2023-5-31 22:22:0 Author: www.cnblogs.com(查看原文) 阅读量:35 收藏
0x1:向量是AI理解世界的通用数据形式
1、向量是多模态高维数据的压缩
当我们见到一个熟悉的人或物的时候,大脑是这样思考的:首先,眼睛中的视杆细胞和视锥细胞记录下光的强度。这些信号传递到位于你大脑后方的视觉皮层,在皮层中数以百万计的神经元以不同的强度被激活。激活信号传输到你的颞叶,你的大脑解释为:我看到了某某。
也就是说,当我的大脑试图理解和解释看到的信息时,大脑解读的是视觉皮层输出的神经表示,而非进入眼睛的原始图像。深度学习模型也是如此。
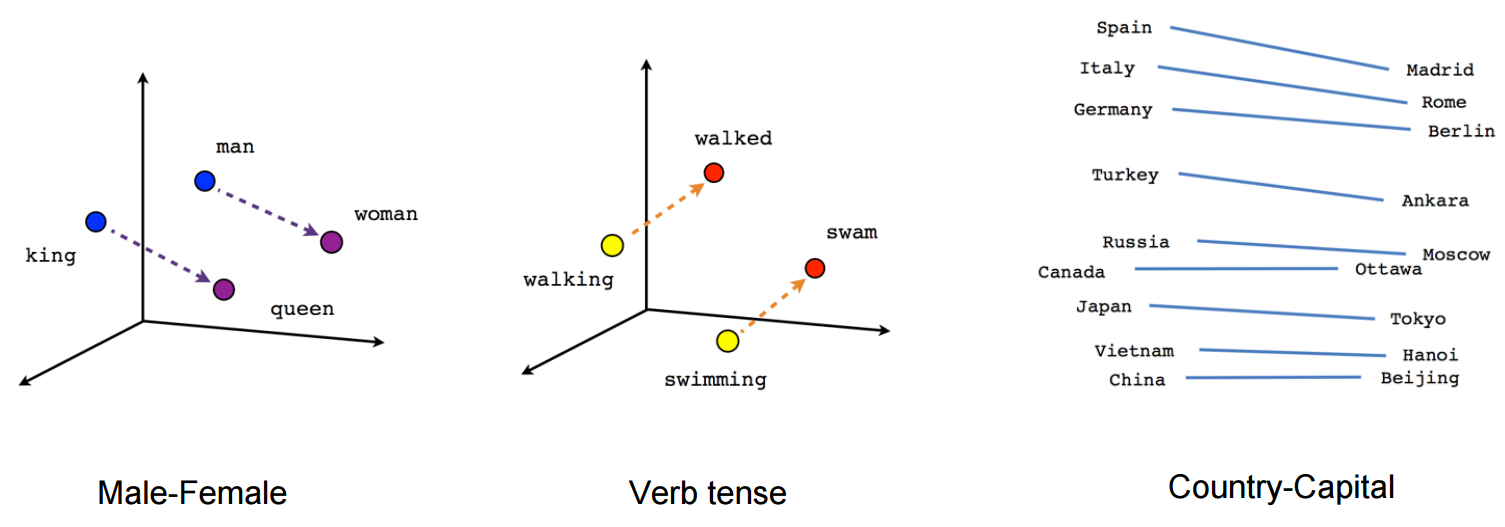
尽管大模型呈现出的形式是端到端、文本输入输出的,但实际模型接触和学习的数据并不是文本本身,而是向量化的文本,因为文本本身直接作为数据维度太高、学习起来太低效(稀疏)了。所谓向量化的文本,就是模型对自然语言的压缩和总结。早年的 NLP 教材有一个很经典的例子:如果我们把每一个单词看作向量,king 减 queen 之差与 man 与 woman 之差是相等的,都代表着性别的差异。

做一个类比,评价一个人有非常多的维度,我们见人的时候会根据自己的经验总结出一些关键维度的信息(可能有上千维),例如:
- 身高
- 体重
- BMI
- 学历
- 职业
- ....
