Loading...


Cloudflare’s website, application security and performance products handle upwards of 46 million HTTP requests per second, every second. These products were originally built as a set of native Linux services, but we’re increasingly building parts of the system using our Cloudflare Workers developer platform to make these products faster, more robust, and easier to develop. This blog post digs into how and why we’re doing this.
System architecture
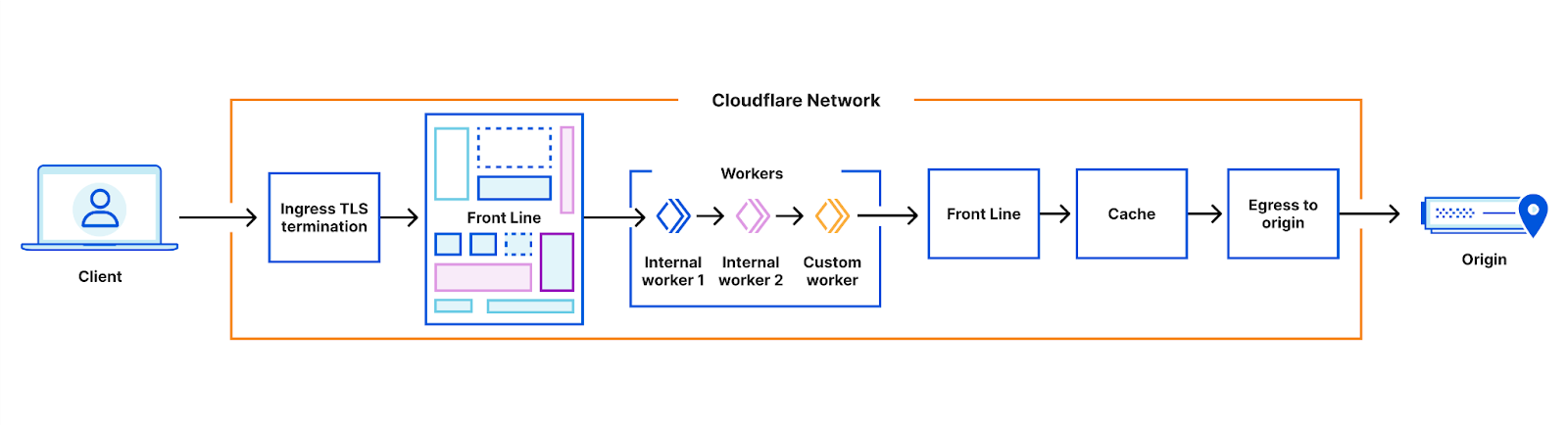
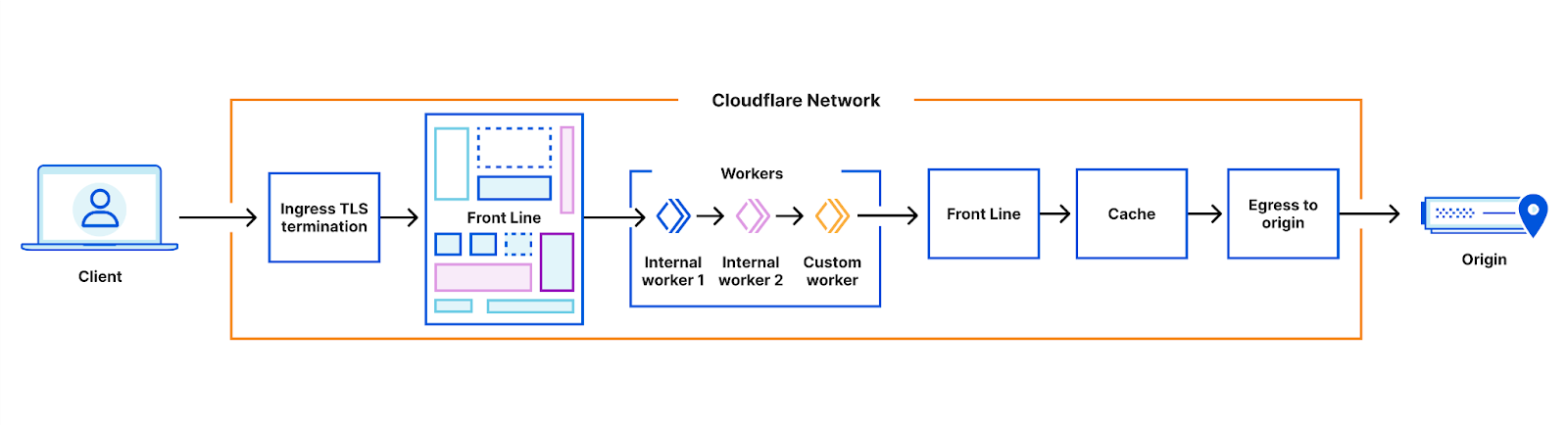
Our architecture can best be thought of as a chain of proxies, each communicating over HTTP. At first, these proxies were all implemented based on NGINX and Lua, but in recent years many of them have been replaced - often by new services built in Rust, such as Pingora.
