
好的,我现在需要帮用户总结一篇文章的内容,控制在100字以内。首先,我得仔细阅读文章,理解其主要目的和步骤。 文章主要讲的是如何使用Python从图像中提取文本。作者提到了OCR技术,并详细介绍了所需的库和安装步骤,包括pytesseract、opencv-python和pillow。然后分步骤讲解了如何导入库、加载图像、预处理图像以及提取文本,并保存结果。 用户的要求是用中文总结,不需要特定的开头,直接描述内容。我需要抓住关键点:Python、OCR、步骤(安装库、预处理图像、提取文本)、适用人群(开发者和普通用户)。 接下来,我要把这些信息浓缩到100字以内,确保语言简洁明了。可能的结构是:介绍技术,说明适用人群,简述步骤和优势。 最后检查一下是否符合要求,没有使用禁止的开头,并且字数控制在范围内。 </think> 文章介绍如何使用Python通过OCR技术从图像中提取文本。适用于开发者或普通用户自动化处理大量图像文件。步骤包括安装Python、相关库(pytesseract、opencv-python等)、Tesseract OCR引擎及配置环境。通过预处理图像(如转灰度、二值化)提升提取准确性,并保存结果为可编辑文本。 2025-10-13 10:47:44 Author: securityboulevard.com(查看原文) 阅读量:145 收藏

When you get a scanned file or a screenshot that has text, it looks fine at first. But the problem comes when you need that text in editable form. Typing everything manually takes too much time and also brings mistakes. If you have many image files, the problem grows even bigger and slows down all the work.
This is where Python helps. Using OCR with it, you can pull out the text from images and scanned papers in a simple way. In this guide, I will explain how you can do it step by step. This guide is for both developers wanting to build a text extraction model and anyone looking to automate turning images into editable text.

What’s Required for Text Extraction in Python?
Before you start doing the coding part, first you need to make sure the setup is ready. Without these things, nothing will run.
Install Python
If you have not installed Python already, go to the official Python website and download the latest version. Install it on your system.
Install Required Python Libraries
Well, the next thing is Python libraries. Go to the command prompt and write the following command there, and then run it. This will install the necessary libraries.
Command:

This will install:
-
pytesseract: to extract text using OCR
-
opencv-python: to process and prepare the image
-
pillow: to handle image files
Install Tesseract OCR Engine
Now, one thing to remember, pytesseract alone will not do the job. It needs the main Tesseract OCR engine in your system; otherwise, the code will not run.
-
For Windows users, just download the installer from the official Tesseract page and install it like any normal software.
-
For macOS, if you are using Homebrew, simply run the “brew install tesseract” command.
-
For Linux, you can install it from the package manager, e.g., “sudo apt install tesseract-ocr”.
Once it is done, pytesseract can connect with it, and then everything will start working fine.
Set Tesseract Path in Python (Only for Windows)
You need to give Python the address of the Tesseract engine after installation. Add the address of the folder where you installed it, like

Replace the path if you installed it in a different location. After completing these steps, your system will be ready to extract text from images using Python.
Steps To Detect And Extract Text from an Image Using OCR In Python
Import Required Libraries
Now after installing everything, you need to bring those tools inside your Python file. Without this, nothing will work. Open your editor and start with a few clean lines of code. You need
-
cv2 from OpenCV to handle image reading and processing
-
pytesseract to connect with the OCR engine
-
PIL.Image from Pillow for image format support,
-
numpy for handling image arrays.
So, run the code as in the snippet below:

These imports will cover almost everything you need for text extraction. It's easier to keep the script updated when you keep imports short and clear. With them, you can load images, prepare them, and pass them to Tesseract for detection.
Load the Image File
After importing, the next step is to load your image. You can use OpenCV or Pillow for this. Both do the same job but in a little different way. With OpenCV, you use cv2.imread, while with Pillow, you use Image.open. Once you load it, it is good to check if the image is opening fine before moving further. Write code as:

This way, you can see the image first and be sure it is ready for processing.
Preprocess Image for Better Results
Before extracting text, the image should be cleaned a bit. If an image is dark or noisy, OCR will not read it correctly. So you have to convert it into grayscale to reduce colors. It will leave only the shades of gray color that make text easier to isolate. Then you can apply a threshold to make the text more clear. Some images also need to be denoised or resized for better results. To convert the image to grayscale, write the code as it is below in the snippet:

This small cleaning step helps OCR catch letters more properly.
Extract Text from Image
Now that the image is ready, we can pull text out. For normal text, you can use “image_to_string()”. If you also want each word with a bounding box and a confidence score, then use “image_to_data()”.

The first one gives you plain text only. The second one gives table-like output with words, x-y positions, and confidence score. This way, you can use text directly or process it more in Python.
Save Extracted Text
After getting the text on screen, the next job is to save it somewhere. Mostly we save in .txt files, but you can also put in .csv if you want structured data.

This way, you don’t lose the output after the program ends. Later, you can open this file in Notepad, Word, or even Excel if you use .csv.
Get Inspiration from Image Extraction Tools to Improve Your Python OCR
You can also get inspiration from an online OCR tool to make your Python model even better. These tools handle real problems like unclear images, mixed layouts, and different languages. Seeing how they manage these things might give you new ideas.
OCR.best is a prominent example. It uses smart methods such as image preprocessing, text detection, and post-processing. You can study this tool to use the same ideas in your text-extraction model to improve results. I tried it with an image, and here's how it responded:
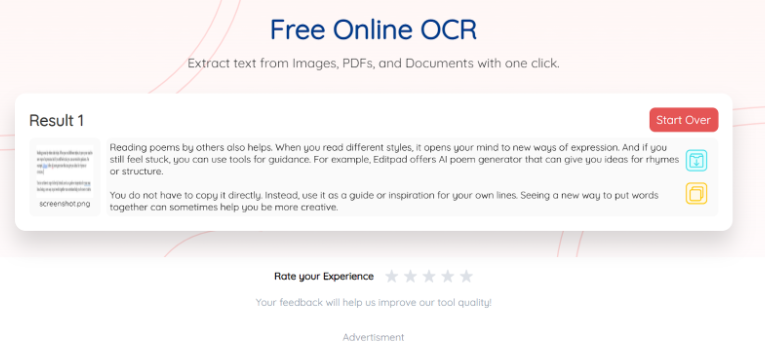
Wrapping it Up
The digitization of paper documents and images containing text data was a difficult task. But now, with the advancement of technology, there are multiple ways to do it. I have described how one can do it using Python. It’s simple and easy as long as you are following the right steps. You can also get inspiration from OCR tools available online to make your Python model more efficient and accurate.
*** This is a Security Bloggers Network syndicated blog from SSOJet - Enterprise SSO & Identity Solutions authored by SSOJet - Enterprise SSO & Identity Solutions. Read the original post at: https://ssojet.com/blog/python-ocr-text-extraction-guide
如有侵权请联系:admin#unsafe.sh