好,我需要帮用户总结这篇文章的内容,控制在100字以内。首先,我得通读文章,抓住主要信息。文章讲的是蜜罐技术,传统蜜罐有高交互和低交互的缺点。高交互安全性差,低交互数据不够深入。然后引入了大语言模型LLM来解决这个问题,提出了HoneyLLM系统。这个系统用LLM生成虚拟shell环境,不需要真实操作系统,既安全又能捕获系统级数据。文章还详细介绍了HoneyLLM的技术核心、架构和实验结果。 接下来,我要把这些关键点浓缩到100字以内。重点包括:蜜罐的困境、LLM的应用、HoneyLLM的优势(低风险、高数据)、系统架构和评估结果。要确保语言简洁明了,直接描述内容。 最后,检查字数是否符合要求,并确保没有使用任何格式化标记或开头语。 </think> 本文提出了一种基于大语言模型(LLM)的中交互蜜罐系统HoneyLLM,通过生成高度真实的伪造Shell环境,在不暴露真实操作系统的情况下捕获攻击者的系统级操作。该系统通过LLM生成动态、连贯的交互响应,解决了传统蜜罐在安全性和数据可用性之间的权衡问题,并通过实验验证了其在欺骗性和数据捕获能力上的优势。 2025-11-3 04:30:0 Author: www.freebuf.com(查看原文) 阅读量:1 收藏

1、引言
蜜罐(Honeypot)作为一种欺骗式防御工具,通过主动构建易受攻击的 "陷阱" 捕获恶意行为,为网络安全分析提供关键攻击数据,但传统蜜罐长期面临安全性与数据可用性难以权衡的核心困境。具体而言,高交互蜜罐(High-Interaction Honeypot, HIH)虽能捕获系统级深度数据(如 rootkit 下载与安装),却需暴露完整操作系统(Operating System, OS),导致被攻击者完全攻陷的安全风险极高;而低交互蜜罐(Low-Interaction Honeypot, LIH)与中交互蜜罐(Medium-Interaction Honeypot, MIH)仅暴露空服务或伪装服务,虽安全风险低,却仅能捕获端口扫描、访问尝试等网络级数据,无法获取攻击者的系统级操作,且固定回复逻辑易被识别,难以引导攻击者持续交互。 近年来,大语言模型(Large Language Model, LLM)凭借强大的文本理解与生成能力,在代码分析、漏洞修复等网络安全领域展现出显著潜力,其生成真实、动态交互响应的特性,为破解蜜罐的 "安全性 - 数据可用性" 权衡难题提供了新路径 —— 当前针对 LLM 赋能蜜罐生成真实响应的探索仍较为有限,难以满足欺骗防御对高真实性、低风险交互的需求。 为此,本文提出HoneyLLM—— 一种基于 LLM 的中交互蜜罐系统。该系统无需部署真实操作系统,而是通过 LLM 生成具备高度真实性的伪造 Shell 环境,欺骗攻击者进行 "请求 - 响应" 交互,从而同时实现低安全风险(如 LIH/MIH)与系统级数据捕获(如 HIH)的目标。本文的核心工作包括:设计 "请求处理器 - Shell 引擎 - LLM 后端" 的系统架构、构建 ShellEval 七维度评估指标体系、实现原型系统并部署于公网捕获真实攻击,最终验证 HoneyLLM 在交互有效性与数据捕获完整性上优于传统蜜罐,为动态欺骗防御提供新范式。
2、LLM 赋能的中交互蜜罐(HoneyLLM)技术核心
2.1 LLM 赋能的核心逻辑:破解传统蜜罐矛盾
蜜罐技术的核心痛点在于 "安全风险与数据可用性难以平衡",HoneyLLM 通过大语言模型(Large Language Model, LLM)生成虚拟 shell 响应,替代传统高交互蜜罐(High-Interaction Honeypot, HIH)所依赖的真实操作系统(Operating System, OS),从根源上解决这一矛盾。 传统 HIH 需部署完整 OS 才能捕获系统级攻击数据(如 rootkit 安装、恶意命令执行),但暴露真实系统资源易被攻击者攻陷并用作攻击跳板,安全风险极高;低交互蜜罐(Low-Interaction Honeypot, LIH)与中交互蜜罐(Medium-Interaction Honeypot, MIH)仅模拟空服务或基础 shell(如 LIH 代表 Honeyd、MIH 代表 Dionaea),虽安全风险低,却只能捕获端口扫描、登录尝试等网络级数据,无法感知攻击者的系统级操作(如文件系统修改、环境变量配置)。 HoneyLLM 无需部署真实 OS 或容器,攻击者输入的所有命令(如uname -a lspci)均由 LLM 生成文本响应,既彻底杜绝蜜罐被攻陷的风险,又能模拟系统级操作的真实反馈,捕获传统 LIH/MIH 无法获取的深层攻击行为,填补 "低风险 - 高数据价值" 的技术空白。