The proxies each have distinct purposes - some obvious, some less so. One which we’ll be discussing in more detail is the FL service, which performs “Front Line” processing of requests, applying customer configuration to decide how to handle and route the request.
This architecture has worked well for more than a decade. It allows parts of the system to be developed and deployed independently, parts of the system to be scaled independently, and traffic to be routed to different nodes in our systems according to load, or to ensure efficient cache utilization.
So, why change it?
At the level of latency we care about, service boundaries aren’t cheap, particularly when communicating over HTTP. Each step in the chain adds latency due to communication overheads, so we can’t add more services as we develop new products. And we have a lot of products, with many more on the way.
To avoid this overhead, we put most of the logic for many different products into FL. We’ve developed a simple modular architecture in this service, allowing teams to make and deploy changes with some level of isolation. This has become a very complex service which takes a constant effort by a team of skilled engineers to maintain and operate.
Even with this effort, the developer experience for Cloudflare engineers has often been much harder than we would like. We need to be able to start working on implementing any change quickly, but even getting a version of the system running in a local development environment is hard, requiring installation of custom tooling and Linux kernels.
The structure of the code limits the ease of making changes. While some changes are easy to make, other things run into surprising limits due to the underlying platform. For example, it is not possible to perform I/O in many parts of the code which handle HTTP response processing, leading to complex workarounds to preload resources in case they are needed.
Deploying updates to the software is high risk, so is done slowly and with care. Massive improvements have been made in the past years to our processes here, but it’s not uncommon to have to wait a week to see changes reach production, and changes tend to be deployed in large batches, making it hard to isolate the effect of each change in a release.
Finally, the code has a modular structure, but once in production there is limited isolation and sandboxing, so tracing potential side effects is hard, and debugging often requires knowledge of the whole system, which takes years of experience to obtain.
Developer platform to the rescue
As soon as Cloudflare workers became part of our stack in 2017, we started looking at ways to use them to improve our ability to build new products. Now, in 2023, many of our products are built in part using workers and the wider developer platform; for example, read this post from the Waiting Room team about how they use Workers and Durable Objects, or this post about our cache purge system doing the same. Products like Cloudflare Zero Trust, R2, KV, Turnstile, Queues, and Exposed credentials check are built using Workers at large scale, handling every request processed by the products. We also use Workers for many of our pieces of internal tooling, from dashboards to building chatbots.
While we can and do spend time improving the tooling and architecture of all our systems, the developer platform is focussed all the time on making developers productive, and being as easy to use as possible. Many of the other posts this week on this blog talk about our work here. On the developer platform, any customer can get something running in minutes, and build and deploy full complex systems within days.
We have been working to give developers working on internal Cloudflare products the same benefits.
Customer workers vs internal workers
At this point, we need to talk about two different types of worker.
The first type is created when a customer writes a Cloudflare Worker. The code is deployed to our network, and will run whenever a request to the customer’s site matches the worker’s route. Many Cloudflare engineering teams use workers just like this to build parts of our product - for example, we wrote about our Coreless Purge system for Cache recently. In these cases, our engineering teams are using exactly the same process and tooling as any Cloudflare customer would use.
However, we also have another type of worker, which can only be deployed by Cloudflare. These are not associated with a single customer. Instead, they are run for all customers for which a particular product or other piece of logic needs to be performed.
For the rest of this post, we’re only going to be talking about these internal workers. The underlying tech is the same - the difference to remember is that these workers run in response to requests from many Cloudflare customers rather than one.
Initial integration of internal workers
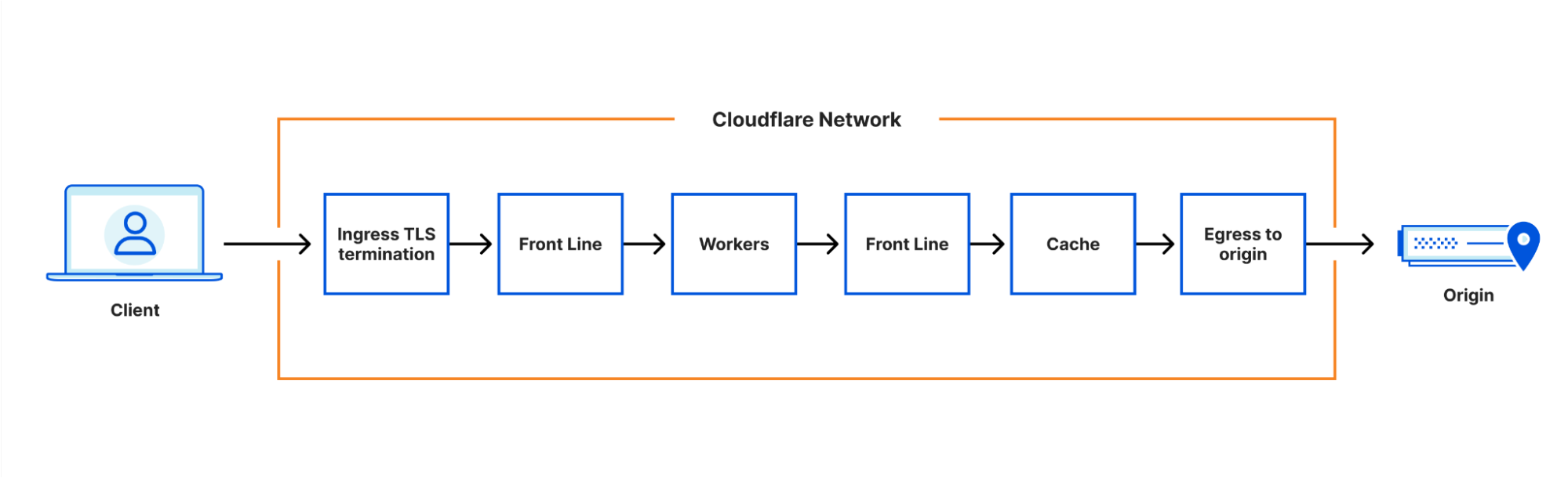
We first integrated internal workers into our architecture in 2019, in a very simple way. An ordered chain of internal workers was created, which run before any customer scripts.
