作者: 我是小三
博客: http://www.cnblogs.com/2014asm/
由于时间和水平有限,本文会存在诸多不足,希望得到您的及时反馈与指正,多谢!
工具环境: windwos10、IDEA
目录 :
为什么需要保护?保护后性能如何?
市面上常见的解决方案
整体加密保护方案架构
class文件格式与反汇编引擎浅析
LLVM IR介绍
技术实现细节分析
总结1.为什么须要保护?
由于Java的指令集比较简单而通用,较容易得出程序的语义信息,Java编译后的Jar包和Class文件,可以轻而易举的使用反编译工具(如JD-GUI)进行反编译,拿到源码。
目前,市场上有许多Java的反编译工具,有免费的,也有商业使用的,还有的是开放源代码的。这些工具的反编译速度和效果都非常不错。好的反编译软件,能够反编译出非常接近源代码的程序。因此,通过反编译器,黑客能够对这些程序进行更改,或者复用其中的程序,核心算法被使用等。因此,如何保护Java程序不被反编译,是非常重要的一个问题。
2.保护后性能如何?
由于java跨平台的需求,在某些情况下须要使用jvm虚拟机来解释执行编译后的 java字节码,可能很多人会担心在此基础上再做一层保护会使得程序变得更低效。其实这个主要与加密方案有关,我们这个方案的原理是将java字节码转换成对应平台的二制代码。去掉了jvm虚拟机,将程序直接运行在真实的CPU上,这样反而会提高原本的程序执行效率。
由于Java字节码的抽象级别较高,使得它较容易被反编译,因此Java代码反编译要比其他开发语言更容易实现,并且反编译的代码经过优化后几乎可与源代码相媲美。为了避免出这种情况,保护软件知识产权的目的,就出现了各种各样的加密保护方式。
1.远程调用Java程序
最简单的方法就是让用户不能够拿到Jar程序,这种方法是最根本的方法,具体实现有多种方式。例如,开发人员可以将关键的jar放在服务器端,客户端通过访问服务器的相关接口来获得服务,而不是直接本地调用jar文件。这样黑客就没有办法反编译Class文件。目前,通过接口提供服务的标准和协议也越来越多,例如 HTTP、Web Service、RPC等。但是有很多应用都不适合这种保护方式,例如单机运行的程序或者须要很大网络流量的程序就无法远程调用Java程序。这种保护方式如图1所示。
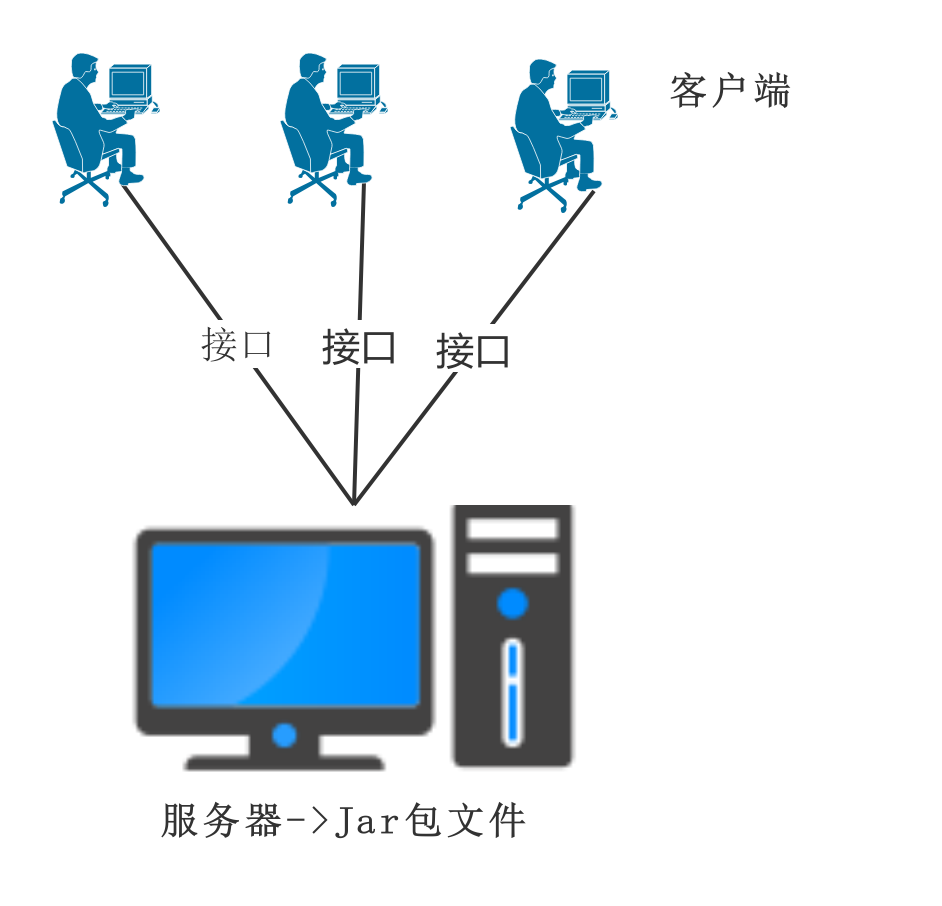
图1
2.自定义ClassLoader
为了防止Class文件被直接反编译,许多开发人员将一些关键算法的Class文件进行加密,在使用这些class被加载之前,程序首先需要对这些类进行解密,而后再将这些类装载到JVM当中。大致流程如图2。
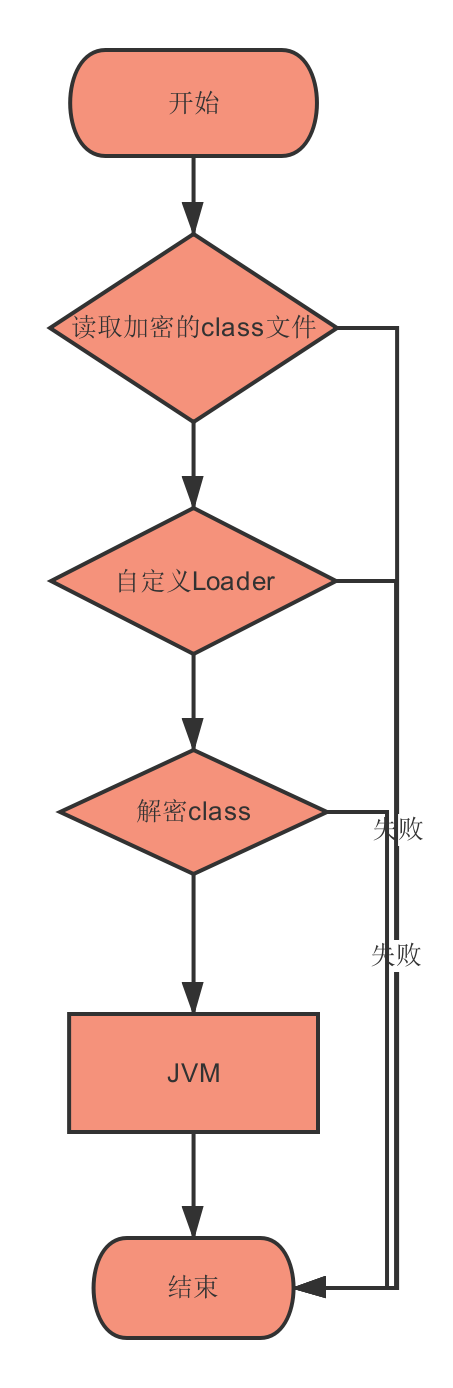
图2
这种方法首先需要对编写代码对类文件进行加密,然后自己编写类加载器解密加载,在往JAVA虚拟机导入class文件的同时进行class文件的解密,这种方式存在被内存dump的风险。
3.代码混淆
代码混淆是对Class文件进行重新组织和处理,使得处理后的代码与处理前代码完成相同的功能(语义)。但是反编译后得出的代码是非常难懂、晦涩的,因此反编译人员很难得出程序的真正语义。但是也只是增加了分析时间,被混淆的代码仍然可能被破解的风险。
4.转换成本地代码
将程序转换成本地代码也是一种防止反编译的有效方法。因为本地代码往往难以被反编译。开发人员可以选择将整个应用程序转换成本地代码,也可以选择关键模块转换。如果仅仅转换关键部分模块,Java程序在使用这些模块时,需要使用JNI技术进行调用。
当然,在使用这种技术保护Java程序的同时,也牺牲了Java的跨平台特性。对于不同的平台,我们需要维护不同版本的本地代码,这将加重软件支持和维护的工作。不过对于一些关键的模块,有时这种方案往往是必要的。
为了保证这些本地代码分析难度,我们可以通过对这些代码进行二进制混淆或部分VM,加大分析难度。我们本次也是使用这种方式。