这些关键信息就是人脑加工的 embedding。
基于这些维度,我们把”描述一个人的评价的一段文本“这个高维度信息压缩成一个向量表示。
如果面试后要对一些候选人做筛选,我们不会直接拿原始文本评价,而是通过上述各个维度去比较、排序,然后找到最合适的那个人。这个比较并给出答案的过程,就是向量搜索。
2、向量搜索是一种模糊的匹配,需求在 LLM 前已经出现
向量搜索就是在海量存储的向量中找到最符合要求的 k 个目标。
当我想从海外独角兽的文本库中找出与“硅谷最新动态”最相关的 5 段文本时,首先会使用 OpenAI Embedding api 将海外独角兽的所有文章加工成向量,存入向量数据库中;然后把“硅谷最新动态”的向量与数据库中所有向量进行语义相似度的对比;比对后,对相似度排名返回 top 5 的文本,很可能来自去年团队去硅谷的所见所闻。
理解了这个过程,我们会发现向量搜索和传统数据库的查找最大区别在于:
- 传统数据库是精确的索引,查找到的内容是有正确答案的。也就是说,数据库中的数据只有两类,一类是符合查询要求、返回给用户的数据,另一类就是不符合要求。
- 向量搜索则是模糊的匹配,找到的是相对最符合需求的数据,并没有精确的标准答案。
将这个过程和互联网业务联系起来,会发现向量搜索是一个已经存在的需求。互联网中的搜索、推荐业务,安保系统的人脸识别、对比,都有很多使用场景。在这些场景下,系统需要根据多个维度进行数据关联计算,因为实际业务场景中数据量非常大,很容易形成类似“笛卡尔积”的海量计算问题,即使减少维度数量,进行循环遍历,来获取某几个向量的相似度计算,在海量数据的场景下也是不现实的。
因此之前向量搜索算法就已经出现,Facebook 开源的 FAISS 是其中的翘楚,只是在大模型出现之前,这个需求只在大厂中存在,主要通过自研产品满足。
3、向量数据库是 LLM 下游的新数据库产品
向量数据库是一种高效存储和搜索向量的数据库产品,传统数据库无法很好的满足这一需求。传统数据库只能部分满足向量数据的存储,而且在搜索上技术有明显差异。
- 在存储上,向量数据规模超过传统的关系型数据库,传统的关系型数据库管理 1 亿条数据已经不算小的量级。而在向量数据库需求中,一张表千亿数据是底线,并且原始的向量通常比较大,例如 512 个 float = 2k,千亿数据需要保存的向量就需要 200T 的存储空间。因此对向量数据的存储需求量是很大的,如果不做数据库只做向量搜索算法,很大一部分需求还需要用户自己研发。
- 查询方式的差异更大。前面提到,传统的数据库查询通常是点查和范围查,都是一种精确查找,即查询得到的结果只有符合条件和不符合条件。而向量数据库的向量查询往往是近似查找,即查找与查询条件相近的结果,即查询得到的结果是与输入条件最相似的。近似的查找对算力要求更高。
在大模型场景下,向量搜索的需求真正开始爆发式增长:
如果有大量信息或语料需要给 LLM 作为参考,把大量文本一股脑的作为 Prompt 显然很不经济,而且过多不相干信息还可能误导模型输出。因此一个好的方式是,提前把语料库向量化,再查询跟问题 embedding 相似的语料,最终一同送入 GPT 模型。这是一种典型地整合 OpenAI api 的路径,是现阶段比较灵活且经济的方式。向量搜索在这里扮演了择优选择 prompt 的角色。
进一步从动态的视角来看,当多模态大模型技术成熟之后,整个技术路线会分化为两条道路:
- LLM模型推理性能和速度会越来越快,基于prompt、few-shot等技术,面向开放式任务进行文本生成
- Embedding向量数据库越来越大,随着模型推理速度会加快,向量数据的复杂度提升,检索速度会变慢,届时向量搜索的性能是产品可用性至关重要的因素。而且向量数据库在多模态领域会有更显著的检索能力,毕竟人类和传统数据库对多媒体数据的检索能力是很弱的。多媒体数据也能大幅增加其存储量和迁移成本,使其成为更加刚性的需求。
MongoDB 的重要性一部分来自于 JSON 的灵活性,其覆盖多个场景,使用单个数据库完成了多种数据库的任务。而向量 embedding 也有这一潜质,文本、图片、音频、视频等多媒体数据,未来都可以用通用大模型压缩成向量化的数据。