I previously said that adding more steps in our chain would cause excessive latency. So why isn’t this a problem for internal workers?
The answer is that these internal workers run within the same service as each other, and as customer workers which are operating on the request. So, there’s no need to marshal the request into HTTP to pass it on to the next step in the chain; the runtime just needs to pass a memory reference around, and perform a lightweight shift of control. There is still a cost of adding more steps - but the cost per step is much lower.
The integration gave us several benefits immediately. We were able to take advantage of the strong sandbox model for workers, removing any risk of unexpected side effects between customers or requests. It also allowed isolated deployments - teams could deploy their updates on their own schedule, without waiting for or disrupting other teams.
However, it also had a number of limitations. Internal workers could only run in one place in the lifetime of a request. This meant they couldn’t affect services running before them, such as the Cloudflare WAF.
Also, for security reasons, internal workers were published with an internal API using special credentials, rather than the public workers API. In 2019, this was no big deal, but since then there has been a ton of work to improve tooling such as wrangler, and build the developer platform. All of this tooling was unavailable for internal workers.
We had very limited observability of internal workers, lacking metrics and detailed logs, making them hard to debug.
Despite these limitations, the benefits of being able to use the workers ecosystem were big enough that ten products used these internal workers to implement parts of their logic. These included Zaraz, our Cloudflare challenges system, Waiting Room and several of our performance optimization products: Image Resizing, Images, Mirage and Rocket Loader. Such workers are also a core part of Automatic Platform Optimization for WordPress, and our Signed exchanges (SXGs) and AMP Real URL products.
Can we replace internal services with workers?
We realized that we could do a lot more with the platform to improve our development processes. We also wondered how far it would be possible to go with the platform. Would it be possible to migrate all the logic implemented in the NGINX-based FL service to the developer platform? And if not, why not?
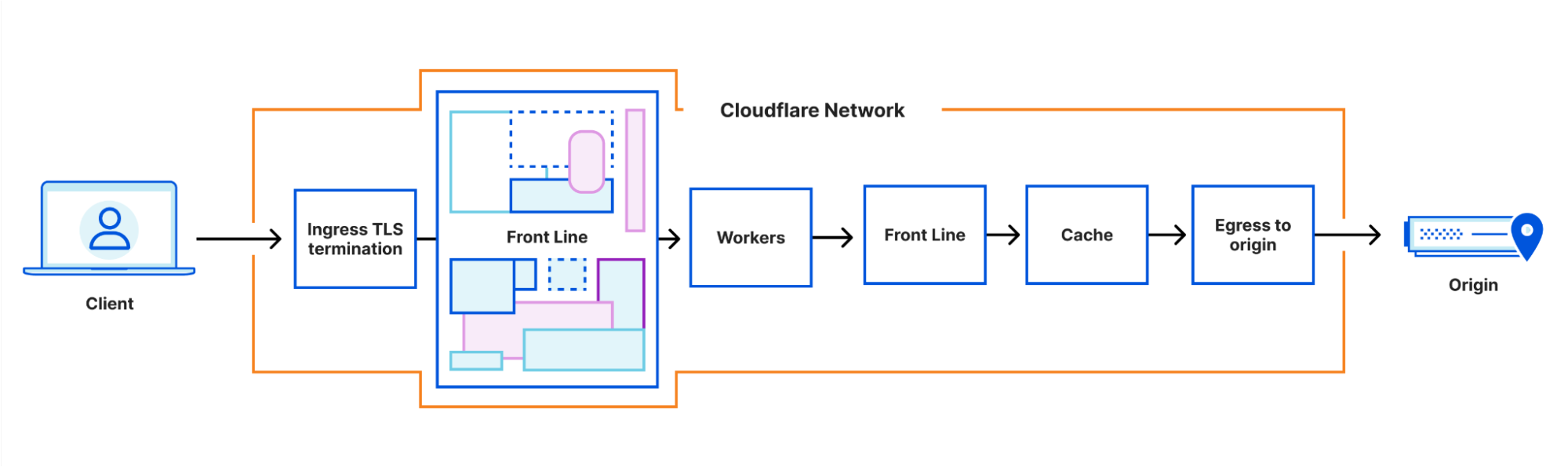
So we started, in late 2021, with a prototype. This routed traffic directly from our TLS ingress service to our workers runtime, skipping the FL service. We named this prototype Flame.
