freebuf能力中心开源了一套资产扫描系统(https://github.com/TophantTechnology/ARL),提供docker版,但并无源码搭建的文档(无完整文档)。于是在星光哥及小明哥指导下完成源码搭建,在这里记录一下。
- centos7.6 2h4g
首先从github下载源码,我下载到opt 目录下。
phantomjs
先在官网下载phantomjs
# 下载
wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
# 解压
tar -jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
# 修改环境变量
vim /etc/profile
# 刷新环境变量
source /etc/profile
# 验证
phantomjs --version
/etc/profile文件末尾增加如下内容(路径看自己解压完放哪)
export PATH=$PATH:/opt/phantomjs-2.1.1-linux-x86_64/bin
报错这个错的话phantomjs: error while loading shared libraries: libfontconfig.so.1: cannot open shared object file
运行
yum -y install fontconfig-devel
安装相关软件包
yum install epel-release
yum install rabbitmq-server supervisor
yum install wqy-microhei-fonts fontconfig
rabbitmq-server
上面已经安装了rabbitmq-server
# 启动
systemctl start rabbitmq-server
# 配置
rabbitmqctl add_user arl arlpassword
rabbitmqctl add_vhost arlvhost
rabbitmqctl set_user_tags arl arltag
rabbitmqctl set_permissions -p arlvhost arl ".*" ".*" ".*"
nmap
下载nmap
https://nmap.org/dist/nmap-7.80-1.x86_64.rpm
# 安装
rpm -ivh nmap-7.80-1.x86_64.rpm
mongoDB
vim /etc/yum.repos.d/mongodb-org-4.0.repo
[mngodb-org]
name=MongoDB Repository
baseurl=http://mirrors.aliyun.com/mongodb/yum/redhat/7Server/mongodb-org/4.0/x86_64/
gpgcheck=0
enabled=1
安装yum -y install mongodb-org
开启无IP限制(方便看数据)
vim /etc/mongod.conf
service mongod restart
mongodb 添加认证
# mongo
> use arl
> db.createUser({user:'admin',pwd:'admin',roles:[{role:'dbOwner',db:'arl'}]})
> exit
开启登录验证
# 关闭数据库
service mongod stop
# 开启验证登录
vim /etc/mongod.conf
security:
authorization: enabled
# service mongod start
添加账号密码
mongo -u admin -p admin --authenticationDatabase "arl"
use arl
