3 can generate code
One of the most compelling findings of researchers exploring GPT-3 is that it is capable of generating code, often from natural (human) language descriptors. This, combined with findings that GPT-3 is capable of generating novel outputs based on highly unlikely combinations of semantic inputs [16] (such as a “armchair imitating an avocado” below).

OpenAI has shown that this is by no means limited to the domain of image generation. Indeed, examples of novel synthesis or generative capability include:
- Conceptual summarization of text, whereby GPT-3 has been shown to be able to summarize a complex text into a conceptually similar but simpler text, both for 2nd grade readers, as well as to create a “TL;DR” for adult readers [25]
- Conceptual expansion of text, whereby GPT-3 has been shown to be able to generate a detailed essay outline from a simple, high-level input topic, as well as generate novel analogies in human language [25]
- Language translation (for – and between – both human and machine languages), whereby GPT-3 has been shown to be able to translate between some natural (human) languages, as well as from machine language to human language (in this case, generating a Python docstring from underlying code), and from human language to machine language (in this case, translating an English prompt into a simple SQL query) [25]
This demonstrates that GPT-3 is generically capable of generating novel outputs based upon highly improbable combinations of unrelated features, as well as demonstrating an ability to generate conceptually meaningful extensions to input data in a variety of forms, including machine-readable code.
So then I’d ask: Can a large language model such as GPT-3 generate novel code, perhaps even for conjunctions of properties for which it has not specifically seen a prior training example?
It turns out that the answer is yes, and that people quickly demonstrated a range of these capabilities without any particular training or tuning of the language model to specifically enable code generation.
Early GPT-3 powered code generation tasks have included the following examples:
- One researcher was able to create a web layout generator in which one may simply type in a description of the layout they want in plain English, and GPT-3 will generate the associated JSX (JavaScript XML) [17]
- When you describe a machine learning model in plain English including only the dataset and required output, GPT-3 was able to generate a Keras machine learning/deep learning model [18]
- Researchers have created an English to regex generator [19] as well as a text to javascript [20] tool
- When asking natural-language questions in English about a SQL database, GPT-3 was able to generate the associated SQL queries [21]
- Other researchers have shown that GPT-3 is able to translate natural language into shell commands [22], and vice versa [23]
We also know that GPT-3 in general “shows one-shot and few-shot proficiency at tasks designed to test rapid adaption or on the fly reasoning,” however they, “also find some tasks on which few-shot performance struggles, even at the scale of GPT-3” (p.5) [3]. Thus, a core question about GPT-3’s abilities reduces to whether the task types involved in security tasks like exploit generation are the type for which GPT-3 shows one-shot or few-shot proficiency – particularly in cases where we do not believe there to be many training samples. If the answer is yes, then we are likely to see the weaponization of large language models for offensive security purposes.
A perhaps natural question that may follow from seeing large language models competently generate code for a collection of arbitrary development tasks is then, “Can large language models like GPT-3 generate exploit code for existing vulnerabilities for which exploits do or do not already exist, or even for some exploitable zero-day vulnerabilities?”
This question needs to be asked both for extant large language models like GPT-3 on their existing datasets to understand the potential for weaponization of these general-purpose tools. However, this research critically must also extend to help study how these tools – through the introduction of additional training data or reinforcements – could perform if optimized, even somewhat, for vulnerability detection or exploit generation, such as through more targeted training on these tasks or associated codebases.
To be clear, the answer is: we don’t know.
But the answer is also: it is important for us to find out.
3.1 — Discussion: “Evaluating Large Language Models Trained on Code” (July 2021)
While I was partway through writing this blogpost, OpenAI & collaborators released a research paper titled, “Evaluating Large Language Models Trained on Code” (July 2021) [24] and published a related blog post in August 2021 [25] which made this topic more timely than ever. These publications discussed Codex, which is a GPT-3 derived language model trained on open source code on GitHub, which generates Python code. Interestingly, the authors note that it is a version of Codex that powers GitHub Copilot [26]. The authors note that this project was initially motivated by the discovery during the early work on GPT-3 that GPT-3 was able to generate simple Python programs from supplied docstrings [3]. Indeed, they note that, “this capability was exciting because GPT-3 was not explicitly trained for code generation” [24]. While Codex is based upon GPT and the researchers initially sought to build the Codex code lexer using the GPT-3 text tokenizer, they found that the distribution of words on GitHub compared to natural language meant that they needed to modify things to better represent software language (code) instead of natural language (English).