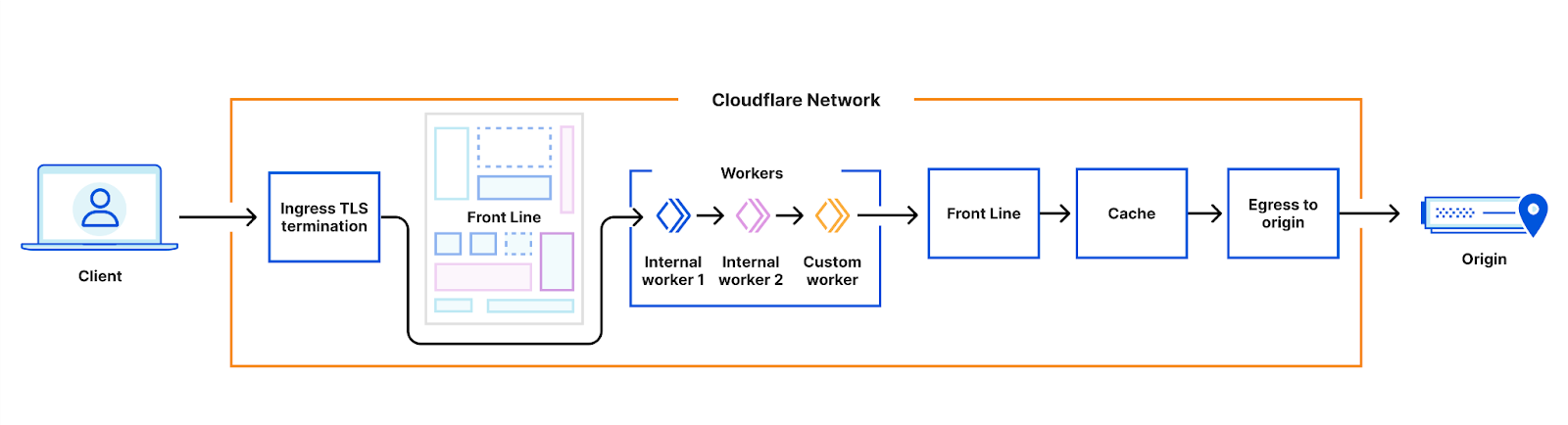
It worked. Just about. Most importantly for a prototype, we could see that we were missing some fundamental capabilities. We couldn’t access other Cloudflare internal services, such as our DNS infrastructure or our customer configuration database, and we couldn’t emit request logs to our data pipeline, for analytics and billing purposes.
We rely heavily on caching for performance, and there was no way to cache state between requests. We also couldn’t emit HTTP requests directly to customer origins, or to our cache, without using our full existing chain-of-proxies pipeline.
Also, the developer experience for this prototype was very poor. We couldn’t take advantage of all the developer experience work being put into wrangler, due to the need to use special APIs to deploy internal workers. We couldn’t record metrics and traces to our standard observability tooling systems, so we were blind to the behavior of the system in production. And we had no way to perform a controlled and gradual deployment of updated code.
Improving the developer platform for internal services
We set out to address these problems one by one. Wherever possible, we wanted to use the same tooling for internal purposes as we provide to customers. This not only reduces the amount of tooling we need to support, but also means that we understand the problems our customers face better, and can improve their experience as well as ours.
Tooling and routing
We started with the basics - how can we deploy code for internal services to the developer platform.
I mentioned earlier that we used special internal APIs for deploying our internal workers, for “security reasons”. We reviewed this with our security team, and found that we had good protections on our API to identify who was publishing a worker. The main thing we needed to add was a secure registry of accounts which were allowed to use privileged resources. Initially we did this by hard-coding a set of permissions into our API service - later this was replaced by a more flexible permissions control plane.
Even more importantly, there is a strong distinction between publishing a worker and deploying a worker.
Publishing is the process of pushing the worker to our configuration store, so that the code to be run can be loaded when it is needed. Internally, each worker version which is published creates a new artifact in our store.
The Workers runtime uses a capability-based security model. When it is published, each script is bundled together with a list of bindings, representing the capabilities that the script has to access other resources. This mechanism is a key part of providing safety - in order to be able to access resources, the script must have been published by an account with the permissions to provide the capabilities. The secure management of bindings to internal resources is a key part of our ability to use the developer platform for internal systems.