db.user.insert({ username: 'admin123', password: hex_md5('arlsalt!@#'+'admin123') })
exit
GeoIP数据库
由于官方政策更新请前往maxmind注册下载GeoLite2-City.tar.gz,GeoLite2-ASN.tar.gz 解压。
在config.yaml中配置好相关路径。
我放在了/data/GeoLite2
config.yaml配置
添加并修改配置文件
cp app/config.yaml.example app/config.yaml
我的配置
CELERY:
BROKER_URL : "amqp://arl:arlpassword@localhost:5672/arlvhost"
MONGO:
URI : 'mongodb://admin:admin@localhost:27017/arl'
DB : 'arl'
RISKIQ:
EMAIL: "[email protected]"
KEY: "3d78801683997245c14192d630d41b1c0ee5f80f12c261e5a1007f5e1ad2a7b7"
GEOIP:
CITY: '/data/GeoLite2/GeoLite2-City.mmdb'
ASN: '/data/GeoLite2/GeoLite2-ASN.mmdb'
FOFA:
EMAIL: ""
KEY: ""
ARL:
AUTH: true
API_KEY: ""
BLACK_IPS:
- 127.0.0.0/8
#- 0.0.0.0/8
#- 172.16.0.0/12
#- 100.0.0.0/8
#- 10.0.0.0/8
#- 192.168.0.0/16
riskiq可以自行注册。
nginx
# centOS7.6下安装nginx
cd /yum install gcc gcc-c++ # 安装依赖
wget http://nginx.org/download/nginx-1.17.1.tar.gz # 下载nginx源码
tar -zxvf nginx-1.17.1.tar.gz # 解压
cd nginx-1.17.1 # 进入解压后的文件夹
./configure --prefix=/usr/local/nginx # 配置nginx安装路径
make
make install
ln -s /usr/local/nginx/sbin/nginx /usr/bin/nginx # 创建nginx软链接,若已被占用,则在 /usr/bin 下 rm-rf nginxnginx # 启动ngixnnginx -s stop # 停止nginx服务
导入配置nginx.conf,这边直接用root启动了(根据自身修改用户)。
user root;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /usr/local/nginx/conf/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 80;
server_name _;
#access_log logs/host.access.log main;
access_log off;
root /opt/ARL-master/docker/frontend;
location / {
try_files $uri $uri/ /index.html;
index index.html index.htm;
}
location /api/ {
proxy_pass http://127.0.0.1:5003/api/;
}
}
}
nginx启动。
无报错,前端则启动成功。
后端启动
安装依赖
pip3 install -r requirements.txt
WEB 服务启动
gunicorn -b 0.0.0.0:5003 app.main:arl_app -w 3 --access-logfile arl_web.log