To evaluate the performance of Codex, the authors created and released a benchmarking suite of 164 programming problems with associated unit tests which assess “language comprehension, reasoning, algorithms, and simple mathematics”, which has been released on GitHub, called the HumanEval dataset [27]. The training data for Codex included 54 million public software repositories on GitHub of Python files under 1MB, having filtered out only training data with above-threshold line lengths, low percentages of alphanumeric characters, and that which appeared to be auto-generated [24]. According to the details presented in the paper, there appears not to have been any filtering for correctness or security of the training sample code.
Their findings were ultimately as follows:
- Language models are made better at generating code when fine-tuned to do so. Regular GPT models which have not specifically been trained on code perform poorly, but descendants of GPT models that are explicitly trained and fine-tuned on code perform well.
- Increasingly granular fine-tuning on code helps models perform even better. While Codex (“fine-tuned on code“) solves 28.8% of the HumanEval problems, Codex-S (which is “further fine-tuned on correctly implemented standalone functions“) solves 37.7% of the HumanEval problems.
- Unsurprisingly, the number of model parameters matters. Performance (in this case, pass rate on a benchmarking task) scales with model size, as illustrated in the diagram from [24] below.
- Reasonable increases in the number of solutions sampled can dramatically improve code-generation performance. While Codex-S was able to solve 37.7% of the HumanEval problems when permitted to generate just a single solution, when it was permitted to generate 100 samples/solutions and be considered to have solved a given HumanEval problem when at least one of the 100 generated code samples satisfied the unit tests, it was able to solve 77.5% of the HumanEval problems.
But what does all of this mean for security?

In section 7.5, Security Implications of the Codex paper (p.12) [24], the study’s authors describe the following 4 security risks of code-generation large language models:
- Unintentionally-insecure code: The unintentional generation of insecure code by the model that may then be readily trusted and used by a developer [24]
- Enabling malware development: Being used to “aid cybercrime,” but for which the authors state, that they “believe that at their current level of capability, Codex models do not materially lower the barrier to entry for malware development” [24]
- Enabling polymorphism for signature-detection evasion: Malware developers leveraging the non-deterministic nature of code-generation large language models like Codex to make it easier to create polymorphic malware which may more readily evade antivirus systems’ signature-based detection of malicious binaries [24]
- Leakage of sensitive data: Sensitive data elements in the training data may be learned or predicted by the model [24]
These are valuable future research directions.
However, I would also add the following additional potential security risks to this list:
- Poor security-related design “choices” for cryptography other security-critical components of systems architecture: For example, in the original Codex paper [24] the authors noted that when they “asked Codex to suggest code that would call cryptographic libraries to generate cryptographic contexts, ….Codex models of varying sizes frequently use clearly insecure configurations.” Worse yet, these flaws were not subtle issues with cryptographic implementations – but rather, basic things like insecure key sizes (for example, RSA keys of fewer than 2048 bits) or symmetric ciphers using insecure cipher modes (for example, AES in ECB mode) [24]. It is not unreasonable, given these basic flaws, to assume that issues may remain in terms of things like key re-use, insufficiently random sources of randomness, and subtle implementation or mathematical flaws, especially given that these seem to appear to have been created generatively alongside other code, based on learning from a large corpus of data.
- Entrenchment of language-related vulnerabilities: While the authors did cite “unintentionally-insecure code” as a security risk, the risk is potentially greater than merely generating instances of bad code. Rather, I wonder to what extent vulnerabilities persist in code over time. Even when bad sources (such as flawed codebases or less-secure past programming language standards) are updated, do the models immediately reflect more secure programming patterns? Likely not. Consequently, I wonder whether the eradication of security vulnerabilities could be slowed down by code generation language models, because the underlying code generation models are likely to lag behind security improvements to programming language standards, propagating insecure old patterns, further into the future.