整体方案主要通过解析class文件并且转化成一种和平台无关的中间语言。最后通过调用相关JNI方法。这种保护方式如图3。
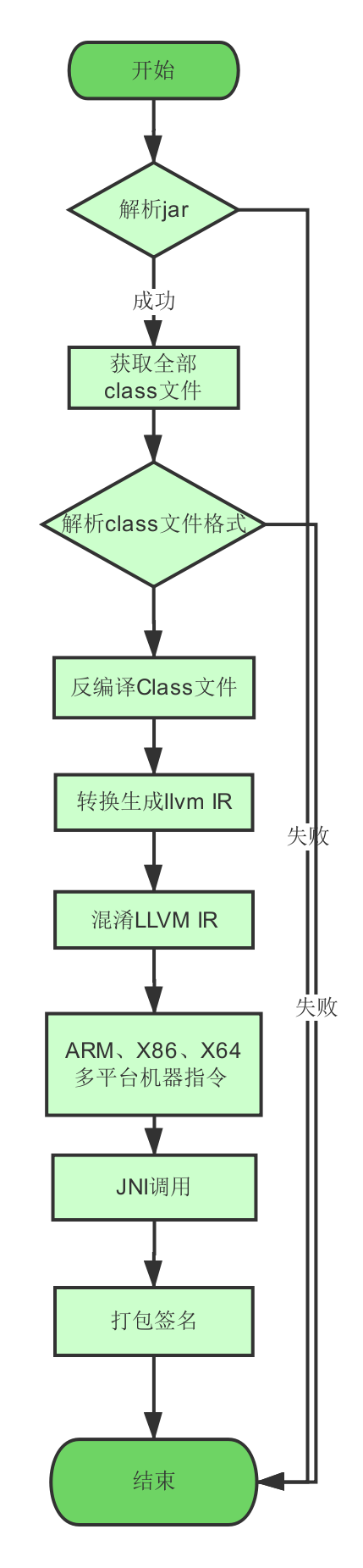
图3
以上就是整体的加密保护框架。
1.class文件格式
写过java程序的都知道,java代码运行,需要先编译成class文件,再经由JVM加载来解释执行。那class文件中,都存放了哪些信息,JVM又是如何通过加载这些信息来执行我们的java代码的。反编译工具又是如何还原其代码的呢?通过了解class文件,有助于我们理解实现机制。
class文件结构如下,u2、u4分别代表2、4个字节长度:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
其中:magic:魔数,占用4个字节,固定值为“0xCAFEBABE”,用于标识这是一个class文件。
minor_version、major_version:class文件次、主版本号,分别占用2个字节,一般高版本的JVM能够加载低
methods_count:该类或接口拥有的方法数。
methods:列表每一下为method_info数据,method_info结构如下:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
上面这个结构是我们比较关心的,会定位到方法指令,在转换IR过程中占比较重。其它的字段都是按照以上格式进行解析。
下面是部分解析代码:
public Method(DataInputStream dis, ConstantPool cp) throws IOException, InvalidConstantPoolIndex {
mf = new MethodFormatter();
/* Parsing access and property modifier */
accessFlags = dis.readUnsignedShort();
accessModifier = mf.setModifier(accessFlags);
/* Parsing the method name */
nameIndex = dis.readUnsignedShort();
cpEntry = cp.getEntry(nameIndex);
if (cpEntry instanceof ConstantUtf8) {
constantUtf8 = (ConstantUtf8) cpEntry;
methodName = new String(constantUtf8.getBytes());
//if (!methodName.equals("<init>")) methodName += "()"; // enable () front of method except <init>. uncomment if want
}
/* Parsing the method descriptor */
descriptorIndex = dis.readUnsignedShort();
cpEntry = cp.getEntry(descriptorIndex);
if (cpEntry instanceof ConstantUtf8) {
constantUtf8 = (ConstantUtf8) cpEntry;
descriptor = constantUtf8.getBytes();
/* Parse return type & parameters */
returnType = mf.parseReturnType(descriptor);
parameters = mf.parseParameters(descriptor);
}
/* Parsing the method attributes */