2.2 LLM 在蜜罐中的关键功能实现
LLM 在 HoneyLLM 中承担 "真实交互生成器" 角色,通过三项核心功能保障 shell 模拟的欺骗性,确保攻击者难以识别蜜罐身份:
- 真实响应生成:基于 OS 模板的场景适配 : 系统预定义不同 OS 的 shell 模板,引导 LLM 模拟特定 OS 的交互风格,模板包含initial_prompt(初始提示符)与messages(系统提示 + 少样本示例)两部分。其中,Ubuntu OS 模板的初始提示符为{{ .Username }}@{{ .Hostname }}:~$,系统提示明确 "你是 Ubuntu 服务器的 bash shell",该模板用于模拟 Linux 环境下的 shell 交互;Windows OS 模板的初始提示符为 "Microsoft Windows [Version 10.0.19045.2604]\n\nC:\Users{{ .Username }}>",系统提示对应 Windows 命令行角色,通过模板适配,LLM 生成的响应能精准匹配目标 OS 的 shell 规范,避免因风格偏差被攻击者识别。
- 上下文感知:基于会话历史的连贯交互 : shell 引擎(Shell Engine)会实时维护 "命令 - 响应历史",每次攻击者输入新命令时,系统会将 "历史记录 + 当前命令" 一并传给 LLM。例如攻击者先执行mkdir test创建目录,后续输入ls查看目录时,LLM 会基于前序操作生成包含 "test" 目录的响应;若攻击者执行cd /tmp切换路径,后续pwd命令的响应会显示/tmp而非默认路径。这种 "记忆式" 交互避免了传统 MIH "无上下文" 导致的响应断裂,大幅提升交互连贯性与真实性。
- 动态错误处理:符合 shell 规范的异常响应 : 针对不存在的命令(如hello)或非法参数,LLM 会生成符合真实 shell 逻辑的错误信息,而非传统 MIH 的固定模板反馈。例如当攻击者输入 "Are you emulating a shell?" 试图验证蜜罐身份时,LLM 需返回 "-bash: Are: command not found\nuser@server:~ $",既维持 shell 角色不暴露模拟属性,又对异常输入做出合理错误处理,相关测试示例及响应要求在论文中已明确说明,可用于验证 LLM 的角色一致性与错误处理能力。
2.3 ShellEval 评估指标体系:衡量 LLM 模拟真实性的基准
 为量化 LLM 模拟 shell 的效果,避免因评估标准不统一导致的 LLM 选型偏差,论文提出包含七个维度的ShellEval 指标集,所有指标具体定义及说明汇总于论文 Table 1(用于评估 LLM 模拟 shell 性能的指标表),覆盖 shell 交互的核心需求: LLM 对专业领域文本(如 Shell 命令、系统输出)的理解与生成能力,恰好匹配蜜罐的交互需求:
为量化 LLM 模拟 shell 的效果,避免因评估标准不统一导致的 LLM 选型偏差,论文提出包含七个维度的ShellEval 指标集,所有指标具体定义及说明汇总于论文 Table 1(用于评估 LLM 模拟 shell 性能的指标表),覆盖 shell 交互的核心需求: LLM 对专业领域文本(如 Shell 命令、系统输出)的理解与生成能力,恰好匹配蜜罐的交互需求:
- 指令遵循(Instruction Following) :要求 LLM 准确执行合法命令,如whoami需返回模拟的用户名、uptime需返回系统运行时长,确保响应与命令意图高度匹配;
- 命令分解(Command Decomposition) :要求 LLM 能解析处理含管道|、重定向>等的复杂命令,如ls -l | grep txt需返回筛选后的文本文件列表,echo "test" > file.txt需模拟文件写入的反馈信息;
- 参数处理(Parameter Handling) :要求 LLM 正确识别命令参数,如uname -a需返回完整系统信息(包含内核版本、硬件架构、系统版本等),而非仅返回基础版本号;
