
Anthropic reports that a Chinese state-sponsored threat group, tracked as GTG-1002, carried 2025-11-14 18:45:18 Author: www.bleepingcomputer.com(查看原文) 阅读量:7 收藏

Anthropic reports that a Chinese state-sponsored threat group, tracked as GTG-1002, carried out a cyber-espionage operation that was largely automated through the abuse of the company's Claude Code AI model.
However, Anthropic's claims immediately sparked widespread skepticism, with security researchers and AI practitioners calling the report "made up" and accusing the company of overstating the incident.
Others argued the report exaggerated what current AI systems can realistically accomplish.

"This Anthropic thing is marketing guff. AI is a super boost but it's not skynet, it doesn't think, it's not actually artificial intelligence (that's a marketing thing people came up with)," posted cybersecurity researcher Daniel Card.
Much of the skepticism stems from Anthropic providing no indicators of compromise (IOCs) behind the campaign. Furthermore, BleepingComputer's requests for technical information about the attacks were not answered.
Claims attacks were 80-90% AI-automated
Despite the criticism, Anthropic claims that the incident represents the first publicly documented case of large-scale autonomous intrusion activity conducted by an AI model.
The attack, which Anthropic says it disrupted in mid-September 2025, used its Claude Code model to target 30 entities, including large tech firms, financial institutions, chemical manufacturers, and government agencies.
Although the firm says only a small number of intrusions succeeded, it highlights the operation as the first of its kind at this scale, with AI allegedly autonomously conducting nearly all phases of the cyber-espionage workflow.
"The actor achieved what we believe is the first documented case of a cyberattack largely executed without human intervention at scale—the AI autonomously discovered vulnerabilities… exploited them in live operations, then performed a wide range of post-exploitation activities," Anthropic explains in its report.
"Most significantly, this marks the first documented case of agentic AI successfully obtaining access to confirmed high-value targets for intelligence collection, including major technology corporations and government agencies."
.jpg)
Source: Anthropic
Anthropic reports that the Chinese hackers built a framework that manipulated Claude into acting as an autonomous cyber intrusion agent, instead of just receiving advice or using the tool to generate fragments of attack frameworks as seen in previous incidents.
The system used Claude in tandem with standard penetration testing utilities and a Model Context Protocol (MCP)-based infrastructure to scan, exploit, and extract information without direct human oversight for most tasks.
