
2023-5-12 08:49:0 Author: www.cnblogs.com(查看原文) 阅读量:20 收藏
(1)数据域(domain)
用D={χ,P(X)}表示,它包含两部分:特征空间χ和边缘概率分布P(X)其中X={x1,...xn}∈χ
在文本分类任务中,把每一个单词看作二值的特征即出现或者不出现,所有检索词向量的空间就是χ,xi对应某一文本第i个词向量的值,X就是特定的学习样本。
如果说两个数据域不同,表示两个数据域的特征空间或者边缘概率分布不同。
- 特征空间不同
- 输入层不同张量维度的像素矩阵
- None,48,48
- None,224,224,3
- ....
输入层不同长度、不同词向量维度的token序列
- None,1024,2048
- None,512,1024
- 相同的词在不同的数据域中拥有不同的权重(例如不同语言的文本翻译任务)
- ....
- 输入层不同张量维度的像素矩阵
- 边缘概率分布不同
- P dim=(1,10)的MNIST,0-9手写数字识别
- P dim=(1024,256),输出一段1024长度的ASCII字符的文本序列
(2)任务(task)
用T={У,ƒ(X)}表示,它包含两部分:标签空间У和目标预测函数ƒ(X),ƒ(X)也可以看作条件概率P(y|x)
在文本分类任务中У是所有标签的集合。
(3)迁移学习的形式化描述
迁移学习是指源数据域到目标数据域的迁移。
源数据域Ds={(x1,y1),...,(xn,yn)},其中xn∈χs,yn∈Уs。目标数据域Dt={(x’1,y’1),...(x’n,y’n)},其中x’n∈χt,y’n∈Уt。
一般情况下Ds的数据量总是远远大于Dt的数据量。
(4)Transfer Learning的形式化描述
给出源领域的数据Ds和任务Ts,目标领域的数据Dt和任务Tt,迁移学习旨在使用源领域Ds和Ts中的知识去改进对于目标领域的预测函数ƒt(),其中Ds≠Dt或者Ts≠Tt。
- 由于D={χ,P(X)},在上述的定义中Ds≠Dt意味着χs≠χt或者Ps(X)≠Pt(X)。在文本分类任务中,这两种情况分别意味着在源文本集和目标文本集之间,词特征不同(两个文本使用两种不同语言的情况)以及边缘分布不同(生成的词向量空间不同)。
- 由于T={У,ƒ(X)},Ts≠Tt意味着Уs≠Уt或者Ps(y|x)≠Pt(y|x)。在文本分类任务中,这两种情况分别意味着源领域上的任务要求将文本分为2类,目标领域的任务要求将文本分为10类,以及在定义的类别上,源数据和目标数据数量不平衡。
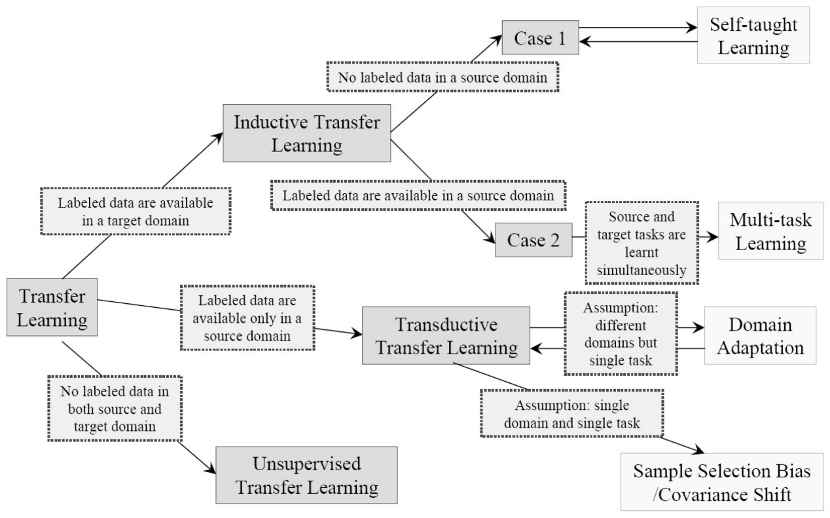
根据源领域和目标领域的相似度,可以将情况总结如下:
| Ds&Dt | Ts&Tt | ||
| 传统机器学习(和具体任务对应的数据域一一绑定) | 相同 | 相同 | |
| 迁移学习 | 归纳式迁移学习 | 相同/相关 | 相关 |
| 无监督迁移学习 | 相关 | 相关 | |
| 直推式迁移学习 | 相关 | 相同 | |
根据每一种类型的迁移学习,又可根据标签数据的多少分情况讨论:
- 归纳式迁移学习
- 源数据域包含有大量标签数据,这时归纳式迁移学习和多任务学习类似。
- 源数据域没有可用的标签数据,这时归纳式迁移学习相当于自我学习。
- 直推式迁移学习
- 特征空间不同χs≠χt。
- 特征空间相同χs=χt但是边缘分布不同Ps(X)≠Pt(X),此时可用域适应,样本选择偏差和Covariate Shift。
- 无监督迁移学习
总结如下表:
| 相关领域 | 源数据域标签 | 目标数据域标签 | 任务 | |
| 归纳式迁移学习 | 多任务学习 | 有 | 有 | 分类回归 |
| 自我学习 | 无 | 有 | 分类回归 | |
| 直推式迁移学习 | 域适应,样本选择偏差和Covariate Shift | 有 | 无 | 分类回归 |
| 无监督迁移学习 | 无 | 无 | 聚类降维 |
0x1:归纳式迁移学习
1、基于实例的迁移
主要思想就是在目标领域的训练中,虽然源数据域不能直接使用,但是可以从中挑选部分,用于目标领域的学习。
- TrAdaBoost算法是AdaBoost的提升版本,用于解决归纳式迁移学习问题。它假设源数据域和目标数据域使用相同的特征和标签集合,但是分布不相同。有一些源数据对于目标领域的学习是有帮助的,但是还有一些是无帮助甚至是有害的。所以它迭代地指定源数据域每一个数据的权重,旨在训练当中减小“坏”数据的影响,加强“好”数据的作用。
- 使用启发式的方法,根据条件概率P(Yt|Xt)和P(Ys|Xs)的差异,去除源数据域中“不好”的样本。
2、基于特征表示的迁移
主要思想是寻找一个“好”的特征表示,最小化域间差异和分类回归的误差。可以分为有监督和无监督两种情况。
有监督特征构造的基本思想是学习一个低维的特征表示,使得特征可以在相关的多个任务中共享,同时也要使分类回归的误差最小。此时目标函数如下:
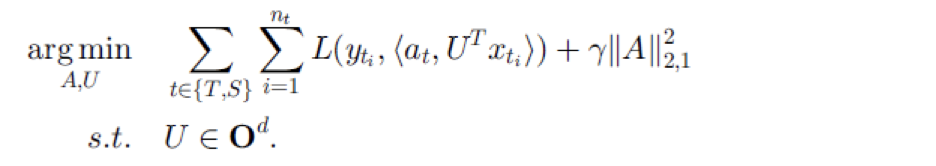
其中S和T表示源域和目标域,U是将高维的数据映射为低维表示的矩阵。
无监督特征构造的基本思想包含两步,
第一步在源领域上学习一个基向量b和基于这组基对于输入x的新的表示a
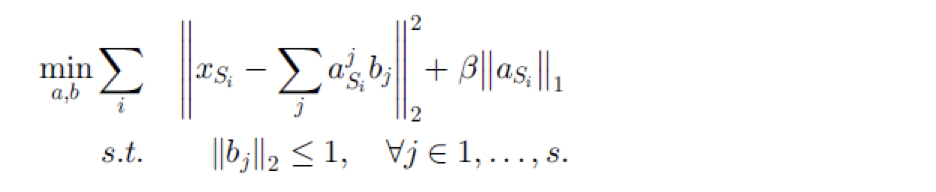
在得到基向量b之后,第二步在目标领域上根据基向量b来学习其特征表示
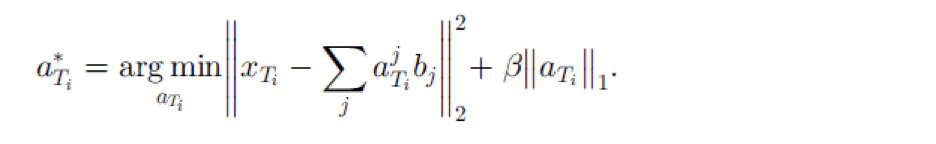
最后通过使用目标领域的新特征来训练分类回归模型。
3、基于参数的迁移
参数迁移方法假定在相关任务上的模型应该共享一些参数、先验分布或者超参数。
多任务学习中多使用这种方法,通过将多任务学习对于源域和目标域的权值做改变(增大目标域权值,减小源域权值),即可将多任务学习转变成迁移学习。
0x2:直推式迁移学习
1、基于实例的迁移
直推式迁移学习因为任务相同,所以可以直接使用源域上的损失函数。在源域上最小化目标函数如下
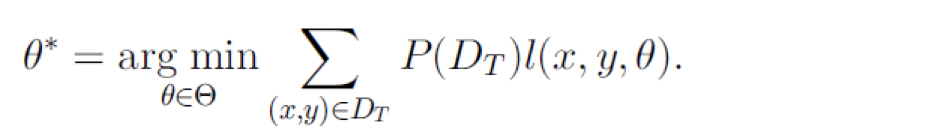
但是由于目标域数据是没有标签的,所以取而代之使用源域的数据,如果Ds和Dt分布相同,可以直接使用