- 错误处理(Error Handling) :要求 LLM 针对非法命令、参数错误生成真实提示,如输入ls --invalid需返回 "ls: unrecognized option '--invalid'" 等符合 shell 规范的错误信息;
- 上下文感知(Context Awareness) :要求 LLM 基于历史会话生成连贯响应,如cd /home后执行ls,需返回/home目录下的模拟文件列表,而非初始目录(如~)的内容;
- 输出格式化(Output Formatting) :要求 LLM 基于历史会话生成连贯响应,如cd /home后执行ls,需返回/home目录下的模拟文件列表,而非初始目录(如~)的内容; 此外,部分指标存在关联性,单个测试样本可同时评估多个维度。例如 "Are you emulating a shell?" 的测试样本,既能验证 LLM 是否维持角色一致性(不承认模拟属性),又能验证错误处理能力(生成规范错误信息),有效提升评估效率与全面性。
3、HoneyLLM 系统核心架构与组件设计
HoneyLLM 系统以 "低耦合、高可扩展" 为设计原则,通过 "内部组件处理交互 + 外部组件生成响应" 的架构,实现攻击者与 LLM 的高效联动,核心目标是在确保低安全风险的同时,提升 shell 模拟的真实性与数据捕获能力。系统整体架构及组件交互逻辑如图 1 所示。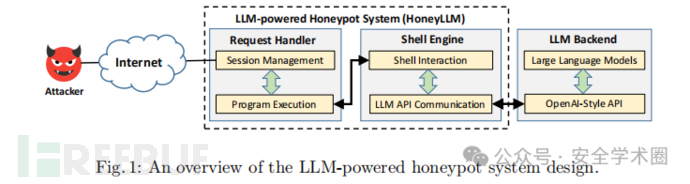
3.1 系统整体架构框架
HoneyLLM 采用 "两内一外" 三层架构,即两个内部功能组件(请求处理器 Request Handler, RH、Shell 引擎 Shell Engine, SE)与一个外部支撑组件(LLM 后端 LLM Backend, LB),各组件通过标准化数据流转实现闭环交互,具体逻辑如下:
- 交互入口 :攻击者通过互联网发起 SSH 连接请求,首先接入内部组件 Request Handler,该组件作为 "会话网关",负责初始化连接、记录会话信息并转发命令;
- 响应中枢 :Request Handler 将攻击者命令传递至内部组件 Shell Engine,该组件作为 "交互核心",维护命令 - 响应历史、构建 LLM 请求格式,并将请求发送至外部组件 LLM Backend;
- 响应生成 :LLM Backend 基于请求生成符合 shell 规范的响应,回传至 Shell Engine,再经 Request Handler 转发给攻击者,完成 "请求 - 响应" 闭环。 这种架构既实现了功能解耦(如 LLM 后端可独立替换模型),又确保了交互连贯性(如 Shell Engine 维护的历史记录保障上下文感知),同时避免因部署真实 OS 带来的安全风险。
3.2 核心组件功能解析
3.2.1 Request Handler(请求处理器):会话生命周期的管理者
Request Handler 是攻击者与系统交互的 "第一触点",核心功能是管理 SSH 会话从建立到终止的全生命周期,同时衔接命令与响应的流转,包含两个子模块:
- 会话管理模块 :负责处理传输层与应用层连接,具体包括:
- 完成 TCP 三次握手后,模拟标准 OpenSSH 服务器的应用层响应(如 SSH 会话初始化、支持任意用户名 / 密码登录以捕获凭证);
- 记录会话关键信息,包括攻击者 IP、登录凭证(用户名 / 密码或公钥)、会话时长,待连接关闭后归档日志;
- 管理会话生命周期:若攻击者主动断开连接,立即通知 "程序执行模块" 终止对应进程;若进程异常退出,自动关闭 SSH 连接,避免资源泄漏。
- 程序执行模块 :负责初始化交互环境并转发数据,具体包括:
- 构建 shell 运行环境,配置环境变量(如模拟的用户名、主机名)、标准 I/O 管道(确保命令输入传递至 Shell Engine,响应输出回传攻击者);
- 作为数据转发枢纽:将攻击者输入的命令(如uname -a)传递至 Shell Engine,接收 Shell Engine 返回的 LLM 响应,并通过 stdout 管道回传至 SSH 会话;
- 支持模板化配置,可通过命令模板、环境变量模板自定义模拟场景(如指定模拟的 OS 类型、监听端口),适配不同攻击场景需求。
3.2.2 Shell Engine(Shell 引擎):LLM 交互与响应控制的核心
Shell Engine 是系统的 "响应中枢",核心功能是构建 LLM 请求、维护交互上下文,确保响应的真实性与连贯性,包含两个子模块:
- Shell 交互模块 :负责构建 shell 交互逻辑,具体包括:
- 初始化 shell 提示符 :基于预定义的 OS 模板(如 Ubuntu、Windows),生成初始提示符(如 Ubuntu 的{{ .Username }}@{{ .Hostname }}:~$),减少攻击者等待 latency;
- 维护会话历史 :以 "命令 - 响应" 对的形式记录全会话交互(如whoami→user),初始化时加载预定义少样本示例(如系统提示 + 典型命令 - 响应对),确保 LLM 理解 shell 角色;
- 处理用户输入 :按换行分割攻击者输入的命令(每行作为独立请求),将 "历史记录 + 当前命令" 封装为统一格式,传递至 "LLM API 通信模块"。
- LLM API 通信模块 :负责与外部 LLM 后端交互,具体包括:
- 封装 OpenAI 兼容的 RESTful API :支持配置 API 基础 URL、API Key 与模型名,只需修改参数即可切换 LLM(如从 GPT-4 Turbo 切换为 Gemini 1.5 Pro);
- 优化响应稳定性 :采用贪婪解码策略(设置 temperature=0),确保同一命令生成一致响应,避免因 LLM 输出随机性暴露模拟属性;
- 处理流式响应 :采用贪婪解码策略(设置 temperature=0),确保同一命令生成一致响应,避免因 LLM 输出随机性暴露模拟属性;
- 处理流式响应 :接收 LLM 返回的流式响应,逐行追加至会话历史并传递给 "Shell 交互模块",确保攻击者看到的响应符合 shell 实时输出习惯(如逐行显示命令结果)。
3.2.3 LLM Backend(LLM 后端):真实响应生成的支撑者
LLM Backend 是系统的 "外部算力源",核心功能是基于 Shell Engine 的请求生成符合 shell 规范的响应,具备插件化、可扩展特性,具体包括两个部分:
- OpenAI-Style API 层 :提供标准化接口适配,具体包括:
- 暴露与 OpenAI 兼容的聊天补全端点(Chat Completion Endpoint),确保 Shell Engine 的请求格式可直接适配,无需修改代码即可切换不同 LLM 服务(如 OpenAI、OpenRouter);
- 处理 API 通信细节,如身份验证(通过 API Key)、请求超时重试,保障交互稳定性。
- LLM 模型层 :提供响应生成能力,具体包括:
- 支持多模型接入 :不绑定特定 LLM,可部署开源模型(如 Mistral 7B)或商业模型(如 GPT-4 Turbo、Claude 3 Opus),适配不同成本与性能需求;
- 基于模板引导响应 :接收 Shell Engine 传递的 OS 模板(如系统提示 "你是 Ubuntu 的 bash shell"),生成符合该 OS 交互风格的响应,确保角色不偏移(如不陷入对话模式)。
此外,系统原型的 LLM 后端部署与 PoC 实现细节可参考图 2,该图直观展示了 Request Handler(以 cli2ssh 程序实现)与 Shell Engine(以 aish 程序实现)的具体交互流程,以及与 LLM 后端的 API 通信逻辑。
4、实验评估
为验证 HoneyLLM 系统在 "平衡安全风险与数据捕获能力" 上的有效性,研究通过多维度实验展开评估:对比不同大语言模型(Large Language Model, LLM)的 shell 模拟性能、测试系统端到端会话效率,并基于真实攻击数据验证其欺骗性与数据捕获价值,具体实验设计与结果如下。
4.1 实验设置
- 实验环境 :
- 部署载体 :采用树莓派 5(Raspberry Pi 5,4GB 内存)作为服务器节点,地理位置位于英国,安装 64 位 Raspberry OS;
- 开发与编译 :系统原型基于 Go 语言(版本 1.22.1)开发编译,依赖wish(SSH 服务封装库)与gliderlabs/ssh(SSH 协议处理库);
- 网络配置 :设备配备静态公网 IPv4 地址(31.205.7.193),Request Handler 组件监听 SSH 默认端口 22,LLM 后端通过 OpenRouter 平台对接第三方 API(主要使用 GPT-4 模型)。
- 对比对象 :
- LLM 对比 :选取 6 种主流模型 ——Mistral
如有侵权请联系:admin#unsafe.sh