- Easy, efficient generation of insecure code samples: In qualitative experiments run on GPT-3’s ability to generate short stories, it was found that use of descriptive adjectives in prompts to the model meaningfully influenced the output. As a striking example, the input “a prize-winning short story” led GPT-3 to generate short stories that were scored as better by readers than when GPT-3 was simply told to write “a short story” [32]. Consequently, I wonder if – given conceptual representation and the volume of code upon which the model was trained – asking for an “insecure” version of a function, library, or other code sample could help create subtly flawed malicious code. Indeed, to be able to efficiently generate many of these samples, it is conceivable that an attackers could test them against static analysis tools to attempt to find malicious code samples which are more likely to go undetected.
- Exploit generation: The potential for these code-generation models to generate offensive code to exploit common software flaws. In particular, I am interested in the question of whether code-generation large language models are capable of generating exploits – and under what conditions this can be successfully achieved for which categories of vulnerabilities.
Most notably absent from the extant literature is of one of the most potentially weaponizable aspects of large language models’ code generation capabilities: software vulnerability exploit generation.
4 — Potential capability: Can GPT-3/Codex generate exploits?
Suggesting that an existing, generic large language model may be able to discover or even exploit vulnerabilities in code is pretty bold, and will require meaningful proofs of concept to verify. It may be tempting to dismiss this speculation as more of the overhyped views of artificial intelligence that so many in our industry have internalized, where the magic of statistics is some kind of security panacea. However, there are properties specific to large language models that I believe suggest otherwise.
A few core properties of GPT-3 that suggest that GPT-3 (or its’ descendants, which could include any large language model with similar properties, especially those used for code generation) may potentially be able to generate exploits of software vulnerabilities include:
- There have been numerous examples of GPT-3’s ability to generate working code in a variety of programming languages. This demonstrates that GPT-3’s training data included a sufficiently large number of code samples to enable at minimum the demonstrated capabilities of some minimum ability to generate code across a range of programming languages. This point predates – but is strongly amplified by – OpenAI’s publication of Codex this summer.
- Part of GPT-3’s training data included English-language wikipedia, which describes known vulnerability classes in depth, almost always with example code demonstrating the vulnerability, and often with detailed sections on exploitation that also include sample code, and often also with directly linked historical references to historical malware and otherwise insecure code which is likely present elsewhere in the corpus of training data.
Furthermore, an OpenAI blog post discussing Codex noted that this GPT-3 descendant was trained on, ” billions of lines of source code from publicly available sources, including code in public GitHub repositories,” and noting that it “is most capable in Python, but it is also proficient in over a dozen languages including JavaScript, Go, Perl, PHP, Ruby, Swift and TypeScript, and even Shell.” This, in conjunction with the fact that “it has a memory of 14KB for Python code, compared to GPT-3 which has only 4KB” lead the authors to conclude that “it can take into account over 3x as much contextual information while performing any task.” [28]
- That GPT-3 can generate code from natural language specifications indicates that there may be semantic networks at multiple levels of abstraction, potentially enabling GPT-3 to relate or translate English-language computer science and security concepts to example code. Further evidence for GPT-3’s abstraction capability comes from the March 2021 paper, “Multimodal Neurons in Artificial Neural Networks,” [30] which described the observation by OpenAI researchers that artificial neural networks exhibited multimodal neurons – that is, specific neurons that responded to a specific CONCEPT (such as the concept of “Jennifer Aniston” or “Spiderman” or of the colour yellow or the autumn season…) regardless of the modality in which it was presented (photo, video, image of the person’s name, etc). Multimodal neurons were first reported to have been observed experimentally in humans in a canonical 2005 Nature paper [30], and were revolutionary because they showed concrete, physiological evidence of the granular substrates underlying abstract, complex, conceptual thinking. Similarly, to know that multimodal neurons are being observed in machine learning models similar to large language models indicates that these models, too, have some level of abstract, conceptual representation, suggesting that logical reasoning about abstract computer security concepts is within the realm of reasonable.
- Experiments on GPT-3 shared by researchers, demonstrate GPT-3 having a willingness to construct highly unlikely (and thus it may be inferred: truly novel) artifacts, such as a “giraffe-shaped button,” indicating some ability to be truly generative and creative on the basis of a conjunction of input features to create a novel output, as opposed to the model simply responding verbatim with existing related results from its’ training data.