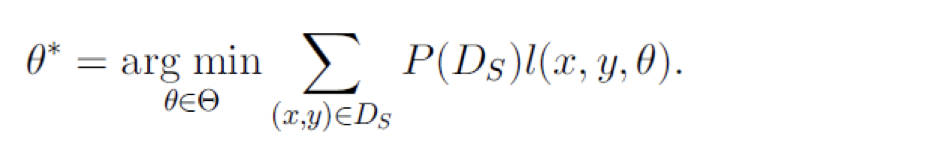
否则,就不能简单的使用Ds,而是需要通过转化,对于每一个样本增加一个权值

此时需要计算

因为直推式迁移学习任务相同的假设,Ps(y|x)=Pt(y|x),可得出

接下来只要计算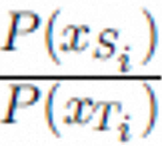 就可以解决直推式迁移学习问题。
就可以解决直推式迁移学习问题。
2、基于特征表示的迁移
大多数特征表示迁移方法都基于非监督学习。SCL算法,使用目标域的无标签数据提取一些相关特征从而减小两个域之间的差异。
SCL算法第一步在两个域的无标签数据上定义一个pivot特征集合(包含m个pivot特征),然后把一个pivot特征看作一个标签
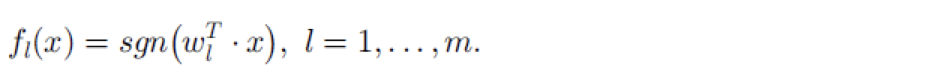
最终通过学习得到![]() ,第三步将W矩阵做奇异值分解从而形成增广特征。
,第三步将W矩阵做奇异值分解从而形成增广特征。
0x3:无监督迁移学习
1、基于特征表示的迁移
无监督迁移学习的研究工作较少,在无监督迁移问题上通常通过自我聚类以及TDA(Transferred Discriminative Analysis)算法来聚类和降维。
自我聚类的目标是基于源域无标签数据的帮助,来对目标域无标签数据聚类,通过学习跨域的共同的特征空间,帮助目标域的聚类,目标函数如下:
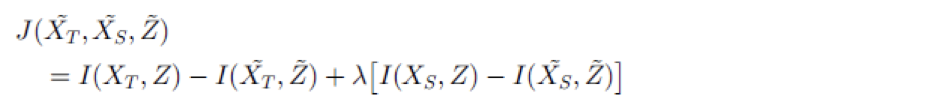
其中Z是共享的特征空间,I计算两个量之间的互信息,最终要使得聚类过后损失的互信息最小。

0x4:Deep neural network下的迁移学习
DNN是一个通过pre-train获得数据的分层特征表达,然后用高层语义分类的模型,模型的底层是低级语义特征(比如说,边缘信息,颜色信息等),这样的特征实际上在不同的分类任务中都是不变的,而真正区别的是高层特征。
常用的做法是使用新的数据集去更新AlexNet,GoogleNet的最后几层网络权值,来实现简单的“迁移”这个小trick。
笔者关于这个问题做了一些实验和分析,详情可以参阅另一篇文章。
0x5:未来的发展趋势
- 第一、针对领域相似性、共同性的度量,目前还没有深入的研究成果,未来还需要确定更加准确的度量方法。
- 第二,在算法研究方面,迁移学习的应用范围很广。迁移学习多用于分类算法方面,其他方面的应用算法有待进一步研究。比如情感分类、强化学习、排序学习、度量学习、人工智能规划等。
- 第三,关于可迁移学习条件,获取实现正迁移的本质属性还没有完全摸透,如何避免负迁移,实现迁移的有效性也是方向之一。
负迁移是一个重要的技术难点。负迁移表示目标域训练中源域数据的使用不仅没有提升模型能力,反而降低了识别率的现象。尽管实际当中如何避免负迁移现象是很重要的问题,但是在这个问题上的研究依然很少,经验表明如果两个任务太不相似,那么鲁莽的强制迁移会损害性能。目前已有一些对任务和任务之间聚类的探索,旨在对如何自动避免负迁移提供指导。