因此如果我们认为AI 应用 = LLM + 交互 + 记忆 + 多模态,
- 在前两者的实现中,预训练数据质量、丰富度、prompt-tune对齐将扮演重要角色
- 在后二者的实现中,向量数据库都将扮演非常重要的角色。
当 AI 能有这么强的信息提取和组织能力之后,传统数据库的很多能力是受到冲击的。
向量搜索的普及过程中,很多之前用 SQL 和结构化数据比较难解锁的产品功能自然得到了实现,长期用户的使用范式肯定慢慢会从传统数据库转移到 LLM + Vector DB。
下图展示了向量数据库是如何提升AI Applications的能力的,


- Indexing(知识向量化):使用向量模型(embedding model)对输入内容进行向量化表示(vector embedding)。
- Indexing Storage(向量化存储):将生成的向量化表示存入向量数据库,并保存和原始内容的关联键。循环进行第一和第二步,将高质量的知识库进行向量化表示后,存入向量数据库中
- ......
- Post Processing(query后处理):当应用进行query查询的时候,我们使用相同的向量模型(embedding model)创建query的向量化表示,然后使用某种相似度搜索算法,在向量数据库中寻找top k个和该query的向量化表示相似的向量(vector embedding),并通过关联键得到与之对应的原始内容,这些原始内容就是向量数据库的搜索结果(query result)。
- 这些搜索结果可以用于应用后续的query中,例如用于强化prompt的精确度(辅助生成更精准和描述丰富的问题)
- 也可以直接作为知识库搜索的结果直接返回给终端用户(类似知识搜索的场景)。
0x2:向量是AI形成长期记忆(long-term memory)的基础
LLM大模型相当于是记忆缺失的大脑,而向量数据库是补足这一能力的海马体。其实调用向量数据库进行相似性搜索的过程,比较像人类死记硬背使用短期记忆的方式。因为当我们进入某一领域时,会首先根据一些知识与过来人的经验依葫芦画瓢,然后随着自己的试错和经验积累慢慢形成自己的直觉、风格和行为习惯,直到那时我们才成为这一领域的专家。而向量化数据库,只实现了依葫芦画瓢的那一步。
换言之,从人类智能的角度看,向量数据库是短期记忆,LLM 是长期记忆,但目前他们之间的交互还是单向的,缺少了短期记忆累积沉淀,形成长期记忆的过程。但直接去调整大模型的参数是不太可行的。因此这一过程可能需要一些新的组件来弥补,例如一个基于 Lora 进行微调的小模型,来帮助大模型做一些领域专业知识的记忆;也或者是由多个 LLM 交互形成群体记忆,来达到更新长期记忆的效果。
无论是哪一种方式,都有可能对向量数据库产生依赖或替代的关系,甚至有可能向量数据库会根据客户需求提供这样的能力。因此未来的架构变化对向量数据库的重要性至关重要。
同时,还有一种观点认为,当 LLM 能够读入无限 token 时,向量数据库的必要性就不大了。理论上这是完全可行的,但这忽略了经济成本和工程复用性的问题。当每一次执行都要将相关语料库不经检索地作为 prompt 输入时,其中大部分的内容信息增益和 ROI 是很低的,可能带来很多不必要的商业成本和资源浪费。尤其是当大模型允许多模态输入之后,这一问题会更加显著。而且模型使用向量化的记忆,再将输出向量化存入记忆中是很好的记忆回路,能够一定程度上 LLM 对过往经验知识的总结和复用。
参考链接:
https://www.infoq.cn/article/j3vvye0uhlfdpnc8uyrs https://36kr.com/p/2233027665457281 https://www.pinecone.io/learn/vector-database/ https://www.pinecone.io/
0x1:langchain的应用场景简介
- LLMs and Prompts:This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs.
