2024-7-4 15:33:0 Author: addxorrol.blogspot.com(查看原文) 阅读量:3 收藏
While I have been a sceptic of using ML and AI in adversarial (security) scenarios forever, I also quite like the fact that AI/ML has become important, if only to make me feel like my Math MSc (and abortive Math PhD) were not a waste of time.
I am a big proponent of "bottom-up" mathematics: Playing with a large number of examples to inform conjectures to be dealt with later. I tend to run through many experiments to build intuition; partly because I have crippling weaknesses when operating purely formally, partly because most of my mathematics is somewhat "geometric intuition" based -- e.g. I rely a lot on my geometric intuition for understanding problems and statements.
For a couple years I've wanted to build myself a better intuition about what deep neural networks actually "do". There are folks in the community that say "we cannot understand them", and folks that say "we believe in mechanistic interpretability, and we have found the neuron to recognize dogs"; I never found either statement to be particularly convincing.
As a result, earlier this year, I finally found time to take a pen, pencil, and wastebasket and began thinking a bit about what happens when you send data through a neural network consisting of ReLU units. Why only ReLUs? Well, my conjecture is that ReLUs are as good as anything, and they are both reasonably easy to understand and actually used in practical ML applications. They are also among the "simplest examples" to work with, and I am a big fan of trying the simple examples first.
This blog post shares some of my experiments and insights; I called it the "paper plane or origami perspective to deep learning". I subsequently found out that there are a few people that have written about these concepts under the name "the polytope lens", although this seems to be a fringe notion in the wider interpretability community (which I find strange, because - unsurprisingly - I am pretty convinced this is the right way to think about NNs).
Let's get started. In order to build intuition, we're going to work with a NN that is supposed to learn a function from R^2 to R - essentially learning a grayscale image. This has several advantages:
1. We can intuitively understand what the NN is learning.
2. We can simulate training error and generalisation errors by taking very high-resolution images and training on low-resolution samples.
3. We stay within the realm of low-dimensional geometry for now, which is something most of us have an intuitive understanding of. High dimensions will create all sorts of complications soon enough.
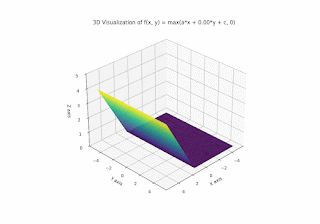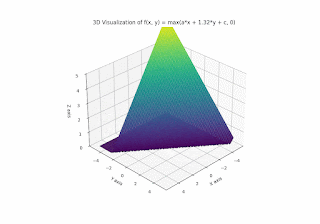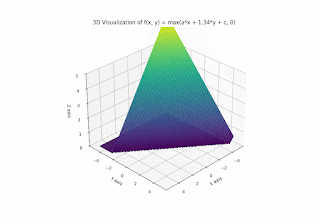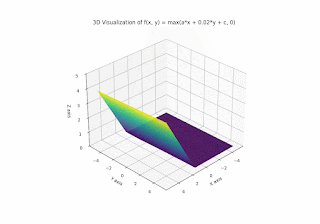
Let's begin by understanding a 2-dimensional ReLU neuron - essentially the function f(x, y) = max( ax + by + c, 0) for various values of a, b, and c.
This will look a bit like a sheet of paper with a crease in it:

How does this function change if we vary the parameters a, b, or c? Let's begin by varying a:

Now let's have a look at varying b:

And finally let's have a look at varying c:

So the parameters a, b, c really just decide "in which way" the plane should be folded / creased, and the steepness and orientation of the non-flat part. It divides the plane into halfspaces; the resulting function is 0 on one half-plane and linear (respectively affine) on the other.
As a next step, let's imagine a single-layer ReLU network that takes the (x,y) coordinates of the plane, and then feeds it into 10 different ReLU neurons, and then combines the result by summing them using individual weights.
The resulting network will have 3 parameters to learn for each neuron: a, b, and c. Each "neuron" will represent a separate copy of the plane that will then be combined (linearly, additively, with a weight) into the output function. The training process will move the "creases" in the paper around until the result approximates the desired output well.
Let's draw that process when trying to learn the picture of a circle: The original is here:

This shows us how the network tries to incrementally move the creases around so that on each of the convex areas that are created by the creases, it can choose a different affine function (with the condition that on the "creases" the functions will take on the same value).
Let's do another movie, this time with a higher number of first-layer neurons - 500. And let's see how well we will end up approximating the circle.
Aside from being mesmerizing to watch, this is also kinda intriguing and raises a bunch of questions:
- I don't understand enough about Adam as an optimizer to understand where the very visible "pulse" in the optimization process is coming from. What's going on here?
- I am pretty surprised by the fact that so many creases end up being extremely similar -- what would cause them to bundle up into groups in the way they do? The circle is completely rotation invariant, but visually the creases seem to bunch into groups much more than random distribution would suggest. Why?
- It's somewhat surprising how difficult it appears to be to learn a "sharp" edge, the edge between white and black in the above diagram is surprisingly soft. I had expected it to be easier to learn to have a narrow polytope with very large a/b constants to create a sharp edge, somehow this is difficult? Is this regularization preventing the emergence of sharp edges (by keeping weights bounded)?
Clearly, there's work to do. For now, some entertainment: Training the same 500-neuron single-layer network to learn to reproduce a picture of me with a face full of zinc sunscreen:

It's interesting (perhaps unsurprising) that the reproduced image feels visually like folded paper.
Anyhow, this was the first installment. I'll write more about this stuff as I play and understand more.
Steps I'll explain in the near future:
- What happens as you deepen your network structure?
- What happens if you train a network on categorical data and cross-entropy instead of a continuous output with MSE?
- What can we learn about generalization, overfitting, and overparametrization from these experiments?
See you soon.
如有侵权请联系:admin#unsafe.sh