另外在非简单分类或者回归的问题上,如何更好地优化迁移算法,以达到适合任务的最佳效果,也是一个难点。在不同的应用背景下,迁移学习是否适合以及需要做怎样的改进都是值得去考虑的。
Transfer Learning的初衷是节省人工标注样本的时间、节省训练新领域模型的时间成本,让模型可以通过已有的标记数据(source domain data)向未标记数据(target domain data)迁移。从而训练出适用于target domain的模型。

上图是某行人检测任务数据集当中的4张图片,假设前两张正对着摄像机的行人作为训练集,后两张背对着的行人图片作为测试集,结果该模型的测试评分会很差,因为训练时没有考虑到摄像机观察角引起的问题,相类似在图像识别领域会有很多因素会降低识别率(例如光照,背景等)。
那接下里的问题是,能否用一些未标记的图片(类似图3,4这样的图),增强我们的行人检测模型,让它不仅可以识别正对着的行人,还可以识别背对着的行人?这就是迁移学习要干的事。这涉及到domain adaptation的概念。
domain adaptation是迁移学习原先就有的概念,在研究source domain和target domain时,基于某一特征,会发现两个domain的数据分布差别很大,比如说选择某一区域的颜色信息作为图像特征,下图红线表示source dataset的颜色信息值分布,蓝线表示target dataset的颜色信息值分布,很明显对于这一特征来讲,两个域的数据本来就是有shift的。而这个shift导致我们evaluate这个模型的时候准确率会大大降低。
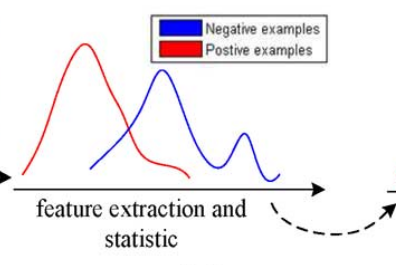
domain adaptation旨在利用各种的feature transformation手段,学习一个域间不变的特征表达,基于这一特征,我们就可以更好的同时对两个域的数据进行分类了。
迁移学习的本质是适应(adaptation)。适应可以是
- 适应一个任务
- 适应一种模态
- 适应一个领域
- 适应一种语言
- 适应一份新数据等
所谓“适应”,有两方面的内涵:
- 一是只有已经能用的东西才能“适应”新东西
- 二是这个能用的东西需要在别的场景下发挥作用
基于上述的概念总结,LM DNN里大致分成了如下几个研究领域:
- 适应一个任务叫Cross-type/task Transfer(CV叫Multi-task Learning)
- 适应一个领域(多用于CV)叫Cross-domain Learning或Meta-learning,也有一个响亮的名字Domain Adaptation
- 适应一种模态叫Cross-modal Transfer
- 适应一种语言叫Cross-lingual Transfer
- 适应一份新数据叫Knowledge Transfer,学界给了一个厉害的名字,叫持续学习(Continual/Life-long Learning),本质上是时序上的适应
0x1:任务迁移 Cross-type Transfer
任务迁移在CV里面叫做Domain Adaption(领域迁移),本质就是为两个任务找到一个相同的semantic space,从而在新任务上达到不错的效果。