Ultimately, this is a topic worthy of future study by security researchers, and it is for this reason that I present an initial offensive security research agenda for large language models further into this post.

5 — An Offensive Security Research Agenda for Large Language Models
In this section, I propose a number of initial open research questions to help us better understand the security properties and potential for weaponization of large language models, examining large language models’ training data, knowledge extraction/data exfiltration, vulnerability creation & detection, code generation, and generic ability to abstract and reason.
Theme 1: Weaponizability of Training Data
1.1 – Learning from Dangerous Codebases
Does the language model in question trained upon data which includes vulnerabilities, their patches, malicious code, or other sources of information about identifying or creating dangerous code? For example, was the language model trained upon:
- Major malware repositories (source code and/or binaries)?
- Open source offensive security tools or proof-of-concept vulnerability exploits published on source code repositories such as GitHub?
- Technical or security advisories published by software vendors and security researchers?
- Databases describing vulnerabilities, including (for example) the National Vulnerability Database, whereby data samples of labelled vulnerabilities exist?
- Vulnerability-finding tools’ source code and/or output/findings?
- Multiple copies of source code samples or repositories over time, such that diffs may be computed and security patches associated to specific CVEs be inferred?
Theme 2: Knowledge Extraction & Data Exfiltration
2.1 – Extracting Training Data
It has been demonstrated in some recent large language models that sensitive training data elements, including PII, can be extracted by end users of the model [15]. This presents the question: How at-risk are large LMs’ training data elements, and what are appropriate mitigations of this risk? For example, one may wish to explore:
- Does the amount of training data that can be extracted from an LM vary between different large language models? If so, what differences between these various models’ architectures, training datasets, approaches to training, and other factors may explain any differences in data leakage?
Theme 3: Vulnerable Code Generation
3.1 – Unintentional Generation of Vulnerable Code
Does language model-generated source code generated from natural language descriptors contain vulnerabilities? And if so:
- Can the origin of those incorrect coding patterns be discerned from the training datasets?
- Does making queries for a “secure” version of a function or by otherwise adding security-related properties to the query submitted to the LM alter the likelihood of generating insecure code?
- Does LM-driven code generation contain a greater proportion of vulnerabilities than human generated code?
- Are there alternative approaches to the development of large language models for code generation that would reduce the likelihood of vulnerable code being generated? Alternately, are interventions more effective at a different point in the SDLC/code development pipeline? For example, how could static analysis tools be integrated into workflows that use AI-driven code generation tools, to reduce the number of vulnerabilities in a resulting codebase?
3.2 – Intentional Generation of Vulnerable Code
If a language model is asked in natural (i.e.: human) language to write a function with a specific vulnerability class present in the code, can it generate an instance of this insecure code? And if so, can it generically do this:
- In many or all programming languages for which the vulnerability class exists?
- As a modification to an arbitrary, existing target codebase?
- Can extant large language models do this when asked in a natural language, such as English, to generate a specifically “insecure” version of a function?
3.3 – Robustness of Code Generation Patterns Over Time
Does language model-generated source code reflect particular temporal markers that indicate its generalizability for effective code generation will degrade over time?
- Is there a presence of unsafe coding practices in generated code that have since become deprecated or replaced by recent revisions to programming language standards?
- Is there an increased likelihood over time for a model to generate unsafe code because the model was trained on datasets for which more examples of a particular vulnerability were present in the wild before it was patched? If so, are there effective ways of training the model to account for more recent knowledge of the vulnerability and its’ security fix?
3.4 – Secure Code from Insecure Data
Can language models trained on inevitably vulnerability-laden datasets reliably generate secure code as output?
- Is it necessary for models to learn from patches applied to security vulnerabilities in their training codebases, or are there other ways to improve the security of generated code?
- What model-training frequencies or paradigms will allow language models used for code generation to update their models to reflect security patches applied to training data points?
- What can be done to mitigate the effects of vulnerable training samples on the security of model-generated code?
