AI发展进入中场时刻:上半场专注算法与模型训练(如Transformer、GPT-3),但评估未与现实世界对齐;下半场需重新思考评估方式,让AI更大程度影响真实世界。强化学习结合推理与先验知识实现泛化,但AI对经济等实际影响有限。 2025-7-6 00:0:0 Author: arthurchiao.github.io(查看原文) 阅读量:13 收藏
Published at 2025-07-06 | Last Update 2025-07-06
本文翻译自 2025 年的一篇英文博客 The Second Half。 拆分了一些章节并增加标题,方便个人学习理解。

文章几个核心点:
-
Agent + Reasoning + prior knowledge,使得强化学习终于能泛化,一套组合拳能完成所有场景的任务, 因此专攻算法和模型变得没以前那么重要;
针对特定任务的新算法可能只能提高 5%, 而得益于预训练、强化学习和良好的泛化能力,下一代推理模型可以在不明确针对这个任务的情况下直接提高 30%。
-
模型已经在大多数任务上超越人类选手,但还并未对真实世界产生太大影响(例如,经济、GDP);
-
基于 1 & 2,认为 AI 发展进入中场时刻,需要做出方向性转变,
- 上半场:专注在算法和模型训练,但评估方式没有与现实世界对齐,因此对真实世界影响不够大;
- 下半场:应该从根本上重新考虑评估(evaluation)这个事情,让 AI 能更大程度影响真实世界,甚至通往 AGI。
水平及维护精力所限,译文不免存在错误或过时之处,如有疑问,请查阅原文。 传播知识,尊重劳动,年满十八周岁,转载请注明出处。
- 1 引言
- 2 上半场
- 3 下半场
- 原文致谢
1.2 最近几十年 AI 的发展方向
最近几十年,人工智能领域主要致力于提出新的训练方法和模型(new training methods and models)。 这个方向是成功的,例如 AI 已经能:
- 在国际象棋和围棋中击败人类世界冠军,
- 在 SAT 和律师资格考试中超越大多数人类应试者,
- 在国际数学奥林匹克竞赛(IMO)和国际信息学奥林匹克竞赛(IOI)中获得金牌。
教科书中的一系列里程碑模型(DeepBlue、AlphaGo、GPT-4、GPT-o 系列)背后, 是人工智能方法的根本性创新:
- 搜索(search)
- 深度强化学习(
deep RL) - 扩展/规模(
scaling) - 推理(
reasoning)
一切都在沿着这个方向不断进步。那么,现在为什么突然说要进入下半场了呢?
1.2 为什么说要进入下半场了?
用一句话来回答:强化学习终于奏效了(RL finally works)。
1.2.1 游戏终结者:强化学习(终于能泛化了!)
更准确地说:强化学习终于能够泛化了(RL finally generalizes)。
- 之前的一系列突破不断累积,使我们终于找到了一种统一的方式,只使用语言和推理(language and reasoning) 就能完成各种领域的强化学习任务(a wide range of RL tasks)。
- 即便在仅仅一年前,如果你跟任何 AI 研究者说,有一种统一的方式可以解决 软件工程、创意写作、数学、AI 自动使用鼠标和键盘、长篇问答等领域的任务,肯定都会得到无情的嘲笑。 这些任务每一个都极其困难,许多人在整个博士期间也只专注于其中的某个狭窄领域。然而,现在不一样了。
1.2.2 重点的转变:解决问题 -> 定义问题
人工智能的下半场,重点将从解决问题(solving problems)转移到定义问题(defining problems)。 具体来说,
- 评估将比训练更重要(evaluation becomes more important than training);
- 原来是思考 “我们能训练一个模型来解决某某问题吗”,现在更应该思考:“我们应该训练人工智能做什么?如何衡量我们的进展?”
1.2.3 思维方式和技术储备转变
要在下半场取得成功,需要及时转变思维方式和技术储备 —— 也许要更多地像产品经理那样思考。
2.1 训练方法和模型
要理解上半场,可以先看看它的赢家是谁。你认为到目前为止最有影响力的 AI 论文是什么?
我在斯坦福 224N 课程中做了调研,答案并不令人惊讶:Transformer、AlexNet、GPT-3 等等。
2.1.1 最有影响力的 AI 论文的共同点
这些论文有什么共同点?