Deploying is the process of hooking up the worker to be triggered when a request comes in. For a customer worker, deployment means attaching the worker to a route. For our internal workers, deployment means updating a global configuration store with the details of the specific artifact to run.
After some work, we were finally able to use wrangler to build and publish internal services. But there was a problem! In order to deploy an internal worker, we needed to know the identifier for the artifact which was published. Fortunately, this was a simple change: we updated wrangler to output debug information which contained this information.
A big benefit of using wrangler is that we could make tools like “wrangler test” and “wrangler dev” work. An engineer can check out the code, and get going developing their feature with well-supported tooling, and within a realistic environment.
Event logging
We run a comprehensive data pipeline, providing streams of data for our customers to allow them to see what is happening on their sites, for our operations teams to understand how our system is behaving in production, and for us to provide services like DoS protection and accurate billing.
This pipeline starts from our network as messages in Cap’n Proto format. So we needed to build a new way to push pieces of log data to our internal pipeline, from inside a worker. The pipeline starts with a service called “logfwdr”, so we added a new binding which allowed us to push an arbitrary log message to the logfwdr service. This work was later a foundation of the Workers Analytics Engine bindings, which allow customers to use the same structured logging capabilities.
Observability
Observability is the ability to see how code is behaving. If you don’t have good observability tooling, you spend most of your time guessing. It’s inefficient and frankly unsafe to operate such a system.
At Cloudflare, we have very many systems for observability, but three of the most important are:
- Unstructured logs (“syslogs”). These are ingested to systems such as Kibana, which allow searching and visualizing the logs.
- Metrics. Also emitted from all our systems, these are a set of numbers representing things like “CPU usage” or “requests handled”, and are ingested to a massive Prometheus system. These are used for understanding the overall behavior of our systems, and for alerting us when unexpected or undesirable changes happen.
- Traces. We use systems based around Open Telemetry to record detailed traces of the interactions of the components of our system. This lets us understand which information is being passed between each service, and the time being spent in each service.
Initial support for syslogs, metrics and traces for internal workers was built by our observability team, who provided a set of endpoints to which workers could push information. We wrapped this in a simple library, called “flame-common”, so that emitting observability events could be done without needing to think about the mechanics behind it.
Our initial wrapper looked something like this:
import { ObservabilityContext } from "flame-common";
export default {
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext
): Promise<Response> {
const obs = new ObservabilityContext(request, env, ctx);
// Logging to syslog and kibana
obs.logInfo("some information")
obs.logError("an error occurred")
// Metrics to Prometheus
obs.counter("rps", "how many requests per second my service is doing")?.inc();
// Tracing
obs.startSpan("my code");
obs.addAttribute("key", 42);
},
};
An awkward part of this API was the need to pass the “ObservabilityContext” around to be able to emit events. Resolving this was one of the reasons that we recently added support for AsyncLocalStorage to the Workers runtime.
While our current observability system works, the internal implementation isn’t as efficient as we would like. So, we’re also working on adding native support for emitting events, metrics and traces from the Workers runtime. As we did with the Workers Analytics Engine, we want to find a way to do this which can be hooked up to our internal systems, but which can also be used by customers to add better observability to their workers.
Accessing internal resources
One of our most important internal services is our configuration store, Quicksilver. To be able to move more logic into the developer platform, we need to be able to access this configuration store from inside internal workers. We also need to be able to access a number of other internal services - such as our DNS system, and our DoS protection systems.
Our systems use Cap’n Proto in many places as a serialization and communication mechanism, so it was natural to add support for Cap’n Proto RPC to our Workers runtime. The systems which we need to talk to are mostly implemented in Go or Rust, which have good client support for this protocol.
We therefore added support for making connections to internal services over Cap’n Proto RPC to our Workers runtime. Each service will listen for connections from the runtime, and publish a schema to be used to communicate with it. The Workers runtime manages the conversion of data from JavaScript to Cap’n Proto, according to a schema which is bundled together with the worker at publication time. This makes the code for talking to an internal service, in this case our DNS service being used to identify the account owning a particular hostname, as simple as:
let ownershipInterface = env.RRDNS.getCapability();
let query = {
request: {
queryName: url.hostname,
connectViaAddr: control_header.connect_via_addr,
},
};
let response = await ownershipInterface.lookupOwnership(query);
Caching
Computers run on cache, and our services are no exception. Looking at the previous example, if we have 10,000 requests coming in quick succession for the same hostname, we don’t want to look up the hostname in our DNS system for each one. We want to cache the lookups.
At first sight, this is incompatible with the design of workers, where we give no guarantees of state being preserved between requests. However, we have added a new internal binding to provide a “volatile in-memory cache”. Wherever it is possible to efficiently share this cache between workers, we will do so.
The following flowchart describes the semantics of this cache.
