文章探讨了AI代理如何通过联合类型结构化输出处理软件漏洞中的不确定性问题。传统方法在信息不足时易产生错误数据,而联合类型允许代理承认不确定性并触发人工审查。结合OpenTelemetry可观测性技术,该方法为安全团队提供了透明的审计轨迹和可操作的工作流。 2026-1-8 13:14:2 Author: securityboulevard.com(查看原文) 阅读量:1 收藏
TLDR: We show union-type structured output allows AI agents to handle uncertain outcomes, critical for auditable and accurate vulnerability triage.
Dependency scanners are a critical part of identifying software vulnerabilities. However, they have a problem – vulnerability overload. Which 5 vulnerabilities are most important out of the 487 that the dependency scanner just flagged? Given limited resources, this is a major challenge for modern security teams.
We show in a practical example that AI Agents can analyze vulnerability context automatically and help security experts prioritize the most important. The source-code and an example vulnerable Python package are available in the realm-security/agent-union-type repo on GitHub.
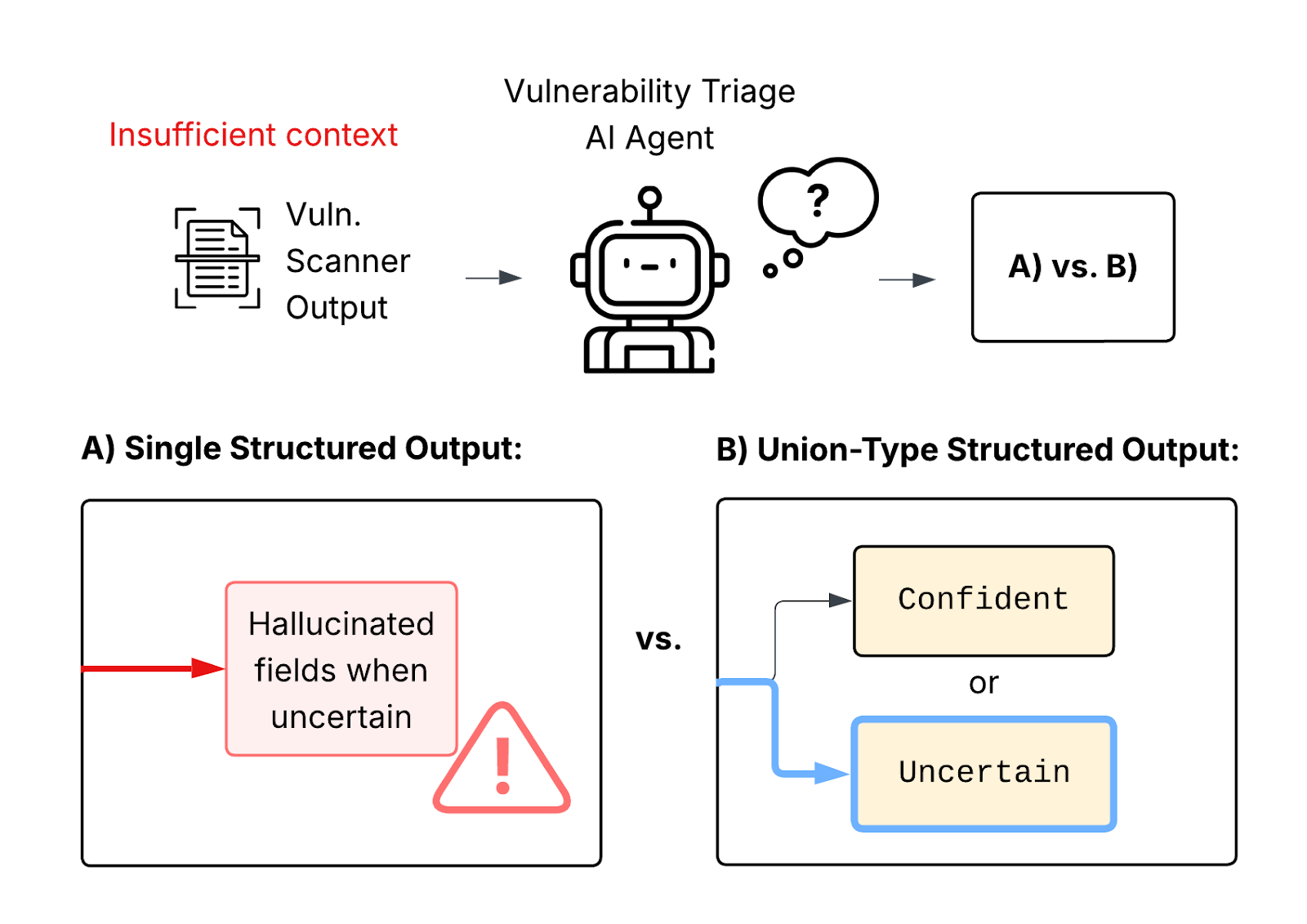
Vulnerability triage illustrates a core problem faced by AI/ML Engineers building agents – the agent needs to handle uncertainty gracefully when it does not have enough information. A vulnerability agent provides value by:
1) Analyzing the vulnerability in depth to extract detailed information
2) Knowing when to raise the findings to the security team for review
When using structured output to capture the detailed information, a single response schema has a major flaw. In the case of insufficient context, the agent is forced to fill out each detailed field – resulting in hallucinated fields when necessary to match the format. Hallucinations at this level can mask real security threats that need to be reviewed, and also cause alert fatigue by passing incorrect assertions on to the security team.