Theme 4: Vulnerability Detection
4.1 – Ability to Detect Software Vulnerabilities
The concern about whether language models’ code generation capabilities lead to increased vulnerabilities in codebases are serious and real. It is reasonable to also consider the flip side of the question: If large language models are shown to generate vulnerabilities, are they also an effective tool for detecting software vulnerabilities? Specifically:
- How do simple vulnerability detection queries using large LMs compare to traditional vulnerability-finding tooling such as fuzzing, SAST/DAST, and other flavours of program analysis?
- Can a conceptual, multimodal representation of vulnerability classes lead to better detection, or even potentially better exploitability estimates?
- Are large language models’ demonstrated abstraction capabilities useful in finding vulnerabilities in complex codebases for which simple vulnerability scanners/static analysis tools often fail to suffice?
However, I would note that large language models should not be presumed a security panacea, any more than should any other buzzword in our industry (quantum! blockchain! A.I.!). As is the case with everything that offers some kind of potential computational advantage, what matters is whether the computational primitive (in this case, large language models) is of the right fit for a given problem definition (in this case, vulnerability detection) to offer meaningful improvement in task performance over known alternatives. This is to say: While you could probably use language models or machine learning in general for most problems – including vulnerability detection – you only should when it outperforms existing approaches and is worth the computational cost.
Theme 5: Exploit Generation
5.1 – Benchmarking Offensive Code Generation
What would a benchmark suite of code generation tasks look like? We would seek to test the generic ability of a specific large language model to:
- Generate arbitrary, syntactically correct source code in a specific programming language or in general?
- Generate exploit code for arbitrary instances of known vulnerability classes in a specific programming language?
- Generate exploit code for arbitrary instances of known vulnerability classes in an arbitrary programming language?
- Generate exploit code which works against specific existing known vulnerabilities (CVEs) on unpatched systems?
I propose the creation of a benchmarking suite – analogous to those used for benchmarking language models against natural language processing (NLP) tasks – to understand the performance of various language models in terms of code generation, the safety/security of generated code, as well as the offensive capability to generate code which exploits vulnerabilities in the wild. A valuable direction for future research is to specify and ultimately build such a benchmark suite.
5.2 – Language-Specific Code Generation Performance
Does code generation performance of a language model vary across programming languages? If so, are there performance differences (unattributable to relative sample sizes of training data) between:
- Higher-level languages and lower-level languages?
- Languages with English-like syntax compared to those without?
- Interpreted, scripted, or precompiled languages? (etc)
- Programming languages with grammars at different levels of the Chomsky hierarchy of formal grammars? Alternately: programming languages with differences in expressive power?
5.3 – Improving Exploit Code Generation Performance
To understand our attackers (or potential attackers), we must understand the art of the possible. For this reason, we would also seek to know: Does combining known techniques in automatic exploit generation (AEG) with the use of large language models increase the efficacy of exploit generation tools against n-day or even 0-day vulnerabilities?
And if so, what are the potential defenses?
Theme 6: Ethics & Safety Considerations
There are undoubtedly ample other interdisciplinary questions around responsibly conducting this research & development, and these are offered merely as a starting-point.
6.1 – Societal Impact
To better understand the societal impact of security risks introduced by code-generation large language models, we may consider things like:
- In which domains are code-generation LMs likely to be adopted, and what security controls are typical (or even required) in those verticals?
- In the event that code-generation LMs create less secure code, what complementary tooling or security testing may best find & remediate those vulnerabilities?
- In the event that code-generation LMs create more secure code, which fields or industry verticals are most likely to face structural or other barriers to deploying this technology?
- If security reasons justify the frequent retraining of code-generation LMs to improve security of generated code, what is the environmental impact of that retraining, and what could be done to lessen those computational costs?
6.2 – Safety Considerations
To study the prospect of machine-generated code being unintentionally insecure, we might ask things like:
- How do the security properties of machine-generated code differ from human-generated code? For example, are there more or less vulnerabilities (in general, of a specific class, or in specific languages or contexts) when the code is generated using a machine learning model given a natural language prompt?
- Given what is known about model-driven generation of insecure code, should these tools be used to generate code used in safety-critical domains? If so, are specific safeguards or assurances (such as formal verification, etc) required by existing standards or regulations, and would these need to change in the case for machine-generated code compared to human-generated code?
