



官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序

在信息收集的过程往往遇到以下问题:
- 网络空间搜素引擎和诸多扫描工具如kscan、fscan等,所探测到的web资产,存在大量状态码为302、200的页面没有标题,也识别不出是什么东西,有一些页面是真的没有标题,但更多的页面其实是由于扫描器没有跟随跳转,无法得到最终页面,所以标题是空。无法得到最终页面的原因,要么是没有跟随状态码,要么是状态码为200但在页面js中进行了跳转,由于扫描器无法渲染js因此无法跟随。基于这样的原因,导致很多资产搞不清楚它是什么,更搞不清楚它是什么性质。
- 由于任务目标的语言问题,往往从页面标题看不出其性质,哪怕手动打开页面也需要翻译,判断一个网站是否归属于目标比较困难。
- 得到了大量目标域名和ip,想要探测目标c段找找还有没有目标资产,但哪怕探测到了web资产也面临上述问题1和问题2,整体来说是个体力活。
为解决以上问题,笔者开发了whatscan,可以对批量URL进行web扫描、截屏、标题翻译、高频词识别、web组件识别,输出为excel和word文档,翻遍整理和撰写报告。 整体来说,whatscan的功能如下:
- web资产识别(CMS/应用组件/容器/编程语言等信息)
- 支持对web站点截屏
- 支持浏览器模拟,解决普通爬虫对js无法渲染的短板,可识别js跳转得到真实页面和标题
- 支持标题翻译(调用google翻译,因此需要翻墙)
- 支持从页面提取高频词并翻译
- 支持IP反析域名
- 支持导出word文档和excel
- 适合从核心资产提取了c段后,对多个c段内的资产进行探测和梳理,看看存在什么东西,有没有需要关注的资产