With typed agentic frameworks, like Pydantic AI, a union-type allows the agent to select the appropriate response to handle the situation at hand. We show this simple technique greatly improves the accuracy of agentic systems, and unlocks observability that security teams need to audit and make the best use of AI.
Modern applications are built on hundreds of dependencies that make up the software supply chain. Although an open-source package may have only a few dependencies, the transitive (indirect) dependencies represent a large surface. A 2024 study found average packages in npm and PyPI ecosystems had approximately 3 direct dependencies, with 32 transitive dependencies for npm and 37 for PyPI. Given this can scale to hundreds or thousands of packages across an enterprise codebase, CISOs need to prioritize the most critical vulnerabilities to address first.
CVSS scores provide a valuable representation of the criticality of a vulnerability, but they don’t tell the full story. A CVSS 9.8 vulnerability in an unused code path isn’t as high a priority to address than a CVSS 6.5 vulnerability in user input handling code. Context matters to understand whether a vulnerable function or code path is relevant to the application at hand.
Manual triaging of each vulnerability is often unrealistic for modern security teams given limited resources. Both the scale of transient dependencies, and the frequency of updates drives the challenge of managing mean-time to patch (MTTP). What if an AI agent can analyze the vulnerability context, understand the specific application architecture, and prioritize them based on actual exploitability? Most importantly, can the agent gracefully handle the situation where it doesn’t have enough information?
Gracefully Handling Uncertainty
For security decisions, false confidence is more dangerous than admitting a situation requires further review. The CVE-2017-5638, and resulted in the exposure of personal information for 148 million Americans. The stakes are high to make the right decision.
Traditional ML models produce probability predictions that can help quantify when a model is not confident in the outcome – for example, 67% likelihood of a critical vs. non-critical vulnerability.
The wide variety of text generated by GenAI systems makes understanding agent confidence difficult from natural language directly. Structured output solves this problem by restricting the LLM response to a provided schema.
A critical vulnerability analysis should include:
1) CVE identifies that track the vulnerability and exploit (e.g. CVE-2021-44228)
2) Details about the package name and version
3) CVSS score to contextualize the severity
4) Detailed explanation of how the CVE is exploitable in the specific application code
5) Priority assessment identifying the urgency of patching
The following Pydantic schema expresses this required information and sets specific constraints that allows validation of the schema.
class CriticalVulnerability(BaseModel):
"""A software vulnerability that requires immediate action."""
cve_id: str = Field(description="CVE identifier (e.g. CVE-2021-44228)")
package_name: str = Field(description="Affected package name")
current_version: str = Field(description="Currently installed version")
fixed_version: str = Field(description="Version that patches the vulnerability")
severity_score: float = Field(
ge=7.0, le=10.0, description="CVSS 3.1 base score (only 7.0+ flagged as critical"
)
exploitability_reason: str = Field(
description=(
"Detailed explanation of why this CVE is exploitable in this "
"specific application context. Must reference actual code paths, "
"exposed APIs, or attack vectors."