首先,都提出了一些根本性的创新,能训练出更好的模型。
其次,还有一个不那么明显的共同点:这些“赢家”都是训练方法或模型(methods or models),而不是基准测试或任务(benchmarks or tasks)。
- 即使是最有影响力的基准测试 —— ImageNet —— 其引用量也不及 AlexNet 的三分之一。
- 在其他地方,方法与基准的对比甚至更为悬殊。例如,Transformer 的主要基准测试是 WMT’14,其引用量约为 1300,而 Transformer 的引用量则超过了 16w。

2.1.2 上半场的核心:构建新的模型和方法
这说明了上半场的游戏 专注于构建新的模型和方法,而评估和基准测试是次要的(尽管是论文系统正常运转所必要的)。
算法 vs. 任务:洞察力和工程能力
为什么呢?一个很大的原因是,在人工智能的上半场,方法/算法比任务更难、更令人兴奋。
- 从零开始设计一个新算法或模型架构 —— 例如反向传播算法、卷积网络(AlexNet)、GPT-3 中使用的 Transformer —— 需要非凡的洞察力和工程能力。
- 相比之下,为人工智能定义任务往往感觉更简单直接: 我们只是把人类已经做的事情(比如翻译、图像识别或国际象棋)变成基准测试 —— 不需要太多洞察力甚至工程能力。
算法 vs. 任务:通用性和普适性
方法(methods)也往往比单个任务(task)更具通用性和普适性,这使得它们非常有价值。
例如,Transformer 架构最终推动了计算机视觉(CV)、自然语言处理(NLP)、强化学习(RL)以及许多其他领域的进步 —— 远远超出了它最初证明自己的单一数据集(WMT’14 translation)。
一个伟大的新方法可以在许多不同的基准测试中不断改进提升,因为它简单且通用,因此其影响往往超出单个任务。
2.1.3 训练组合拳的质变时刻
这种方式已经持续了几十年,并激发了很多改变世界的思想和突破 —— 体现在各个领域不断提高的基准测试性能上。
那么,为什么说此时到了一个分水岭了呢?因为这些思想和突破的积累已经产生质变(made a qualitative difference), 能让我们用一种新方式完成不同类型的任务。
训练组合拳包括什么呢?
- massive language pre-training
- scale (in data and compute)
- reasoning and acting
这些术语大家应该已经司空见惯了。 但为什么称它们为组合拳呢?可以通过强化学习(RL)来理解一下。
2.2 强化学习(RL)
强化学习通常被认为是人工智能的“终极游戏” —— 毕竟, 从理论上讲,RL 能够完成任何任务,而且很难想象不用 RL 就能实现的超级人类系统(例如 AlphaGo)。
在 RL 中,有三个关键组成部分:
- 算法
- 环境
- 先验知识
2.2.1 传统 RL:主要关注算法
长期以来,RL 研究者主要关注算法(例如 REINFORCE、DQN、TD-learning、actor-critic、PPO、TRPO……)—— 这是 agent 学习的智力核心 —— 而将环境和先验知识视为固定或最小化的。 例如,Sutton 和 Barto 的经典教科书几乎只关注算法,而几乎不涉及环境或先验知识。

2.2.2 深度 RL:环境因素非常重要,决定算法的效果
