
2018-3-31 16:51:0 Author: addxorrol.blogspot.com(查看原文) 阅读量:3 收藏
During my long sabbatical in 2015-2016 I had plenty of time to think about random things and come up with strange ideas. Most of these ideas are more funny than practical - their primary use is boring people that are reckless enough to have drinks with me.
This blog post describes one of these ideas. With the recent renewed interest in privacy and overreach of smart phone apps, it seems like a topic that is - at least temporarily - less boring than usual.
ML, software behavior, and the boundary between 'malicious' and 'non-malicious'
I have seen a lot of human brain power (and a vast amount of computational power) thrown at the problem of automatically deciding whether a given piece of software is good or bad.
This is usually done as follows:
- Collect a lot of information about the behavior of software (normally by running the software in some simulated environment)
- Extract features from this information
- Apply some more-or-less sophisticated machine learning model to decide between "good" or "bad"
The underlying idea behind this is that there is "bad" behavior, and "good" behavior, and if we could somehow build a machine learning model that is sufficiently powerful, we could automatically decide whether a given piece of software is good or bad.
In practice, this rarely works without significant false-positive problems, or significant false-negative-problems, or all sorts of complicated corner-cases where the system fails.
In 2015, I had to deal with the fallout of the badly-phrased Wassenaar wording: Export-control legislation which tried to define "bad behavior" for software. During this, it became clear to me that the idea that behavior alone determines good/bad is flawed.
The behavior of a piece of software does not determine whether it is malicious or not. The true defining line between malicious and non-malicious software is whether software does what the user expects it to do.
Users run software because they have an expectation for what this software does. They grant permissions for software because they have an expectation for the software to do something for them ("I want to make phone calls, so clearly the app should use the microphone"). This permission is given conditionally, with context -- the user does not want to give the app permission to switch on the microphone when the user does not intend to make a phone call.
The question of malicious / non-malicious software is a question of alignment between user expectations and software behavior.
This means, in practice, that efforts in applying machine learning to separate malicious from non-malicious software are doomed to fail, because they fail to measure the one dimension through which the boundary between good and bad runs.
Intuitively, this can be illustrated with the two pictures below. They show the same set of red and green points in 3d-space from two different perspectives -- once with their z-axis projected away, and once in a 3-d plot where the z-axis is still visible:
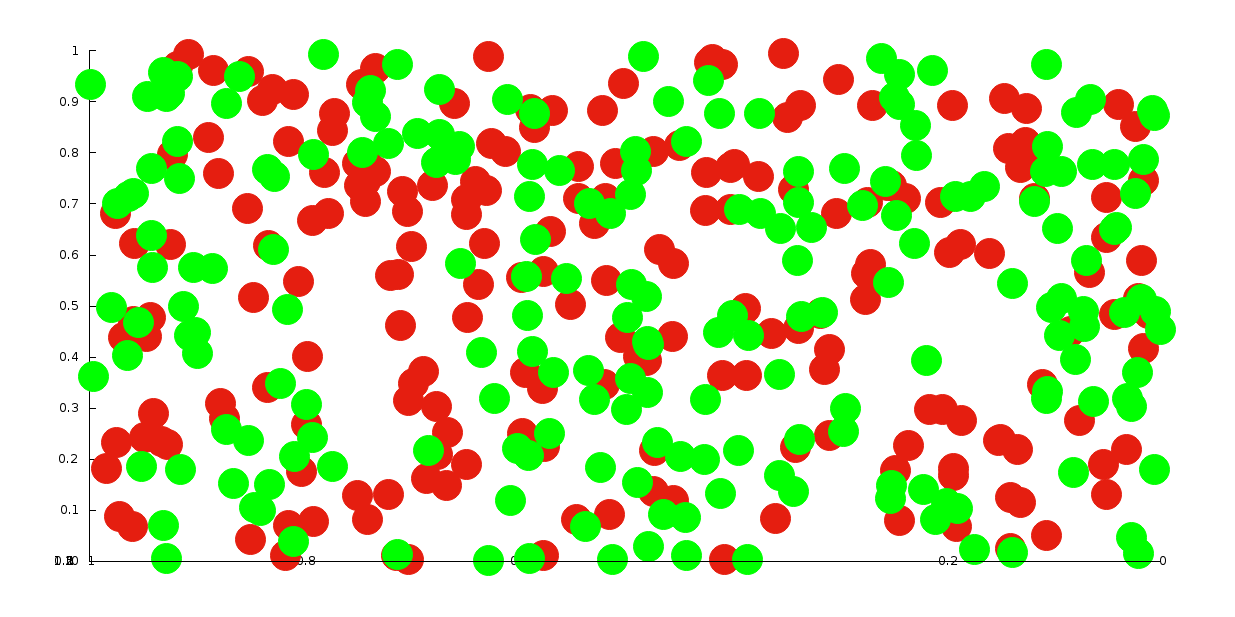 |
| Cloud of points from the side, with the "important" dimension projected away. It is near-impossible to draw a sane boundary between red and green points, and whatever boundary you draw won't generalize well. |
 |
| Same cloud of points, with the "important" dimension going from left to right. It is much clearer how to separate green from red points now. |
The question that arises naturally, then, is:
How can one measure the missing dimension (user intent)?