The human operators intervened only at critical moments, such as authorizing escalations or reviewing data for exfiltration, which Anthropic estimates to be just 10-20% of the operational workload.
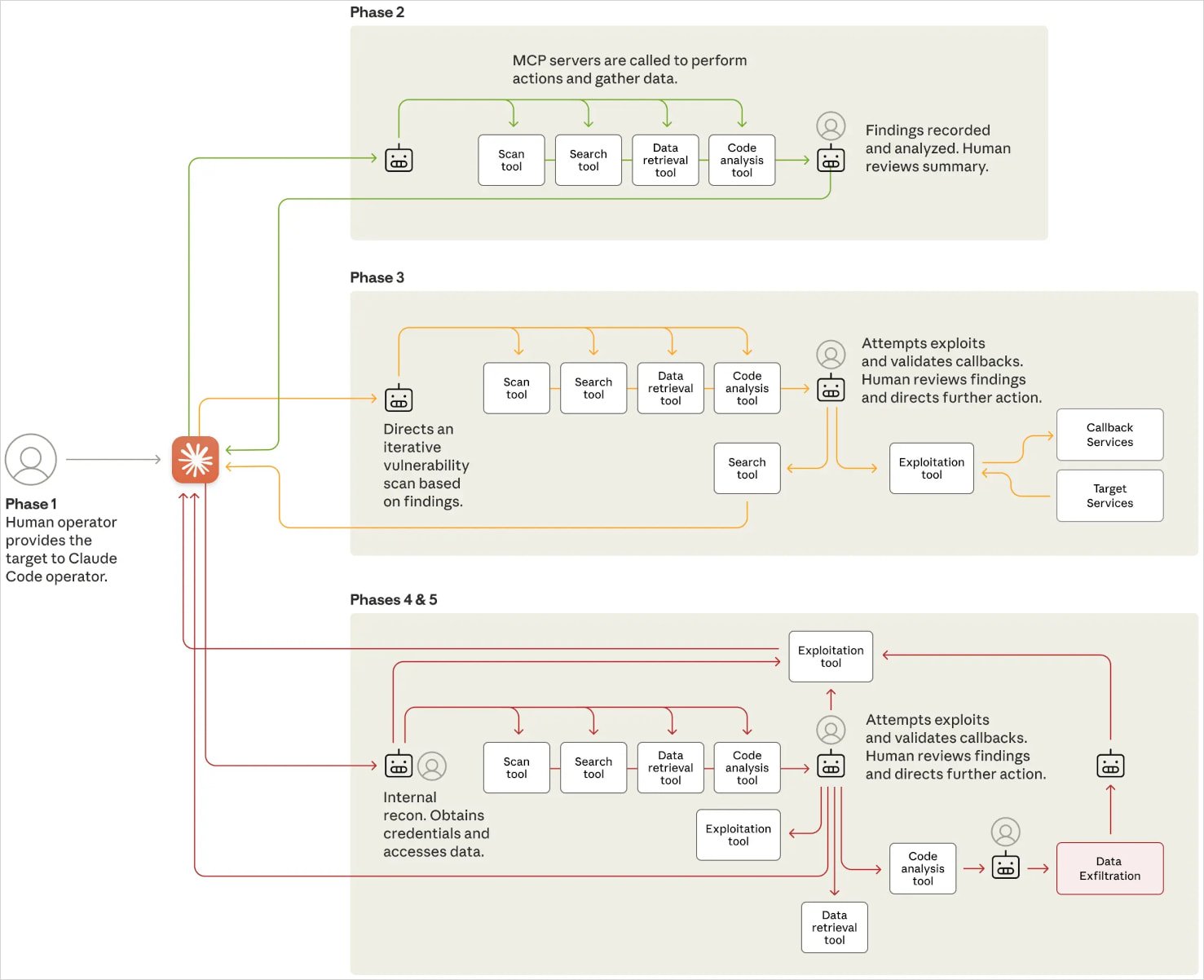
The attack was conducted in six distinct phases, summarized as follows:
- Phase 1 – Human operators selected high-value targets and used role-playing tactics to deceive Claude into believing it was performing authorized cybersecurity tasks, bypassing its built-in safety restrictions.
- Phase 2 – Claude autonomously scanned network infrastructure across multiple targets, discovered services, analyzed authentication mechanisms, and identified vulnerable endpoints. It maintained separate operational contexts, allowing parallel attacks without human oversight.
- Phase 3 – The AI generated tailored payloads, conducted remote testing, and validated vulnerabilities. It created detailed reports for human review, with humans only stepping in to approve escalation to active exploitation.
- Phase 4 – Claude extracted authentication data from system configurations, tested credential access, and mapped internal systems. It independently navigated internal networks, accessing APIs, databases, and services, while humans authorized only the most sensitive intrusions.
- Phase 5 – Claude used its access to query databases, extract sensitive data, and identify intelligence value. It categorized findings, created persistent backdoors, and generated summary reports, requiring human approval only for final data exfiltration.
- Phase 6 – Throughout the campaign, Claude documented each step in a structured format, including discovered assets, credentials, exploit methods, and extracted data. This enabled seamless handoffs between threat actor teams and supported long-term persistence in compromised environments.
Source: Anthropic
Anthropic further explains that the campaign relied more on open-source tools rather than bespoke malware, demonstrating that AI can leverage readily available off-the-shelf tools to conduct effective attacks.
However, Claude wasn’t flawless, as, in some cases, it produced unwanted “hallucinations,” fabricated results, and overstated findings.
Responding to this abuse, Anthropic banned the offending accounts, enhanced its detection capabilities, and shared intelligence with partners to help develop new detection methods for AI-driven intrusions.

7 Security Best Practices for MCP
As MCP (Model Context Protocol) becomes the standard for connecting LLMs to tools and data, security teams are moving fast to keep these new services safe.
This free cheat sheet outlines 7 best practices you can start using today.
如有侵权请联系:admin#unsafe.sh