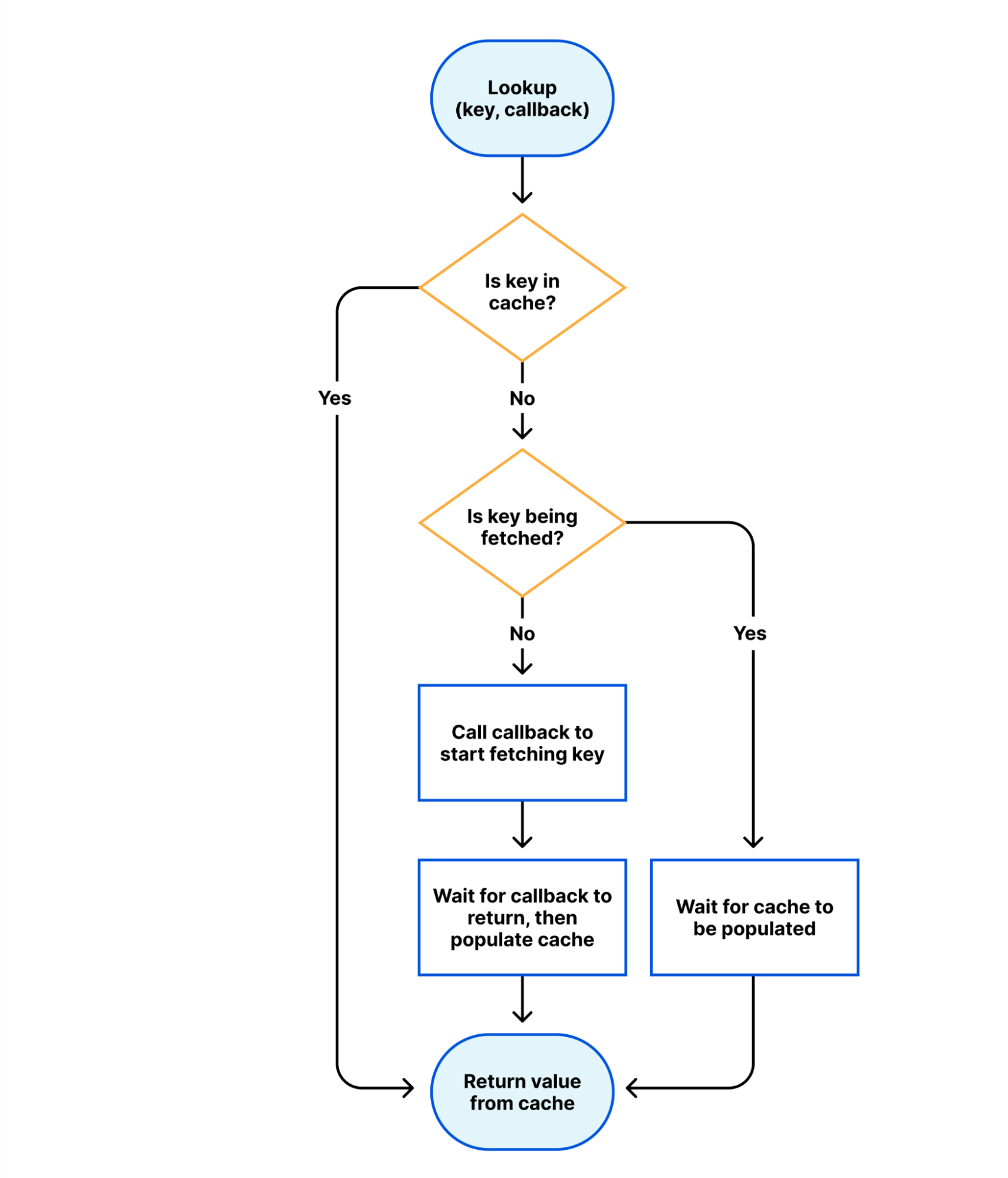
To use the cache, we simply need to wrap a block of code in a call to the cache:
const owner = await env.OWNERSHIPCACHE.read<OwnershipData>(
key,
async (key) => {
let ownershipInterface = env.RRDNS.getCapability();
let query = {
request: {
queryName: url.hostname,
connectViaAddr: control_header.connect_via_addr,
},
};
let response = await ownershipInterface.lookupOwnership(query);
const value = response.response;
const expiration = new Date(Date.now() + 30_000);
return { value, expiration };
}
);
This cache drastically reduces the number of calls needed to fetch external resources. We are likely to improve it further, by adding support for refreshing in the background to reduce P99 latency, and improving observability of its usage and hit rates.
Direct egress from workers
If you looked at the architecture diagrams above closely, you might have noticed that the next step after the Workers runtime is always FL. Historically, the runtime only communicated with the FL service - allowing some product logic which was implemented in FL to be performed after workers had processed the requests.
However, in many cases this added unnecessary overhead; no logic actually needs to be performed in this step. So, we’ve added the ability for our internal workers to control how egress of requests works. In some cases, egress will go directly to our cache systems. In others, it will go directly to the Internet.
Gradual deployment
As mentioned before, one of the critical requirements is that we can deploy changes to our code in a gradual and controlled manner. In the rare event that something goes wrong, we need to make sure that it is detected as soon as possible, rather than triggering an issue across our entire network.