在深度 RL 时代,从经验上说,环境很重要:算法的性能往往与其开发和测试环境高度相关。
如果忽视环境,你可能构建出来的就是一个只在 toy 设置中表现出色的“最优”算法。
2.2.3 深度 RL:OpenAI 的工程经验
也就是说,我们需要先确定我们真正想要解决的环境,然后才能找到最适合它的算法。 这正是 OpenAI 最初的计划。
- OpenAI 先是构建了 gym,一个用于各种游戏的标准 RL 环境,
- 然后是 World of Bits 和 Universe 项目,试图将互联网或计算机变成一个游戏。
一旦我们将所有数字世界变成一个环境,就能用 RL 算法解决它 —— 最终我们就拥有了通用人工智能(AGI)。
计划是好的,但并不完全奏效。OpenAI 在这条道路上取得了巨大的进展,使用 RL 解决了 Dota、robotic hands 等问题。 但它从未接近解决 computer use 或 web navigation 问题,而且在不同领域工作的 RL agents 无法相互转移学到的知识。 中间似乎缺少了什么。
直到 GPT-2 或 GPT-3 出现后,才发现缺失的部分是先验知识。
- 你需要强大的预训练,将一般常识和语言知识提炼到模型中,
- 然后可以微调以成为 web agent (WebGPT) 或 chat agent (ChatGPT) (进而改变真实世界)。
2.2.4 深度 RL:最重要的可能是先验知识(预训练到模型中)
事实证明,RL 最重要的部分可能不是 RL 算法或环境,而是先验知识, 这些可以通过与 RL 完全无关的方式获得。
预训练只对聊天场景比较有效(先验知识)
预训练为聊天场景(chatting)创造了良好的先验知识,但并不同样适用于控制计算机或玩电子游戏。
为什么呢?因为这些领域与互联网文本的分布相距较远,而简单地在这些领域进行 SFT/RL 很难泛化。
2.3 顿悟时刻:模型需要像人类一样去【思考】
我在 2019 年注意到了这个问题,当时 GPT-2 刚刚问世,我在其基础上进行了 SFT/RL,以解决基于文本的游戏 —— CALM 是世界上第一个通过预训练语言模型构建的 agent。 但该 agent 需要数百万次 RL 步骤才能学会一个游戏,而且无法转移到新游戏中。
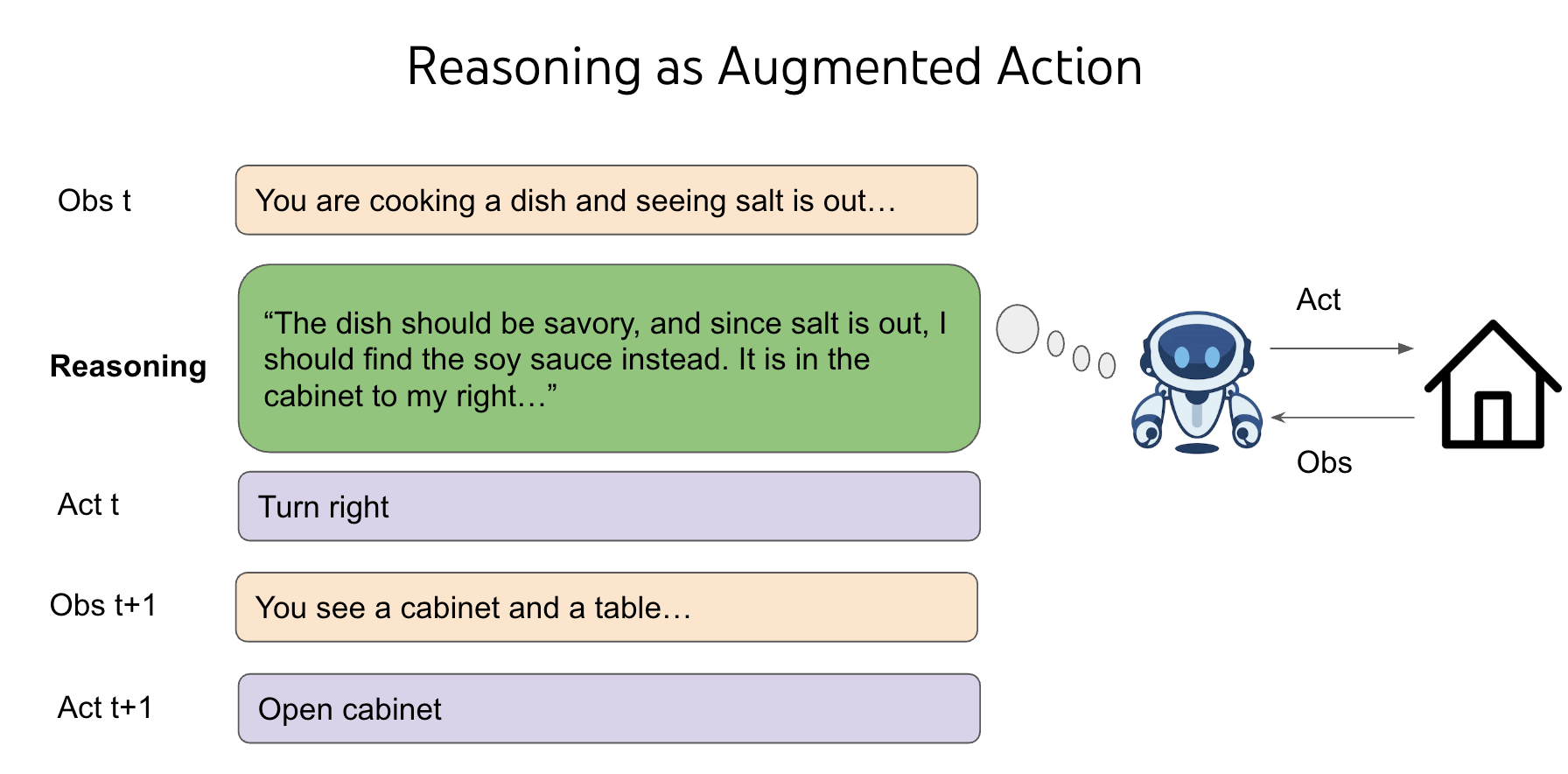
尽管这是 RL 的典型特征,RL 研究者对此并不陌生,但我发现这很奇怪,因为我们人类可以轻松地玩一个新游戏,并且在零样本的情况下表现得更好。 然后我迎来了人生中的第一个顿悟时刻 —— 我们之所以能够泛化,是因为我们不仅可以选择“走到橱柜 2”、“用钥匙 1 打开宝箱 3”或“用剑打开地牢”等动作,还可以选择思考像“地牢很危险,我需要武器来战斗。没有可见的武器,也许我需要在锁着的箱子或宝箱中找到一个。宝箱 3 在橱柜 2 里,我先去那里打开它”这样的事情。
2.4 突破:AI 思考/推理
思考,或者说推理,是一种奇怪的动作 —— 它并不直接影响外部世界, 而推理空间是开放的、无限组合的 —— 你可以去想一个词、一句话、一段文字, 或者 10000 个随机的单词,但你周围的世界并不会立即改变。
2.4.1 经典 RL:无法在开放、无限组合的推理空间做出决策
在经典 RL 理论中,这是一个糟糕的事情,因为它导致无法做出决策。 想象一下,