)
)
remediation_priority: int = Field(
ge=1,le=5,description=(
"Urgency: 1=Patch immediately, 2=This week, 3=This month, 4-5=Next cycle"
)
)
public_exploit_available: bool = Field(
description="Whether exploit code is publicly available"
)
business_impact: str = Field(
description=(
"Potential impact if exploited (e.g. 'Customer data exfiltration', 'RCE "
"on production servers')"
)
)
Each field within the CriticalVulnerability class drives the LLM to generate appropriate information in an actionable format. For example, the remediation_priority field identifies the urgency of patching by forcing the LLM to generate integers from 1 to 5 that represent:
● patch immediately
● this week
● this month
● next cycle
The exploitability_reason field provides a detailed explanation, which can help provide context to a human reviewer or during an audit. This detailed breakdown is critical for making the analysis actionable for both humans and downstream systems alike.
With Pydantic AI, we can use the CriticalVulnerability class to restrict the output of the agent. We use a list type to allow the agent to respond with multiple vulnerabilities given the scan input.
vuln_agent = Agent(
MODEL_ID,
output_type=list[CriticalVulnerability],
system_prompt=VULN_AGENT_SYSTEM_PROMPT,
)
Providing the output type exposes the schema to the LLM. The description argument of the Field classes in the Pydantic schema instructs the LLM, simplifying the system prompt. When we call the agent with the relevant information, Pydantic AI will retry the request automatically if the LLM fails to comply with the structured output requirements. The library also uses smart approaches to increase the likelihood of the LLM successfully formatting the data, such as using tool calling APIs and decomposing lists into multiple tool calls.
Using a single output type is similar to having a single conditional in an if-then statement. The “else” cases are not included, so the program is unable to handle them. In our example, the agent is unable to express the case when it has insufficient information. Forcing the agent to respond without sufficient information has a high probability of hallucinations, or producing an empty result that acts as a false negative.

Union-type outputs allow the agent to select between multiple output schemas, based on the most appropriate schema for the response. We can introduce a UnableToAssess class to allow the agent to express this situation, using the output_type of list[CriticalVulnerability] | UnableToAssess. Although a small and simple change to make, this provides a critical outlet for the agent when dealing with insufficient information.
vuln_agent = Agent(
MODEL_ID,
output_type=list[CriticalVulnerability] | UnableToAssess,
system_prompt=VULN_AGENT_SYSTEM_PROMPT,
)
The schema for the UnableToAssess case provides additional benefits. Including a justification field requires the LLM to produce a detailed text response explaining the reason why the context was insufficient for an assessment. This rich context enables human security experts to quickly understand the situation upon escalation.
class UnableToAssess(BaseModel):
"""Cannot determine exploitability with confidence; requires manual security review."""
justification: str = Field(
description=(
"Detailed explanation of why automated assessment failed. "
"Examples: 'Cannot determine if vulnerable function is called', "
"'Insufficient information about network exposure', "
"'Conflicting informaiton in CVE database and package changelog'"
)
)
flagged_cves: list[str] = Field(
description="CVE IDs that need manual review"
)
recommended_action: str = Field(
description=(
"Specific next steps for the security team. "
"Examples: 'Run dynamic analysis to test exploit', "
"'Review network firewall rules', "
"'Contact package maintainer for clarification'"
)
)
uncertainty_category: str = Field(
description=(
"Type of uncertainty: 'insufficient_context', 'ambiguous_cve_data', "
"'complex_dependency_chain', 'missing_exploit_details'"
)
)
The additional fields provide detailed content that empower human reviewers or downstream systems to take appropriate action. For example, the recommended_action field gives a specific recommendation based on the information available, that can help orient a security expert to the situation.
When the LLM does not have sufficient information, a security expert gets the detailed vulnerability analysis from UnableToAssess to consider for next steps. There are multiple ways to escalate to the human-in-the-loop, including Slack notifications, emails, and database entries that are exposed with a UI. For the purpose of this demonstration, we focus on the backend observability that can be gained using OpenTelemetry (OTEL).
The union-type pattern allows for clear conditional handling of the different cases that the agent encounters. Using OTEL, we can instrument our agentic code to report on the occurrence of each case, allowing a top-level view of the agent’s actions. This helps build a clear audit trail that the security team can use to understand which vulnerabilities were identified as critical, and when the agent needed further review.
Pydantic AI has excellent support for OTEL due to their integration with Logfire. It’s also possible to use this tracing directly with a different OTEL monitoring system, such as Honeycomb, Langfuse, or Jaeger. From this, CISOs and their team can build high-level dashboards that reflect the agent’s work. Critically, this allows CISOs to report on vulnerabilities identified and MTTP improvements, with detailed visibility on the occurrences that require escalation to their team. These metrics also fuel iterating and improving the agent itself.