Teams using internal workers have built a number of different systems to address this issue, but they are all somewhat hard to use, with manual steps involving copying identifiers around, and triggering advancement at the right times. Manual effort like this is inefficient - we want developers to be thinking at a higher level of abstraction, not worrying about copying and pasting version numbers between systems.
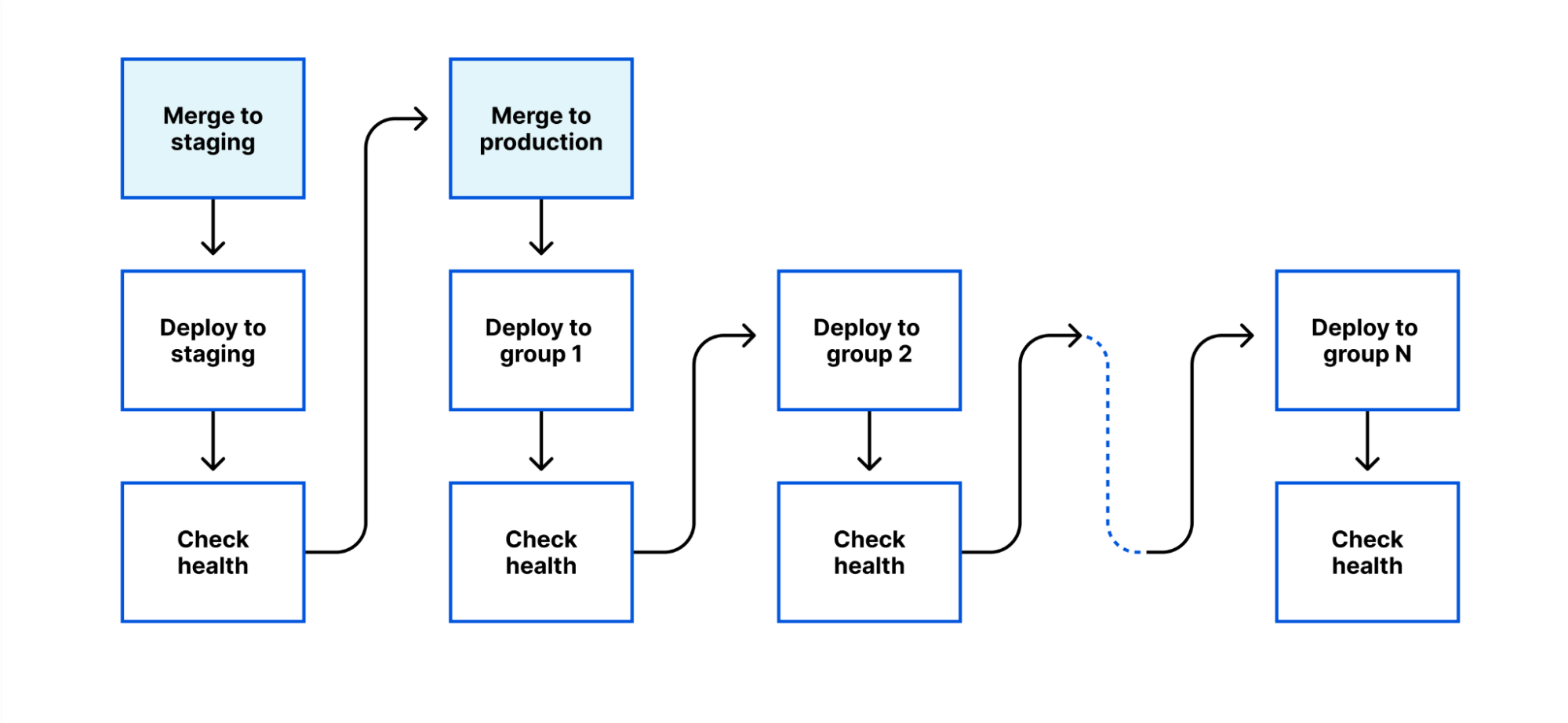
We’ve therefore built a new deployment system for internal workers, based around a few principles:
- Control deployments through git. A deployment to an internal-only environment would be triggered by a merge to a staging branch (with appropriate reviews). A deployment to production would be triggered by a merge to a production branch.
- Progressive deployment. A deployment starts with the lowest impact system (ideally, a pre-production system which mirrors production, but has no customer impact if it breaks). It then progresses through multiple stages, each one with a greater level of impact, until the release is completed.
- Health-mediated advancement. Between each stage, a set of end-to-end tests is performed, metrics are reviewed, and a minimum time must elapse. If any of these fail, the deployment is paused, or reverted; and this happens automatically, without waiting for a human to respond.
This system allows developers to focus on the behavior of their system, rather than the mechanics of a deployment.
There are still plenty of plans for further improvement to many of these systems - but they’re running now in production for many of our internal workers.