User intent is a difficult thing to measure. The software industry has the practice of forcing the user to agree to some ridiculously wide-reaching terms-of-services or EULA that few users read, even fewer understand, and which are often near-equivalent to giving the person you hire to clean your flat a power of attorney over all your documents, and allowing them to throw parties in your flat while you are not looking.
It is commonly argued that - because the user clicked "agree" to an extremely broad agreement - the user consented to everything the software can possibly do.
But consent to software actions is context-dependent and conditioned on particular, specific actions. It is fine for my messenger to request access to my camera, microphone and files - I may need to send a picture, I may need to make a phone call, and I may need to send an attachment. It is not OK for my messenger to use my microphone to see if a particular ultrasonic tracker sound is received, it is not OK for my messenger to randomly search through files etc.
Users do not get to tell the software vendor their intent and the context for which they are providing consent.
Now, given that user intent is difficult to measure up-front - how about we simply ask the user whether something that an app / software did was what he expected it to do?
Information and attention is a currency - but one with bad accounting
The modern ad economy runs on attention and private data. The big advertising platforms make their money by selling the combination of user attention and the ability to micro-target advertisements given contextual data about a user. The user "pays" for goods and services by providing attention and private data.
People often fear that big platforms will "sell their data". This is, at least for the smarter / more profitable platforms, an unnecessary fear: These platforms make their money by having data that others do not have, and which allows better micro-targeting. They do not make their money "selling data", they make money "monetizing the data they have".
The way to think about the relationship between the user and the platform is more of a clicheed "musician-agent" relationship: The musician produces something, but does not know how to monetize it. His Agent knows how to monetize it, and strikes a deal with the musician: You give me exclusive use of your product, and I will monetize it for you - and take a cut from the proceeds.
The profits accumulated by the big platforms are the difference between what the combination of attention & private data obtained from users is worth and the cost of obtaining this attention and data.
For payments in "normal" currency, users usually have pretty good accounting: They know what is in their wallet, and (to the extent that they use electronic means for payments) they get pretty detailed transaction statements. It is not difficult for a normal household to reconstruct from their bank statements relatively precisely how much they paid for what goods in a given month.
This transparency creates trust: We do not hesitate much to give our credit card numbers to online service providers, because we know that we can intervene if they charge our credit cards without reason and in excess of what we agreed to.
Private information, on the other hand, is not accounted for. Users have no way to see how much private data they provide, and whether they are actually OK with that.
A bank statement for app/software activity
How could one empower users to account for their private data, while at the same time helping platform providers identify malicious software better?
By providing users with the equivalent of a bank statement for app/software activity. The way I imagine it would be roughly as follows:
A separate component of my mobile phone (or computer) OS keeps detailed track of app activity: What peripherals are accessed at what times, what files are accessed, etc.
Users are given the option of checking the activity on their device through a UI that makes these details understandable and accessible:
- App XYZ accessed your microphone in the last week at the following times, showing you the following screen:
- Timestamp 1, screenshot 1
- Timestamp 2, screenshot 2
- Does this match your expectations of what the app should do? YES / NO
- App ABC accessed the following files during the last week at the following times, showing you the following screen:
- Timestamp 3, screenshot 3
- Filename
- Filename
- filename
- Does this match your expectations of what the app should do? YES / NO
At least on modern mobile platforms, most of the above data is already available - modern permissions systems can keep relatively detailed logs of "when what was accessed". Adding the ability to save screenshots alongside is easy.
Yes, a lot of work has to go into a thoughtful UI, but it seems worth the trouble: Even if most users will randomly click on YES / NO, the few thousand users that actually care will provide platform providers valuable information about whether an app is overreaching or not. At the same time, more paranoid users (like me) would feel less fearful about installing useful apps: If I see the app doing something in excess of what I would like it to do, I could remove it.
Right now, users have extremely limited transparency into what apps are actually doing. While the situation is improving slowly (most platforms allow me to check which app last used my GPS), it is still way too opaque for comfort, and overreach / abuse is likely pervasive.
Changing this does not seem hard, if any of the big platform providers could muster the will.
It seems like a win / win situation, so I can hope. I can also promise that I will buy the first phone to offer this in a credible way :-).
PS: There are many more side-benefits to the above model - for example making it more difficult to hack a trusted app developer to then silently exfiltrate data from users that trust said developer - but I won't bore you with those details now.
如有侵权请联系:admin#unsafe.sh