- 如果你要在两个盒子中选择一个,其中一个盒子里有 100 万美元,另一个是空的。那你的期望收益将是 50 万美元。
- 如果在其中增加了无数个空盒子,你的期望收益将变为零。
2.4.2 经典 RL + Reasoning + 预训练模型(先验知识):实现 RL 泛化
But by adding reasoning into the action space of any RL environment, we make use of the language pre-training priors to generalize, and we afford to have flexible test-time compute for different decisions.
但是,往任何 RL 环境的 action space 加入 reasoning 能力之后, 我们就利用预训练的先验知识来泛化, 并且可以为不同的决策提供灵活的 test-time compute。
这是一件非常神奇的事情,我为不能在这里完全解释清楚而致歉,可能需要再写一篇文章来专门来解释它。 你可以阅读我的 paper ReAct 了解最原始的 agent 推理的故事,感受一下我当时的感受。
2.4.3 “选盒子游戏”的直观 vs. 抽象解释
目前,我的直观解释是:即使增加了无数个空盒子,但你此生已经在玩过的各种游戏中都见过它们, 因此在任何给定的游戏中,你能尽量排除掉它们,仍然选出最有可能装了钱的那个盒子。
我的抽象解释是:agents 中,语言通过推理实现泛化(language generalizes through reasoning in agents)。
2.5 RL 小结:先验知识 > 环境 > 算法
一旦我们有了正确的 RL 先验知识(语言预训练)和 RL 环境(将语言推理作为动作), 事实证明 RL 算法可能就是最不重要的部分了。
因此,我们有了 GPT-o 系列、DeepSeek R1、深度研究、computer-use agent ,还会有更多出现。
真是一个讽刺的转折!长期以来,RL 研究者一直最关注算法,然后才是环境,而没有人关注过先验知识 —— 所有 RL 实验基本上都是从头开始的。 我们经过了数十年的曲折才意识到,也许优先级应该完全颠倒过来。
但正如史蒂夫·乔布斯所说:You can’t connect the dots looking forward; you can only connect them looking backward。
这个发现正在彻底改变游戏规则。
回顾上半场的游戏:
- 开发新的训练方法或模型,以在基准测试中不断提升性能;
- 创建更难的基准测试;
- 转 1,继续这个循环。
这个游戏现在玩不下去了,因为:
- 这种基准测试本质已经很标准化和工业化,不需要什么新算法就能实现性能提升 —— 你针对特定任务的新方法可能只能提高 5%, 而得益于预训练、强化学习和良好的泛化能力,下一个 o 系列模型可以在不明确针对它的情况下提高 30%。
-
即使创建更难的基准测试,很快(而且越来越快)它们也会被以上方式解决。 我的同事 Jason Wei 制作了下图,很好地可视化了这一趋势:

那么,在下半场还剩下什么呢?如果不再需要新方法,而更难的基准测试很快就会被解决,我们该怎么办?