The output_validator decorator provides a useful hook to instrument the agent for OTEL visibility. Based on the type of structured output, the code delegates to an appropriate handler.
@vuln_agent.output_validator
async def validate_and_instrument(
ctx: RunContext[SecurityContext],
output: list[CriticalVulnerability] | UnableToAssess,
) -> list[CriticalVulnerability] | UnableToAssess:
"""Validate the agent's output and send telemetry for monitoring."""
if isinstance(output, UnableToAssess):
log_unable_to_assess(ctx, output)
# Consider adding:
# - Create a Jira ticket for manual review
# - Send a Slack notification to the security team
# - Update a vulnerability management dashboard
else:
log_critical_vulnerabilities(ctx, output)
return output
In the case of UnableToAssess, an OTEL span is created with the structured output fields, and a warning log is generated. The spans help establish the connection to the overall tracing of the agentic behavior. Beyond logging, a number of other integrations can be added here. For example, a Slack message can be sent to the Security team to ensure they have rapid awareness of the situation.
async def log_unable_to_assess(
ctx: RunContext[SecurityContext],
output: UnableToAssess
) -> None:
"""Log UnableToAssess outcome with OTEL span and log."""
with logfire.span(
"vulnerability_assessment_uncertain",
level="warning",
justification=output.justification,
flagged_cves=output.flagged_cves,
uncertainty_category=output.uncertainty_category,
application_type=ctx.deps.application_type,
internet_facing=ctx.deps.internet_facing,
runtime_environment=ctx.deps.runtime_environment,
) as span:
span.set_attribute("recommended_action", output.recommended_action)
span.set_attribute("uncertainty_event", True)
span.set_attribute("requires_manual_review", True)
span.set_attribute("cve_count", len(output.flagged_cves))
logfire.warn(
"Agent unable to assess vulnerability risk -- manual review required",
cve_count=len(output.flagged_cves),
justification_summary=output.justification[:200],
uncertainty_type=output.uncertainty_category,
)
When the AI agent has sufficient information and outputs list[CriticalVulnerabilities], the spans and logs focus on providing context on the appropriate patching actions that are required.
async def log_critical_vulnerabilities(
ctx: RunContext[SecurityContext],
output: list[CriticalVulnerabilities]
) -> None:
"""Log successful analysis outcome with OTEL span and log."""
critical_count = len(output)
high_priority_count = sum(1 for v in output if v.remediation_priority <= 2)
with logfire.span(
"vulnerability_assessment_complete",
level="info" if critical_count == 0 else "warning",
critical_vuln_count=critical_count,
high_priority_count=high_priority_count,
application_type=ctx.deps.application_type,
) as span:
span.set_attribute("assessment_successful", True)
# Log each critical vulnerability for tracking
for vuln in output:
logfire.info(
f"Critical vulnerability identified: {vuln.cve_id}",
cve_id=vuln.cve_id,
package=vuln.package_name,
cvss_score=vuln.severity_score,
priority=vuln.remediation_priority,
public_exploit=vuln.public_exploit_available,
exploitability=vuln.exploitability_reason[:200],
business_impact=vuln.business_impact,
)
# Alert on immediate priority vulnerabilities
if vuln.remediation_priority == 1:
logfire.error(
f"URGENT: Critical vulnerability requires immediate patching",
cve_id=vuln.cve_id,
package=vuln.package_name,
business_impact=vuln.business_impact,
)
This detailed logging provides a comprehensive audit trail on what actions were taken by the agent, and clearly separates when the agent is uncertain of how to proceed, and when it can provide a confident recommendation. This example illustrates the simplicity of extending the union-type pattern to take deterministic action through downstream systems.
By embracing uncertain outcomes using union-type structured output, we allow AI agents to handle complex situations without resorting to hallucination. We’ve shown that simply adding an UnableToAssess path allows agents to fail safely when assessing software vulnerabilities, transforming a potential oversight into a specific request for expert review.
By coupling this pattern with OTEL observability, security teams gain a transparent audit trail. They can distinguish clearly between confident automated triage and cases requiring human intervention. This approach turns agent uncertainty from a liability into a documented, actionable workflow, ensuring that high-stakes vulnerability management remains both scalable and secure. For CISOs, we see this level of auditability as a core security requirement for deploying AI Agents. For AI/ML Engineers, this telemetry is equally as important, to ensure the systems can be improved continuously based on real system behavior.
如有侵权请联系:admin#unsafe.sh