好的,我现在需要帮用户总结一篇关于Agentic AI安全工作流的文章,控制在100字以内。首先,我得通读文章,抓住主要观点。 文章讨论了将可利用性验证与业务背景和自主验证结合的工作流,强调从原型到生产的架构决策。提到了编排框架如LangGraph、AutoGen等,以及它们如何协调多个MCP服务器的查询。还涉及了集成点,如资产管理、票务系统、CI/CD工具等。 然后是扩展考虑,包括网络容量和测试频率的平衡,采用快速验证、风险触发和批量测试的混合策略。失败模式方面,处理基础设施不可用、业务上下文服务器故障等情况的方法也很重要。 最后是人机协作部分,组织根据政策、资产关键性和行动严重性来调整监督。文章建议根据具体情况定制架构,并强调持续跟踪技术发展的重要性。 现在需要将这些内容浓缩到100字以内。重点包括:架构决策、编排框架、集成系统、扩展策略、失败处理和人机协作。确保语言简洁明了。 </think> 文章探讨了构建基于自主AI的安全工作流的架构考虑,包括编排框架选择、系统集成点、扩展挑战及人机协作设计。重点在于如何通过有效编排协调多源数据,处理大规模场景下的可靠性问题,并确保在高风险决策中的人类监督机制。 2025-10-22 19:56:37 Author: horizon3.ai(查看原文) 阅读量:15 收藏
Architectural Considerations for Agentic AI Security Workflows
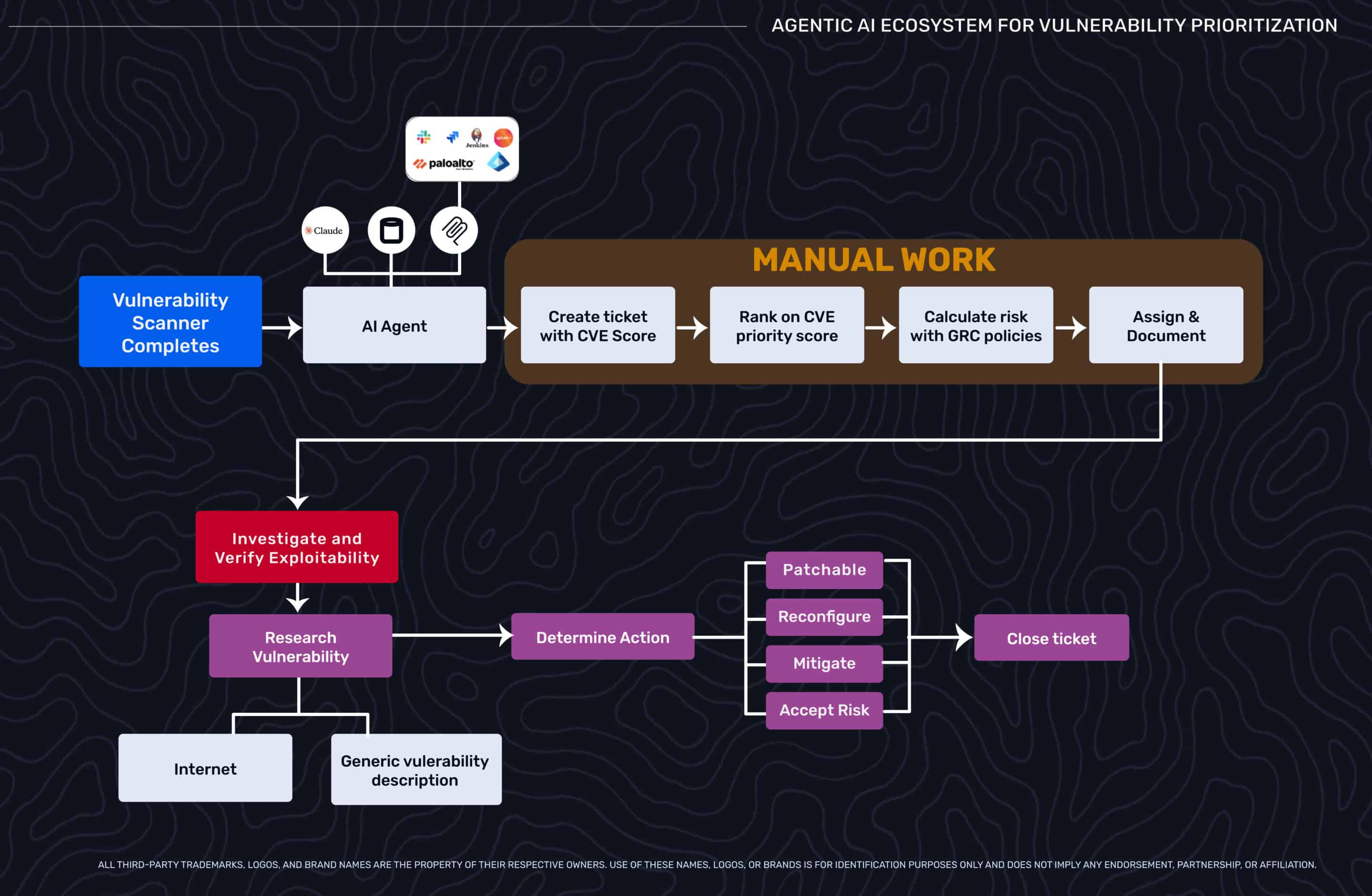
The workflows described in our previous blog demonstrate what’s possible when you combine exploitability validation with business context and autonomous verification. Building them requires real engineering work. This isn’t an exhaustive implementation guide—that depends heavily on your existing infrastructure, orchestration preferences, and organizational constraints. Instead, this covers the architectural decisions and patterns we’ve seen matter most when teams move from prototype to production. Consider this a starting point to help you think through orchestration frameworks, integration patterns, scaling challenges, failure modes, and human oversight calibration. The goal: help you avoid common pitfalls and design workflows that work reliably at scale rather than fail spectacularly under load.