- Chains:Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications.
- Data Augmented Generation:Data Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include summarization of long pieces of text and question/answering over specific data sources.
- Agents:Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents.
- Memory:Memory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
- Evaluation:Generative models are notoriously hard to evaluate with traditional metrics. One new way of evaluating them is using language models themselves to do the evaluation. LangChain provides some prompts/chains for assisting in this.
0x2:安装向量数据库chromadb和tiktoken
pip install chromadb
pip install pybind11
pip install tiktoken
pip install unstructured
pip install pdf2image
pip install pytesseract
0x3:embeddings持久化语料库

import os from langchain.embeddings import HuggingFaceEmbeddings from langchain.vectorstores import Chroma from langchain.text_splitter import CharacterTextSplitter from langchain import OpenAI, VectorDBQA from langchain.document_loaders import DirectoryLoader from langchain.chains import RetrievalQA # 加载文件夹中的所有.neat文件 loader = DirectoryLoader('./webshell_data_0414', glob='**/*.neat') # 将数据转成 document 对象,每个文件会作为一个 document documents = loader.load() # 初始化加载器 text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0) # 切割加载的 document split_docs = text_splitter.split_documents(documents) # 初始化 embeddings 对象 embedding = HuggingFaceInstructEmbeddings() # 将 document 通过 embeddings 对象计算 embedding 向量信息并存入 Chroma 向量数据库,用于后续匹配查询 vector_store_path = r"./vector_store" docsearch = Chroma(persist_directory=vector_store_path, embedding_function=embeddings)
参考链接:
https://zhuanlan.zhihu.com/p/622017658?utm_id=0&wd=&eqid=d858064200101da3000000036464a33d https://www.jianshu.com/p/f26c7191944d https://zhuanlan.zhihu.com/p/621769313 https://python.langchain.com/en/latest/getting_started/getting_started.html https://python.langchain.com/en/latest/ https://github.com/hwchase17/langchain https://python.langchain.com/en/latest/getting_started/tutorials.html https://blog.csdn.net/weixin_42486623/article/details/122018308 https://zhuanlan.zhihu.com/p/622017658?utm_id=0 https://blog.csdn.net/wenxingchen/article/details/130475288 https://blog.csdn.net/DreamsArchitects/article/details/130773923 https://blog.csdn.net/wenxingchen/article/details/130475288
0x1:Installation
pip install InstructorEmbedding
pip install sentence_transformers
0x2:Compute your customized embeddings
Then you can use the model like this to calculate domain-specific and task-aware embeddings:
from InstructorEmbedding import INSTRUCTOR model = INSTRUCTOR('hkunlp/instructor-large') sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments" instruction = "Represent the Science title:" embeddings = model.encode([[instruction,sentence]]) print(embeddings)

0x3:Calculate Sentence similarities
You can further use the model to compute similarities between two groups of sentences, with customized embeddings.