输入的url文件在上面的ini文件中设置即可,程序默认从./input文件里找输入文件。 然后可直接执行: python whatscan.py 输出的word和excel保存在 output/<时间戳>下,如下图。
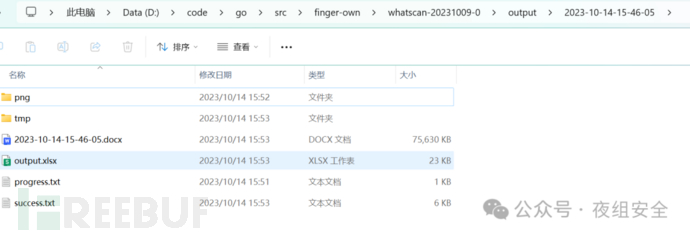
程序运行时,请勿打开xlsx或tmp下的word文件,以免最后合并文档时无法读取被office占用的文档。 若在程序运行时ctrl+c结束了程序,可能造成chrome进程意外留存,可执行项目目录下的kill-chrome.bat关闭本机所有chrome和chromedriver进程。
excel
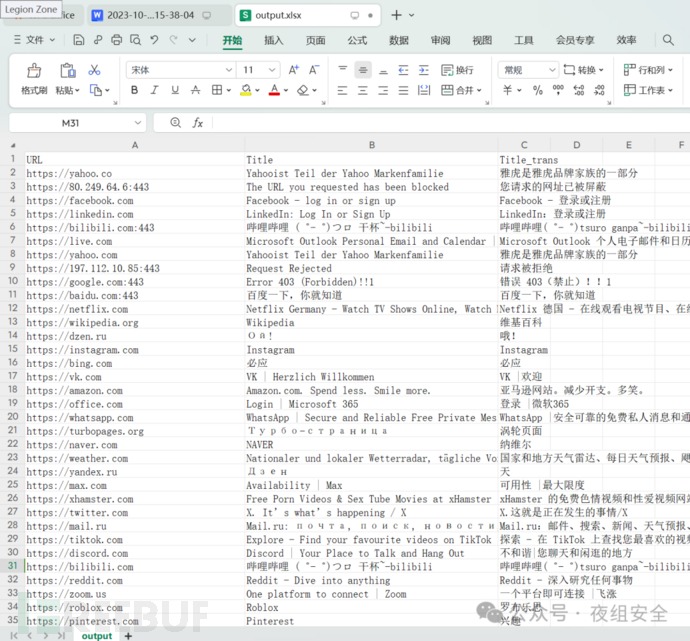
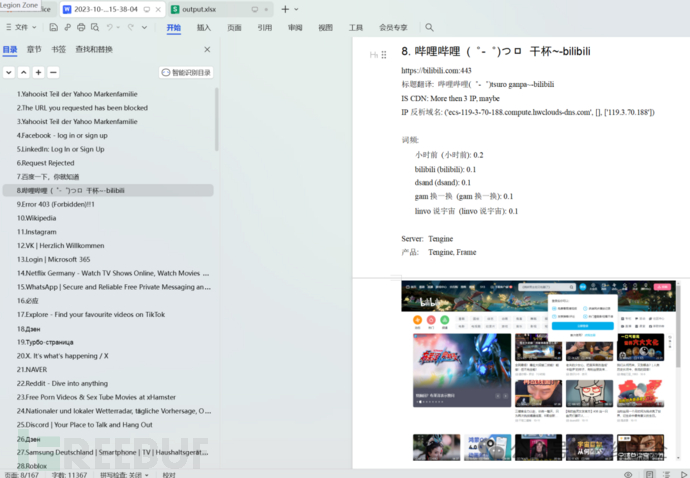
word
其中,"产品"对应的信息就是kscan的指纹识别结果。
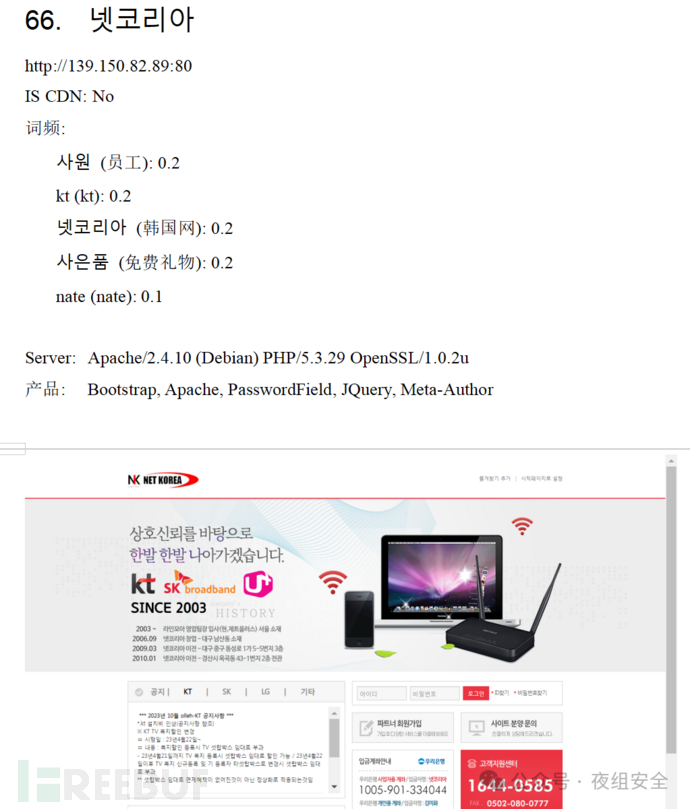
https://github.com/killmonday/whatscan
免责声明
1.一般免责声明:本文所提供的技术信息仅供参考,不构成任何专业建议。读者应根据自身情况谨慎使用且应遵守《中华人民共和国网络安全法》,作者及发布平台不对因使用本文信息而导致的任何直接或间接责任或损失负责。
2. 适用性声明:文中技术内容可能不适用于所有情况或系统,在实际应用前请充分测试和评估。若因使用不当造成的任何问题,相关方不承担责任。
3. 更新声明:技术发展迅速,文章内容可能存在滞后性。读者需自行判断信息的时效性,因依据过时内容产生的后果,作者及发布平台不承担责任。
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)