Orchestration Frameworks
Production workflows require orchestration layers to coordinate queries across multiple MCP servers, apply decision logic, and manage state. Production implementations typically use agent frameworks like LangGraph, AutoGen, n8n, or custom Python orchestrators.
These systems issue parallel queries to autonomous pentesting platforms and business context servers, synthesize priorities, and handle inevitable failures. Each MCP server returns data in different formats, requiring transformation layers to standardize schemas before synthesis. Effective prompt engineering improves how agents interpret and act on multi-source context—well-crafted prompts reduce ambiguity and improve decision quality. Common patterns include treating verification timeouts as inconclusive and escalating to human review, restarting the fix-verify loop with additional context when autonomous pentests confirm weaknesses remain exploitable, and degrading gracefully to exploitability-only prioritization when business context servers are unavailable.
When synthesizing context from multiple sources, LLMs can occasionally make logical leaps not warranted by the data. This is why human oversight remains important for high-stakes decisions, particularly when recommendations combine complex technical and business factors. Well-designed workflows include validation checkpoints where confidence thresholds or decision complexity trigger human review.

Common Integration Points
Successful implementations typically integrate several categories of systems:
- Asset Management: Systems like Axonius or ServiceNow CMDB for configuration data and asset inventory
- Ticketing: Jira, ServiceNow, or Linear for incident tracking and assignment
- CI/CD: Jenkins, Argo, or GitLab for automated deployment of fixes
- Business Intelligence: Project management platforms, financial forecasting tools, CRM systems for organizational context
- Communication: Slack or Microsoft Teams for notifications and on-call escalation
- Security Tools: Autonomous pentesting platforms for exploitability validation and verification, SIEM/EDR for threat intelligence correlation
Scaling Considerations
Network capacity and testing cadence are interrelated. If infrastructure can’t handle simultaneous pentests, implement central queuing by priority score. The most effective approach combines three strategies:
- Rapid verification of known weaknesses (results in minutes) for immediate feedback on fixes
- Risk-based triggering for immediate threats like authentication changes or new internet exposure
- Scheduled batch testing for routine updates and comprehensive coverage
This hybrid pattern maximizes coverage while optimizing resources—use rapid verification to close remediation loops, trigger full pentests when risk signals warrant it, and batch lower-priority changes.
At scale with hundreds or thousands of findings, filter before querying business context. Prioritize findings with domain admin or data access impact, then layer business context on the top 50-100 findings to prevent overwhelming both systems and reviewers.
Handle regression gracefully. When verification tests confirm a previously-fixed weakness is exploitable again (security regression), workflows should automatically elevate priority, notify on-call teams, and mark related tickets for re-opening. This catches configuration drift, incomplete fixes, or new attack techniques that bypass previous remediation.
Failure Modes and Resilience
Production workflows need robust error handling:
- Pentest infrastructure unavailable: Queue requests and continue with enrichment from available sources. Flag items needing verification for later testing.
- Business context servers down: Degrade to exploitability-only prioritization. Still better than CVSS-based triage.
- Verification inconclusive: Treat as requiring human review. Better to escalate than falsely confirm.
- Fix deployment fails: Capture error context and retry with modified approach. Some fixes require iterative refinement.
The goal is graceful degradation that maintains workflow progress when components fail, while ensuring ambiguous or failed automation escalates appropriately.
Human-in-the-Loop Considerations
Autonomous verification works across complex environments—the question isn’t technical capability but organizational risk tolerance. Organizations calibrate oversight based on three factors: organizational policies (change control requirements, regulatory mandates), asset criticality (production vs development, revenue-generating vs internal), and action severity (patch deployment vs infrastructure modification). Financial services and healthcare often mandate human approval for production changes regardless of automation confidence. Compliance frameworks (SOX, HIPAA, PCI-DSS) may require human attestation and audit trails even when automation performs reliably. Business-critical systems may require coordinated testing during maintenance windows. Zero-day vulnerabilities warrant human assessment before automated verification at scale. Well-designed workflows make oversight configurable: high-confidence actions on low-criticality assets proceed autonomously, medium-confidence or high-criticality scenarios trigger approval workflows, and low-confidence or high-blast-radius actions always escalate.
Building Deliberately
These patterns provide a starting point, not a blueprint. Your infrastructure, risk tolerance, and organizational constraints will drive different architectural choices. Use these concepts to identify which workflows make sense for your environment and where automation fits your comfort zone. This isn’t casual work—the customization required to integrate with your systems controls, handle your specific failure modes, and calibrate oversight appropriately takes real engineering time. But that customization isn’t overhead, it’s where you ensure the architecture is secure, resilient, and aligned with your risk tolerance. Remember that agentic AI and the MCP protocol are relatively new technologies. Security protocols and standards are constantly evolving. Track changes from the MCP specification itself and updates from your AI client vendors—what works securely today may require adjustment as the ecosystem matures. Do your research, understand your constraints, and build deliberately.
如有侵权请联系:admin#unsafe.sh