- Is it practical to create code-generation large language models trained only upon code samples known to be secure? Under test, is it actually true that code generated from a highly-secure training set would very rarely or never itself be insecure?
6.3 – Policy & Law Considerations
Further work by researchers and practitioners in policy and law may include questions such as:
- Who is legally, ethically, or practically (in terms of vulnerability management) responsible for insecure code generated by a code-generation large language model?
- Do there exist domains for which the use of large LMs should be restricted, or for which existing law or policy may call the use of large LMs into question?
- Given the dual-use nature of artificial intelligence in general and large language models in particular, what effects will export controls and other international policies have upon global adoption of these technologies (or lack thereof)?
- Ethically speaking, are there datasets upon which large LMs should not – without informed, well-justified intent, be trained? Practically speaking, could better curation of code repository training datasets be an effective manner to improve the security of language model-generated code?
6.4 – Open Source Security Considerations
In past presentations [29], [31] I’ve speculated on the impact that research advancements to vulnerability finding at scale could have on the state of open source software security. While beyond the scope of this blog post, I will simply note that scalable vulnerability finding is dual-use in that it can benefit both attackers and/or defenders (depending on who develops or uses it best), and that advancements in the ability to intentionally generate subtly insecure code (to make malicious commits), or in the ability to more reliably generate working exploits (against known codebases) is concerning for the state of all software security, not least that of open source software.
6 — Thinking about Artificial General Intelligence
Looking toward the future, large language models such as GPT-3 (and its peers and successors) seem like meaningful milestones in the pursuit of Artificial General Intelligence (AGI).
While there are still capability gaps between our most powerful language models and most researchers’ definitions of AGI, many of the security risks yet unstudied related to artificial general intelligence can be anticipated by thinking through the offensive security implications of today’s large language models.
Questions we may wish to ask include:
- What are the security problems for which conventional security tools – including machine learning-augmented security tools – currently perform poorly compared to human experts? What are the properties of those problems that make them inaccessible to current tooling, and what types of computational advancements would reduce the performance barriers between best-in-class tooling compared to human experts?
- Are there new ways of representing or understanding complex codebases that would improve machine efficacy at finding, remediating, and/or exploiting vulnerabilities within them, or that could augment the abilities of human experts?
- What types of abstraction between human language and machine languages are most useful to help find, remediate, and/or exploit vulnerabilities in software? How could one supplement the training of large language models to more nimbly or accurately translate between those abstractions?
- What does the thought process look like for human exploit developers, beginning at (or before) the moment at which they identify a vulnerability, through to successful exploitation of the vulnerability? Can cognitive psychological studies (analogous to those conducted on human mathematical cognition) improve our understanding of what psychological “insight” to complex problems of exploit development look like, to inspire better computational models for exploit development?
- In theory, where would human expert security researchers’ performance most improve if they had far greater pattern-matching ability, or dramatically greater volume of experience with examples of software flaws? What are the greatest limitations to present-day large language models that prevent them from exceeding human experts’ capabilities?
7 — Conclusions
The field of Ethical AI has grown dramatically in recent years. Despite considerable and admirable efforts related to AI fairness, transparency, accountability, and other AI ethics topics, this field has often overlooked or under-scoped security, or failed to focus on it at a sufficient level of granularity for it to be properly addressed in real-world systems. Security is critical to ethical artificial intelligence not because it is a parallel property that we should seek alongside things like fairness, but because it is a prerequisite to it. Specifically, security is a prerequisite to ethical artificial intelligence because you cannot make meaningful guarantees about a system that you do not control.
Large language models (LMs) in particular evoke important security considerations, the beginning of which I’ve begun to unravel in this article. Due to specific properties of LMs, we have good reasons to seek to understand their security implications through (ethical, transparent, and consensual) offensive security research. Future work in this space will ideally address the questions presented in the above section, An Offensive Security Research Agenda for Large Language Models, and build upon them in directions I’ve undoubtedly missed in this initial blog post.
In particular, we should seek to understand the potential capacity of GPT-3 and other language models of similar scale and performance in terms of their ability to generate code, detect insecure code, generate arbitrary code, and even their potential ability to generate working exploit code. While no demonstration of this capability has yet been shown in either experimental or production contexts, there are strong reasons to believe it may be possible, and therefore it is deeply worthy of further study.