from sklearn.metrics.pairwise import cosine_similarity from InstructorEmbedding import INSTRUCTOR model = INSTRUCTOR('hkunlp/instructor-large') sentences_a = [ [ 'Represent the Science sentence: ', 'Parton energy loss in QCD matter' ], [ 'Represent the Financial statement: ', 'The Federal Reserve on Wednesday raised its benchmark interest rate.' ] ] sentences_b = [ [ 'Represent the Science sentence: ', 'The Chiral Phase Transition in Dissipative Dynamics' ], [ 'Represent the Financial statement: ', 'The funds rose less than 0.5 per cent on Friday' ] ] embeddings_a = model.encode(sentences_a) embeddings_b = model.encode(sentences_b) similarities = cosine_similarity(embeddings_a,embeddings_b) print(similarities)

0x4:Information Retrieval
You can also use customized embeddings for information retrieval.
import numpy as np from sklearn.metrics.pairwise import cosine_similarity from InstructorEmbedding import INSTRUCTOR model = INSTRUCTOR('hkunlp/instructor-large') query = [ [ 'Represent the Wikipedia question for retrieving supporting documents: ', 'where is the food stored in a yam plant' ] ] corpus = [ [ 'Represent the Wikipedia document for retrieval: ', 'Capitalism has been dominant in the Western world since the end of feudalism, but most feel[who?] that the term "mixed economies" more precisely describes most contemporary economies, due to their containing both private-owned and state-owned enterprises. In capitalism, prices determine the demand-supply scale. For example, higher demand for certain goods and services lead to higher prices and lower demand for certain goods lead to lower prices.' ], [ 'Represent the Wikipedia document for retrieval: ', "The disparate impact theory is especially controversial under the Fair Housing Act because the Act regulates many activities relating to housing, insurance, and mortgage loans—and some scholars have argued that the theory's use under the Fair Housing Act, combined with extensions of the Community Reinvestment Act, contributed to rise of sub-prime lending and the crash of the U.S. housing market and ensuing global economic recession" ], [ 'Represent the Wikipedia document for retrieval: ', 'Disparate impact in United States labor law refers to practices in employment, housing, and other areas that adversely affect one group of people of a protected characteristic more than another, even though rules applied by employers or landlords are formally neutral. Although the protected classes vary by statute, most federal civil rights laws protect based on race, color, religion, national origin, and sex as protected traits, and some laws include disability status and other traits as well.' ] ] query_embeddings = model.encode(query) corpus_embeddings = model.encode(corpus) similarities = cosine_similarity(query_embeddings, corpus_embeddings) print("similarities: ", similarities) retrieved_doc_id = np.argmax(similarities) print("retrieved_doc_id: ", retrieved_doc_id) print("corpus[retrieved_doc_id]: ", corpus[retrieved_doc_id])

可以看到,通过embedding similar search,我们在corpus中搜索得到了和query最接近的语料,在prompt Retrieval场景中可以用于提高prompt的精确度和上下文信息丰富度。
0x5:Clustering
Use customized embeddings for clustering texts in groups.
from InstructorEmbedding import INSTRUCTOR model = INSTRUCTOR('hkunlp/instructor-large') import sklearn.cluster sentences = [['Represent the Medicine sentence for clustering: ','Dynamical Scalar Degree of Freedom in Horava-Lifshitz Gravity'], ['Represent the Medicine sentence for clustering: ','Comparison of Atmospheric Neutrino Flux Calculations at Low Energies'], ['Represent the Medicine sentence for clustering: ','Fermion Bags in the Massive Gross-Neveu Model'], ['Represent the Medicine sentence for clustering: ',"QCD corrections to Associated t-tbar-H production at the Tevatron"], ['Represent the Medicine sentence for clustering: ','A New Analysis of the R Measurements: Resonance Parameters of the Higher, Vector States of Charmonium']] embeddings = model.encode(sentences) clustering_model = sklearn.cluster.MiniBatchKMeans(n_clusters=2) clustering_model.fit(embeddings) cluster_assignment = clustering_model.labels_ print(cluster_assignment)

参考链接:
https://huggingface.co/hkunlp/instructor-large
# 持久化数据 docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name) # 加载数据 docsearch = Pinecone.from_existing_index(index_name, embeddings)
参考链接:
如有侵权请联系:admin#unsafe.sh