attributesCount = dis.readUnsignedShort();
attributes = new Attribute[attributesCount];
for (int i = 0; i < attributesCount; i++) {
attributes[i] = new Attribute(dis, cp);
}
}
2.ASM反汇编引擎
ASM是一个Java字节码操控框架。它能被用来动态生成类或者增强既有类的功能。ASM是Java中比较流行的用来读写字节码的类库,用来基于字节码层面对代码进行分析和转换。在读写的过程中可以加入自定义的逻辑以增强或修改原来已编译好的字节码功能。
ASM关键类与接口:
在ASM的核心实现中,它主要有以下几个类、接口(在org.objectweb.asm包中):
ClassReader类:字节码的读取与分析引擎。它采用类似SAX的事件读取机制,每当有事件发生时,调用注册的ClassVisitor、AnnotationVisitor、FieldVisitor、MethodVisitor做相应的处理。
ClassVisitor接口:定义在读取Class字节码时会触发的事件,如类头解析完成、注解解析、字段解析、方法解析等。
AnnotationVisitor接口:定义在解析注解时会触发的事件,如解析到一个基本值类型的注解、enum值类型的注解、Array值类型的注解、注解值类型的注解等。
FieldVisitor接口:定义在解析字段时触发的事件,如解析到字段上的注解、解析到字段相关的属性等。
MethodVisitor接口:定义在解析方法时触发的事件,如方法上的注解、属性、代码等。
ClassWriter类:
它实现了ClassVisitor接口,用于拼接字节码。
AnnotationWriter类:它实现了AnnotationVisitor接口,用于拼接注解相关字节码。
FieldWriter类:它实现了FieldVisitor接口,用于拼接字段相关字节码。
MethodWriter类:它实现了MethodVisitor接口,用于拼接方法相关字节码。
ClassReader是ASM中最核心的实现,它用于读取并解析Class字节码。整体关系如图4所示:

图4
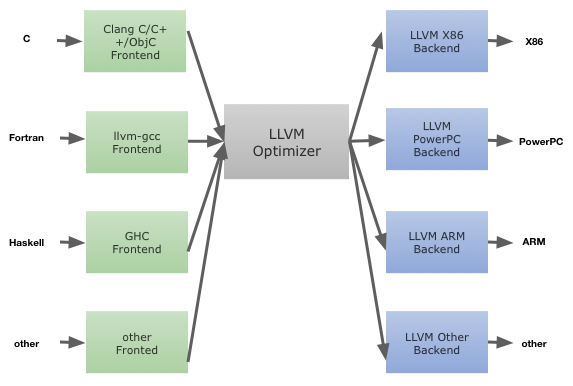
llvm(low level virtual machine)是一个开源编译器框架,llvm有一个表达形式很好的IR语言,高度模块化的结构,因此它可以作为多种语言的后端,提供与编程语言无关的优化和针对多种CPU的代码生成功能。
如图5所示:

图5
好处是不同的前端后端使用统一的LLVM IR ,如果需要支持新的编程语言或者新的设备平台,只需要开发对应的前端和后端即可。同时基于LLVM IR 我们可以将我们的java字节码转换成IR可用不同的后端进行编译到不同平台运行。
1.读取Jar包中的class文件进行转换IR。
InputStream is = new FileInputStream(fn); ClassReader cr = new ClassReader(is); cr.accept(sc, 0);
调用ClassReader读取并解析Class字节码,分发到accept去处理逻辑,部分代码。
public void accept(final ClassVisitor classVisitor, final int parsingOptions) { accept(classVisitor, new Attribute[0], parsingOptions); // Visit the fields and methods. int fieldsCount = readUnsignedShort(currentOffset); currentOffset += 2; while (fieldsCount-- > 0) { currentOffset = readField(classVisitor, context, currentOffset); } int methodsCount = readUnsignedShort(currentOffset); currentOffset += 2; while (methodsCount-- > 0) { currentOffset = readMethod(classVisitor, context, currentOffset);//读取方法 } }