8 — Note from the Author
As this work is both early and speculative, I particularly invite constructive corrections or collaborative conversation related to this post to my email address – my first name dot lastname at company domain.
9 — References & Further Reading
[1] Bengio, Y. (2008). Neural net language models. http://www.scholarpedia.org/article/Neural_net_language_models
[2] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[3] Brown, T. B., Mann, B., Ryder, N., et al. (2020). Language Models are Few-Shot Learners. https://arxiv.org/pdf/2005.14165.pdf
[4] https://lambdalabs.com/blog/demystifying-gpt-3/
[5] https://www.fullstackpython.com/gpt-3.html
[6] Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? https://dl.acm.org/doi/10.1145/3442188.3445922
[7] Shoeybi, M., Patwary, M., Puri, R., et al. (2019). Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. https://arxiv.org/abs/1909.08053
[8] Rosset, C. (2020). Turing-NLG: A 17-billion-parameter language model by Microsoft. https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
[9] Lepikhin, D., Lee, H., Xu, Y., et al. (2020). GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. https://arxiv.org/abs/2006.16668
[10] Fedus, W., Zoph, B., Shazeer, N. (2021). Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity https://arxiv.org/abs/2101.03961
[11] Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. https://arxiv.org/abs/1907.11692
[12] OpenAI GPT-3 Model Card. https://github.com/openai/gpt-3/blob/master/model-card.md
[13] Paperswithcode: About WebText Dataset. https://paperswithcode.com/dataset/webtext
[14] CommonCrawl dataset. https://commoncrawl.org/the-data/
[15] Carlini, N., Tramer, F., Wallace, E., et al. (2020). Extracting Training Data from Large Language Models. https://arxiv.org/abs/2012.07805
[16] OpenAI (2021). DALL-E: Creating Images from Text. https://openai.com/blog/dall-e/
[17] https://twitter.com/sharifshameem/status/1282676454690451457
[18] https://twitter.com/mattshumer_/status/1287125015528341506?s=20
[19] https://twitter.com/parthi_logan/status/1286818567631982593?s=20
[20] https://twitter.com/Antonio_GomezM/status/1287969287110443008
[21] https://twitter.com/FaraazNishtar/status/1285934622891667457?s=20
[22] https://twitter.com/harlandduman/status/1282132804034150400?s=20
[23] https://twitter.com/harlandduman/status/1282198829136097281?s=20
[24] Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H., Kaplan, J., et al. (2021). Evaluating Large Language Models Trained on Code. https://arxiv.org/pdf/2107.03374.pdf
[25] OpenAI API Examples. https://beta.openai.com/examples
[26] GitHub Copilot. https://copilot.github.com/
[27] OpenAI human-eval Codex benchmarking suite https://github.com/openai/human-eval
[28] OpenAI (2021). Codex. https://openai.com/blog/openai-codex/
[29] Fernick, J., & Robinson, C. (2021). Securing Open Source Software – End-to-End, at Massive Scale, Together. Black Hat USA 2021. https://www.blackhat.com/us-21/briefings/schedule/#securing-open-source-software—end-to-end-at-massive-scale-together–23140
[30] Goh, G., Cammarata, N., Voss, C., Carter, S., Petrov, M., Schubert, L., Radford, A., & Olah, C. (2021). Multimodal Neurons in Artificial Neural Networks. https://distill.pub/2021/multimodal-neurons/
[31] Fernick, J., & Wheeler, D. A. (2021). Keynote: Securing Open Source Software. Linux Foundation Member Summit 2021.
[32] https://arr.am/2020/07/31/gpt-3-using-fiction-to-demonstrate-how-prompts-impact-output-quality/
[33] Avgerinos, T., Cha, S. K., Rebert, A., Schwartz, E. J., Woo, M., I & Brumley, D. (2014). Automated Exploit Generation. Communications of the ACM 57(2), 74-84. https://cacm.acm.org/magazines/2014/2/171687-automatic-exploit-generation/fulltext
如有侵权请联系:admin#unsafe.sh