3.1 从根本上重新思考 evaluation
我认为,我们应该从根本上重新思考评估(evaluation)。
- 这意味着不仅要创建新的、更难的基准测试,
- 还要从根本上质疑现有的评估 setups 并创建新的 setups,迫使我们发明出更有效的评估新方法。
这很难,因为人类有惯性,很少质疑基本假设 —— 你把它们当作理所当然,而没有意识到它们是假设,而不是法则。
为了说明惯性,假设你基于人类考试发明了历史上最成功的评估之一。 这是一个在 2021 年非常大胆的想法,但 3 年后它已经饱和了。 你会怎么做?最有可能的是创建一个更难的考试。 或者假设你解决了简单的编程任务。你会怎么做?最有可能的是找到更难的编程任务来解决,直到你达到了 IOI 金牌水平。
3.2 效用问题:AI 已经在大量场合超越人类,但并未对真实世界(e.g. GDP)产生太大影响
人工智能已经在国际象棋和围棋中击败了世界冠军, 在 SAT 和律师资格考试中超越了大多数人类,并在 IOI 和 IMO 中达到了金牌水平。但世界并没有因此而发生太大变化,至少从经济和 GDP 来看是这样。
我称这为效用问题,并认为这是人工智能最重要的问题。
这个问题我们也许会很快解决,也许不会。但不管怎样,这个问题的根本原因可能出人意料地简单: 我们的评估 setups 在许多基本方面与现实世界 setups 不同。
3.3 评估 setups 与现实世界 setups 不同
举两个例子。
3.3.1 例子一:评估“应该”自动运行
根据这个假设,通常 agent 接收任务输入,自主地做事情,然后接收任务奖励。
但在现实中, agent 必须在整个任务过程中与人类互动 —— 你不会给客户服务发一条超长的信息,等 10 分钟, 然后期望一个详细的回复来解决所有问题。
解决这类问题就需要提出一些新的基准测试,要么引入真人打分(例如 Chatbot Arena),要么引入用户模拟(例如 tau-bench)。

3.3.2 例子二:评估“应该”独立同分布(i.i.d.)
如果你有一个包含 500 个任务的测试集,你会独立运行每个任务,平均任务指标,然后得到一个总体指标。
但在现实中,你是顺序解决任务,而不是并行解决。
- 谷歌的软件工程师(SWE)随着对代码库的熟悉程度越来越高,解决 google 问题的能力也越来越强,
- 但 SWE agent 在同一个代码库中解决许多问题之后,却无法获得这种熟悉感。
我们显然需要长期记忆方法(已经有了),但学术界没有合适的基准测试来证明这种需求, 甚至没有勇气质疑机器学习的基础假设 —— 独立同分布。
这些假设“一直”以来都是这样,而在人工智能的上半场,在这些假设下开发基准测试是可以的, 因为当智能水平较低时,提高智能通常会提高效用(when the intelligence is low, improving intelligence generally improves utility)。
3.4 下半场游戏规则
下半场的游戏方式:
- 开发针对现实世界效用的新评估 setups 或任务;
- 用现在的训练组合拳(或引入新组件增强)去训练模型,在 1 的任务上不断提升性能;
- 转 1,继续这个循环。
3.5 小结
下半场的游戏很难,因为大家对它还比较陌生,但它令人兴奋。
- 上半场的参与者解决了电子游戏和考试,下半场的参与者可以通过开发有用的 AI 产品,建立数十亿甚至万亿美元的公司。
- 上半场是渐进式的方法和模型,下半场则不一样了, 通用训练组合拳能轻松击败渐进式方法,除非你能提出新的假设来打破组合拳,那你就是在做真正改变游戏规则的研究了。
欢迎来到下半场!
This blog post is based on my talk given at Stanford 224N and Columbia. I used OpenAI deep research to read my slides and write a draft.
![]()
![]()
如有侵权请联系:admin#unsafe.sh