Moving from prototype to production
Our initial prototype has done its job: it’s shown us what capabilities we needed to add to our developer platform to be able to build more of our internal systems on it. We’ve added a large set of capabilities for internal service development to the developer platform, and are using them in production today for relatively small components of the system. We also know that if we were about to build our application security and performance products from scratch today, we could build them on the platform.
But there’s a world of difference between having a platform that is capable of running our internal systems, and migrating existing systems over to it. We’re at a very early stage of migration; we have real traffic running on the new platform, and expect to migrate more pieces of logic, and some full production sites, to run without depending on the FL service within the next few months.
We’re also still working out what the right module structure for our system is. As discussed, the platform allows us to split our logic into many separate workers, which communicate efficiently, internally. We need to work out what the right level of subdivision is to match our development processes, to keep our code understandable and maintainable, while maintaining efficiency and throughput.
What’s next?
We have a lot more exploration and work to do. Anyone who has worked on a large legacy system knows that it is easy to believe that rewriting the system from scratch would allow you to fix all its problems. And anyone who has actually done this knows that such a project is doomed to be many times harder than you expect - and risks recreating all the problems that the old architecture fixed long ago.
Any rewrite or migration we perform will need to give us a strong benefit, in terms of improved developer experience, reliability and performance.
And it has to be possible to migrate without slowing down the pace at which we develop new products, even for a moment.
We’ve done this before
Rewriting systems to take advantage of new technologies is something we do a lot at Cloudflare, and we’re good at it. The Quicksilver system has been fundamentally rebuilt several times - migrating from Kyoto Tycoon, and then migrating the datastore from LMDB to RocksDB. And we’ve rebuilt the code that handles HTML rewriting, to take advantage of the safety and performance of new technologies.
In fact, this isn’t even the first time we’ve rewritten our entire technical architecture for this very system. The first version of our performance and security proxy was implemented in PHP. This was retired in 2013 after an effort to rebuild the system from scratch. One interesting aspect of that rewrite is that it was done without stopping. The new system was so much easier to build that the developers working on it were able to catch up with the changes being made in the old system. Once the new system was mostly ready, it started handling requests; and if it found it wasn’t able to handle a request, it fell back to the old system. Eventually, enough logic was implemented that the old system could be turned off, leading to:
Author: Dane Knecht
Date: Thu Sep 19 19:31:15 2013 -0700
remove PHP.
It’s harder this time
Our systems are a lot more complicated than they were in 2013. The approach we’re taking is one of gradual change. We will not rebuild our systems as a new, standalone reimplementation. Instead, we will identify separable parts of our systems, where we can have a concrete benefit in the immediate future, and migrate these to new architectures. We’ll then learn from these experiences, feed them back into improving our platform and tooling, and identify further areas to work on.
Modularity of our code is of key importance; we are designing a system that we expect to be modified by many teams. To control this complexity, we need to introduce strong boundaries between code modules, allowing reasoning about the system to be done at a local level, rather than needing global knowledge.
Part of the answer may lie in producing multiple different systems for different use cases. Part of the strength of the developer platform is that we don’t have to publish a single version of our software - we can have as many as we need, running concurrently on the platform.
The Internet is a wild place, and we see every odd technical behavior you can imagine. There are standards and RFCs which we do our best to follow - but what happens in practice is often undocumented. Whenever we change any edge case behavior of our system, which is sometimes unavoidable with a migration to a new architecture, we risk breaking an assumption that someone has made. This doesn’t mean we can never make such changes - but we do need to be deliberate about it and understand the impact, so that we can minimize disruption.
To help with this, another essential piece of the puzzle is our testing infrastructure. We have many tests that run on our software and network, but we’re building new capabilities to test every edge-case behavior of our system, in production, before and after each change. This will let us experiment with a great deal more confidence, and decide when we migrate pieces of our system to new architectures whether to be “bug-for-bug” compatible, and if not, whether we need to warn anyone about the change. Again - this isn’t the first time we’ve done such a migration: for example, when we rebuilt our DNS pipeline to make it three times faster, we built similar tooling to allow us to see if the new system behaved in any way differently from the earlier system.
The one thing I’m sure of is that some of the things we learn will surprise us and make us change direction. We’ll use this to improve the capabilities and ease of use of the developer platform. In addition, the scale at which we’re running these systems will help to find any previously hidden bottlenecks and scaling issues in the platform. I look forward to talking about our progress, all the improvements we’ve made, and all the surprise lessons we’ve learnt, in future blog posts.
I want to know more
We’ve covered a lot here. But maybe you want to know more, or you want to know how to get access to some of the features we’ve talked about here for your own projects.
If you’re interested in hearing more about this project, or in letting us know about capabilities you want to add to the developer platform, get in touch on Discord.
We protect entire corporate networks, help customers build Internet-scale applications efficiently, accelerate any website or Internet application, ward off DDoS attacks, keep hackers at bay, and can help you on your journey to Zero Trust.
Visit 1.1.1.1 from any device to get started with our free app that makes your Internet faster and safer.
To learn more about our mission to help build a better Internet, start here. If you're looking for a new career direction, check out our open positions.