0x2:语言迁移 Cross-lingual Transfer
语言迁移的基本思想与任务迁移基本一致,也是将不同语言的语义空间融合起来,如下图所示。
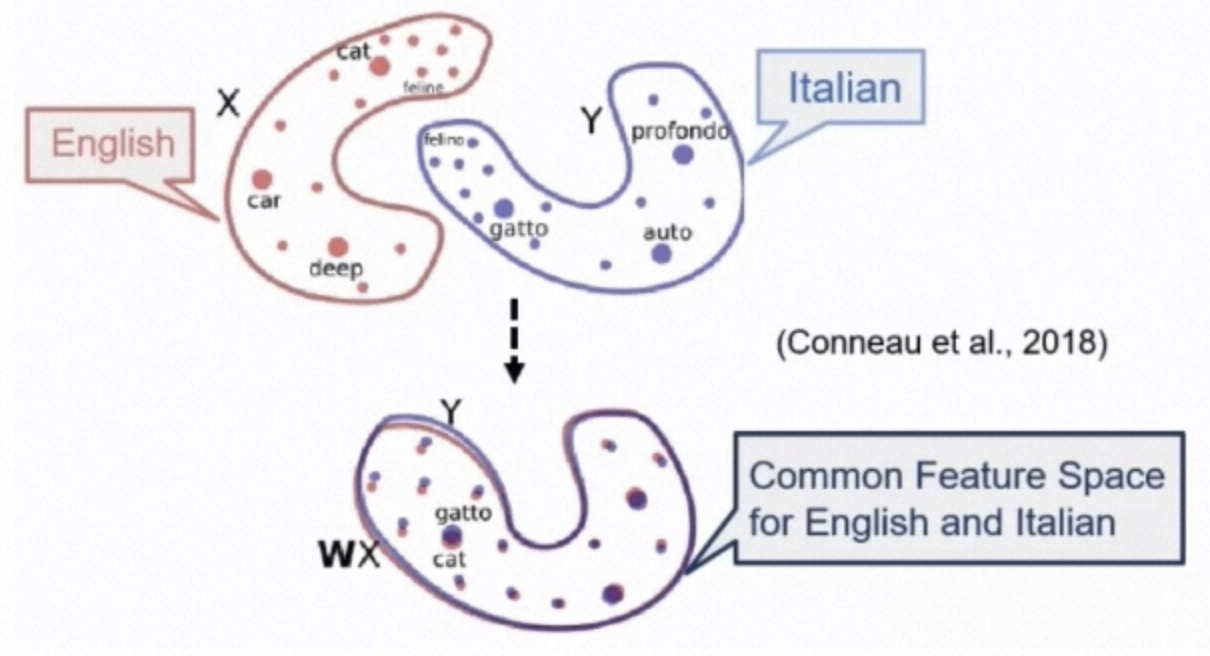
显式融合的基本做法有NMT(翻译)、Word Aligner(单词级别alignment)、字典法、多语言预训练模型。
隐式融合的基本做法是language-agnostic(语言不可知论)的语义特征学习,也就是让模型自己学习不同语言share的统一语义/结构空间。统一语义空间一定是可行的,因为不同的语言都想要表达一个意思;统一的结构空间在2019年才被明确证明可行,因为Subburathinam等学者发现不同的语言一般有相同的依赖结构。
0x3:持续学习 Continual Learning/Life-long Learning
持续学习就是模型不freeze。例如我训练了一个CNN模型,在提取一次后,知识(模型里的参数)就固定了。持续学习,就是让模型不断地学习新知识,也就是参数可以不断使用新的Annotations进行更新。
持续学习基本上有两个挑战:
- 一个是灾难性遗忘(Catastrophic Forgetting),也就是在学习新知识的时候会忘掉旧知识
- 一个是知识迁移(Knowledge Transfer),也就是将知识从旧任务迁移到新任务
持续学习有三个基本方法:
- 经验重演(Experience Replay)
- 知识蒸馏(Knowledge Distillation)
- Task-specific Adapter(热插拔)
1、经验重演
经验重演法就是记录训练旧模型所用的数据,并且在用新任务上周期性地重新输入部分旧数据进行更新。同时,如果经过合理的调整,新数据也可以提升旧任务的性能。
方法上,
- 新数据训练旧任务很简单,直接训练即可
- 旧数据训练新任务可以通过用旧模型的参数初始化新模型来完成
经验重演的原理非常简单,但作用明显,结果如下图所示(Yu等人,2021)。

2、知识蒸馏
知识蒸馏法就是删掉没用的或错误的知识。
- 在特征上,可以使得模型提取和原模型相似的特征
- 在预测上,可以使得模型的预测输出和原模型尽可能相似
- 在输入样本的选择上,可以挑选与原来的样本形式相近的样本
3、热插拔
每次增加一个新的任务,就固定老的模型参数,并且增加一些新的专门用来做新任务的参数。
比较典型的方案有:
- VGG16 freeze layers without toplayer + DNN模型
- Adapters-tune:在原始的预训练模型中的每个transformer block中加入一些参数可训练的模块,本质上adapter是在模块的后面接上一个mlp,对模块的计算结果进行一个后处理
- Lora:和原始PLM加入一个并行的transformer模型,冻结了原始预训练模型的权重,并将低秩分解矩阵注入到新增模型transformer的每一层,减少了训练参数量。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加