读取方法指令,部分代码如下:
private int readMethod( final ClassVisitor classVisitor, final Context context, final int methodInfoOffset) { // Visit the non standard attributes. while (attributes != null) { // Copy and reset the nextAttribute field so that it can also be used in MethodWriter. Attribute nextAttribute = attributes.nextAttribute; attributes.nextAttribute = null; methodVisitor.visitAttribute(attributes); attributes = nextAttribute; } // Visit the Code attribute. if (codeOffset != 0) { methodVisitor.visitCode(); readCode(methodVisitor, context, codeOffset); } }
根据不同的指令,做不同的IR转换,部分代码如下:
private void readCode( final MethodVisitor methodVisitor, final Context context, final int codeOffset) { while (currentOffset < bytecodeEndOffset) { final int bytecodeOffset = currentOffset - bytecodeStartOffset; final int opcode = classBuffer[currentOffset] & 0xFF; switch (opcode) { case Constants.SIPUSH: methodVisitor.visitIntInsn(opcode, readShort(currentOffset + 1)); currentOffset += 3; break; } }
根据指令(opcode)转换成对诮的LLVM IR,部分代码如下:
public void visitIntInsn(final int opcode, final int operand) { if (mv != null) { mv.visitIntInsn(opcode, operand); } } public void visitVarInsn(int opcode, int slot) { switch (opcode) { case Opcodes.ILOAD: // 21 case Opcodes.LLOAD: // 22 case Opcodes.FLOAD: // 23 case Opcodes.DLOAD: // 24 case Opcodes.ALOAD: // 25 { LocalVar lv = this.vars.get(slot); String type = Util.javaSignature2irType(this.cv.getStatistics().getResolver(), lv.signature); String s = stack.push(type); out.comment(type + "load " + slot); out.add(s + " = load " + type + ", " + type + "* %" + lv.name); } break; case Opcodes.ISTORE: // 54 case Opcodes.LSTORE: // 55 case Opcodes.FSTORE: // 56 case Opcodes.DSTORE: // 57 case Opcodes.ASTORE: // 58 { LocalVar lv = this.vars.get(slot); String type = Util.javaSignature2irType(this.cv.getStatistics().getResolver(), lv.signature); StackValue value = stack.pop(); value = out.castP1ToP2(stack, value, type); out.comment(type + "store " + slot); out.add("store " + value.fullName() + ", " + type + "* %" + lv.name); } break; default: } } private List<String> strings = new ArrayList<String>(); public void add(String str) { strings.add(str); } public void addImm(Object value, String type, RuntimeStack stack) { String immname = "%_imm_" + tmp; add(immname + " = alloca " + type); add("store " + type + " " + floatToString(value) + ", " + type + "* " + immname); String sv = stack.push(type); add(sv + " = load " + type + ", " + type + "* " + immname); tmp++; }
循环读取指令进行转换成相应的IR,转换前后简单示例如下:
//转换前java代码: public static void main() { long a = System.currentTimeMillis(); Test test = new Test(); test.in = 9; linux.glibc.put(test.in); linux.glibc.put(System.currentTimeMillis() - a); linux.glibc.put(sl); linux.glibc.put(singleton.ln); } //转换后对应的IR define void @test_Test_main() { %stack0 = call i64 @java_lang_System_currentTimeMillis() %__tmp0 = call i8* @malloc(i32 ptrtoint (%test_Test* getelementptr (%test_Test* null, i32 1) to i32)) %stack1 = bitcast i8* %__tmp0 to %test_Test* call void @java_lang_Object__init_(%test_Test* %stack1) %__tmp0.i = getelementptr %test_Test* %stack1, i32 0, i32 0 store i32 1, i32* %__tmp0.i %__tmp1.i = getelementptr %test_Test* %stack1, i32 0, i32 1 store i32 127, i32* %__tmp1.i %__tmp2.i = getelementptr %test_Test* %stack1, i32 0, i32 2 store i32 100, i32* %__tmp2.i %__tmp3.i = getelementptr %test_Test* %stack1, i32 0, i32 3 store i32 142, i32* %__tmp3.i %__tmp4.i = getelementptr %test_Test* %stack1, i32 0, i32 4 store i64 42, i64* %__tmp4.i %__tmp5.i = getelementptr %test_Test* %stack1, i32 0, i32 5 store float 0x42F6A8F600000000, float* %__tmp5.i %__tmp6.i = getelementptr %test_Test* %stack1, i32 0, i32 6 store double 5.300000e-01, double* %__tmp6.i %stack16.i = load i32* %__tmp3.i call void @linux_glibc_put_I(i32 %stack16.i) store i32 9, i32* %__tmp3.i call void @linux_glibc_put_I(i32 9) %stack8 = call i64 @java_lang_System_currentTimeMillis() %stack10 = sub i64 %stack8, %stack0 call void @linux_glibc_put_J(i64 %stack10) %stack11.b = load i1* @test_Test_sl.b %stack11 = select i1 %stack11.b, i64 1111, i64 0 call void @linux_glibc_put_J(i64 %stack11) %stack12 = load %test_Test** @test_Test_singleton %__tmp5 = getelementptr %test_Test* %stack12, i32 0, i32 4 %stack13 = load i64* %__tmp5 call void @linux_glibc_put_J(i64 %stack13) ret void }
2.编译运行
将上面转换好的LLVM IR编译成对应的平台机器指令,如图6所示:

图6
通过IDA将编译的后的class代码反编译,已经被编译成X64平台的指令,图7所示:
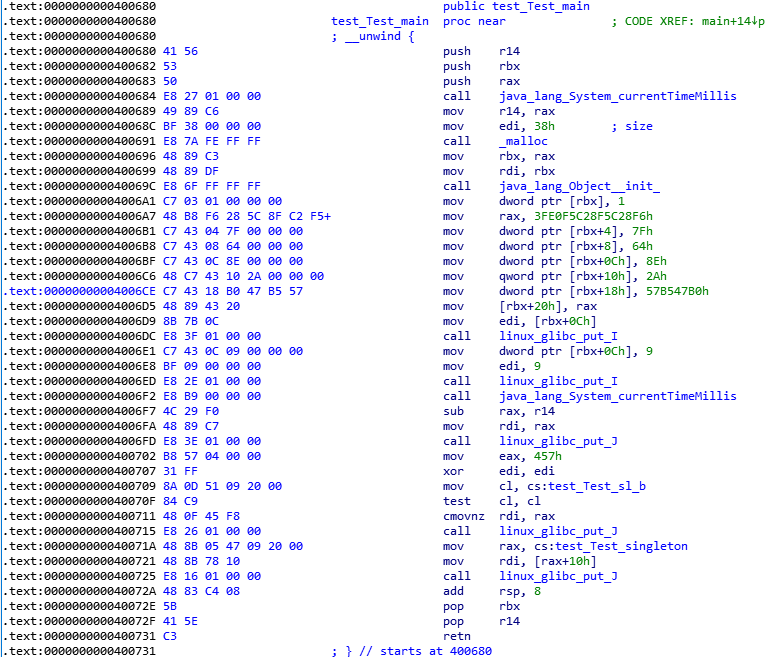
图 7
成功运行,后续还要将对外提供的方法封装在JNI接口中进行打包调用。
没有绝对的安全,只能说,这种加密方案,使逆向和破解都更难,相对于上面介绍的几种保护方案,这种方案在反调式、反Dump、抗逆向方面扩展能力会比较强,比如:指令混淆,字符串加密,VM等(关于VM可以参考文章:https://www.cnblogs.com/2014asm/p/6534897.html),没有最好的方案,只有最适合的方案。
这种方案是失去了java原来跨平台的特性,还有一点不足的地方就是对GC的支持不好,所以这也是将来须要重点更进的地方。
但是好在现在LLVM可以很好的支持不同平台的最终代码生成。
欢迎关注公众号 :

如有侵权请联系:admin#unsafe.sh