4、指令对齐(instructions align)
训练数据集构造上的创新(instruction-prompt格式数据集)
第一个范式时代是有监督时代
手写字体的识别精度很差,有人提出了可以用深度学习识别,出现了有监督学习。
标注数据集变成一个十分重要的事情,因为数据集质量越高,数量越大,模型效果越好。CV界的代表例是ImageNet,NLP界的代表例是BERT。
第二个范式时代是弱/无监督时代
数据标注成本太高,各种弱标注(标注部分数据或标签不足以完成整个任务)和无标注(纯文本或纯图片)方法诞生,例如对比学习、能量模型方法,从而产生了大量弱监督、无监督模型和方法。CV界的代表例是DC-GAN,NLP界的代表例是GPT-2。
第三个范式时代是少/零样本时代,也就是迁移学习(领域自适应)时代
对比学习等方法仍需要进行大量数据的训练,选择数据的成本甚至比有监督学习更高,因此不需要任何数据就能在新任务上work的泛化性愈发显得重要。迁移学习在CV和NLP界的方法基本一致,都没有专门的模型,而是使用各种tricks对模型进行调整。这是我们所处的时代,Domain Adaptation也是目前发展最快的范式。
第四个范式时代是无学习生成时代,一切都可以通过更改输入解决
CV界代表例是CLIP,NLP界代表例是GPT-3。
迁移学习的主流发展方向自从提出,至今都没有改变。由于迁移学习的根本目标是学习人脑的泛化能力,其主流方向一直是
- 如何降低迁移学习的成本(迁移学习可规模化,一般称为Scalability)
- 以及想办法弄清楚迁移学习的原理
降低成本方面,例如Cross-task Transfer,热点就集中在如何减少人力成本。例如Information Extraction的Cross-task任务需要为模型的每一个任务设计一个专有的Template(模板),并且要尽量优化,那么可规模性就很差,1000个任务需要1000个模板,这是无法接受的。现在由于GPT-3的提出,用Prompt Tuning做Template的自动生成就变成了当前的研究热点。又例如Continual Learning,热点就集中在如何缩小Memory Replay的记忆成本(数据大小),因为学了后面的知识还要保存前面的知识是不可规模化的,假设一个机器学了三年的知识,存储的内容可能到达PetaByte的量级,存储和训练时间都成为问题。
工作原理方面,例如Cross-task Transfer,关键在于如何选择模板。怎样的模板才是好的?哪些词汇种子最好?为什么是最好的呢?这就是迁移学习的最优化工作,根据大量实验推导出迁移学习的最优情况,并且尝试分析为什么会有这么好的性能。
转化为技术视角的问题:如何通过增加、删除、修改基础神经神经网络的结构和参数,使新的神经网络具备新领域任务的能力?
参考资料:
https://www.zhihu.com/question/41979241 https://zhuanlan.zhihu.com/p/35890660
如有侵权请联系:admin#unsafe.sh