CELERY 启动
celery -A app.celerytask.celery worker -l info -Q arltask -n arltask -c 2 -O fair -f arl_worker.log
利用tmux+supervisior启动。
安装tmux
yum install -y tmux
在项目根目录编写supervisior文件
supervisior.conf
[program:web_api]
command=gunicorn -b 0.0.0.0:5003 app.main:arl_app -w 3 --access-logfile /var/log/arl_web.log
;stdout_logfile=/var/log/web_api_stdout.log
;stderr_logfile=/var/log/web_api_stderr.log
autostart=true
autorestart=true
[program:celery_scan]
command=celery -A app.celerytask.celery worker -l info -Q arltask -n arltask -c 2 -O fair -f arl_worker.log
;stdout_logfile=/var/log/celery_scan_stdout.log
;stderr_logfile=/var/log/celery_scan_stderr.log
autostart=true
autorestart=true
[unix_http_server]
file=/tmp/supervisor.sock ; the path to the socket file
[supervisord]
logfile=/tmp/supervisord.log ; main log file; default $CWD/supervisord.log
logfile_maxbytes=50MB ; max main logfile bytes b4 rotation; default 50MB
logfile_backups=10 ; # of main logfile backups; 0 means none, default 10
loglevel=info ; log level; default info; others: debug,warn,trace
pidfile=/tmp/supervisord.pid ; supervisord pidfile; default supervisord.pid
nodaemon=true ; start in foreground if true; default false
minfds=1024 ; min. avail startup file descriptors; default 1024
minprocs=200 ; min. avail process descriptors;default 200
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///tmp/supervisor.sock ; use a unix:// URL for a unix socket
# 新建一个窗口
tmux new -s sp
# 在项目根目录运行
supervisord -c supervisord.conf
# 会话后台运行
ctrl + b + d
# 进入会话
tmux a -t sp
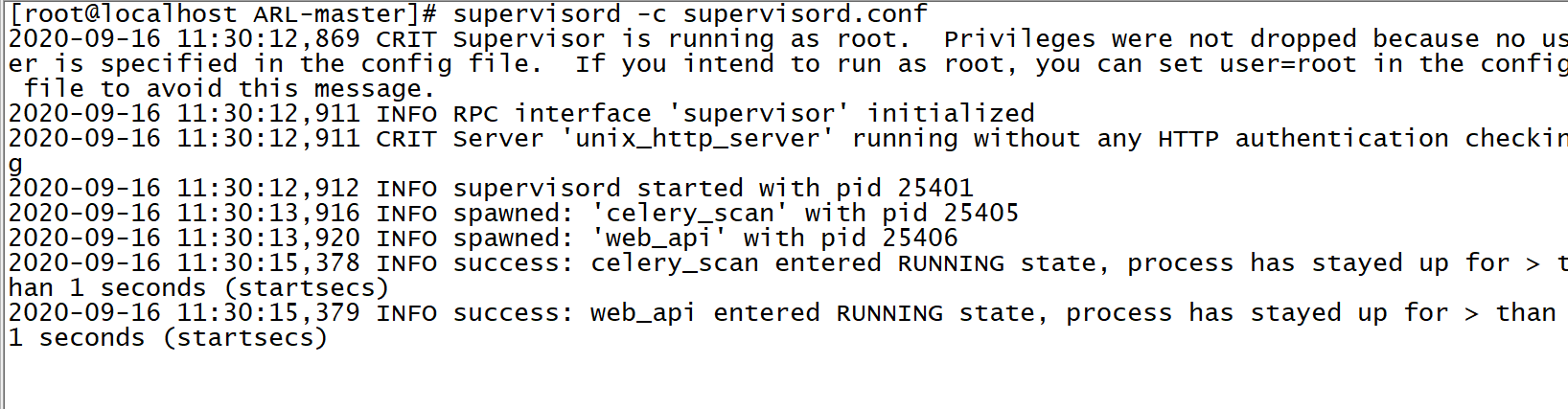
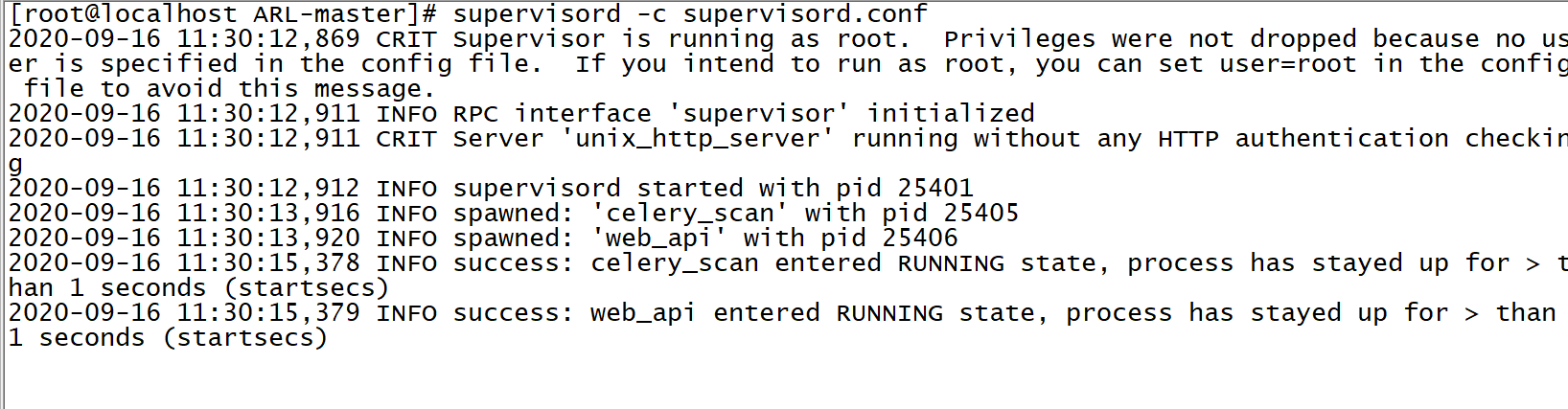
运行成功
使用
直接访问该IP
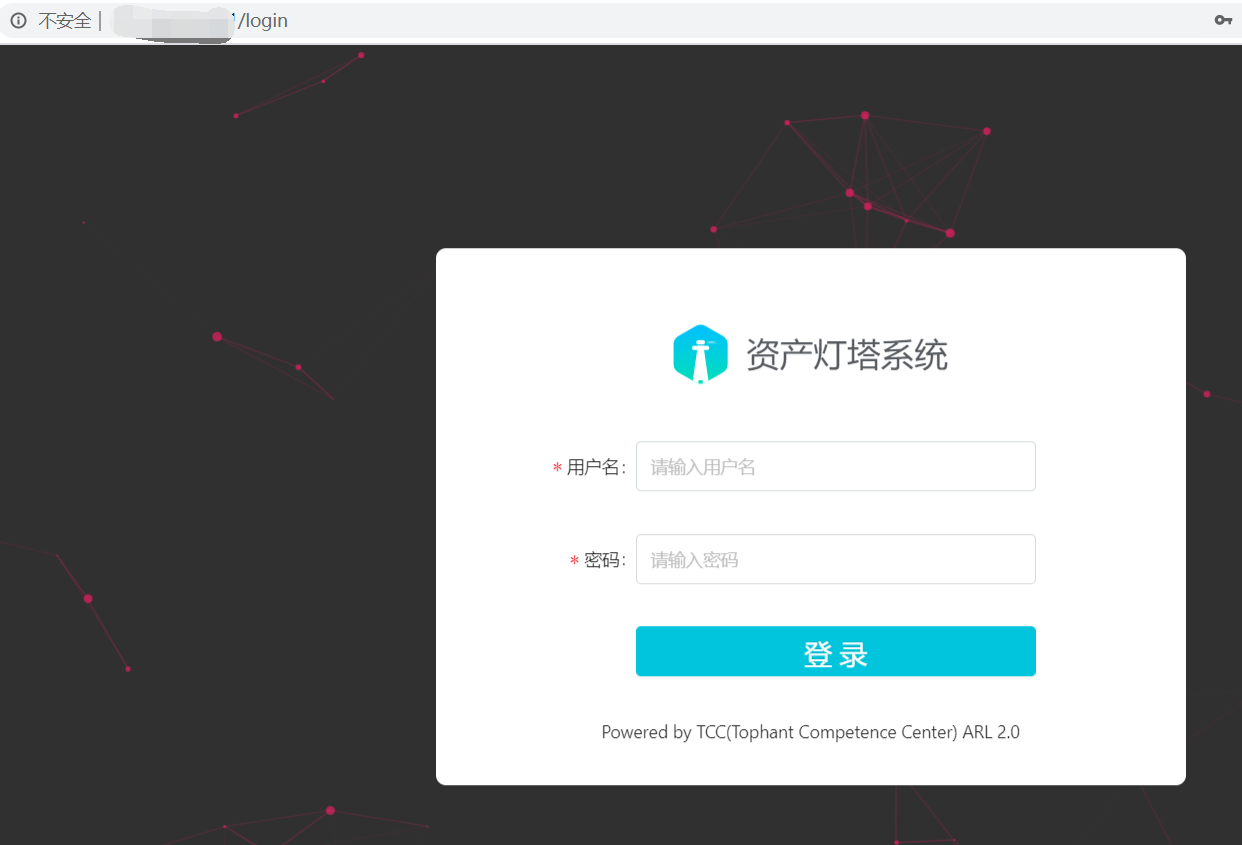
admin123/admin123登录
添加任务并看结果
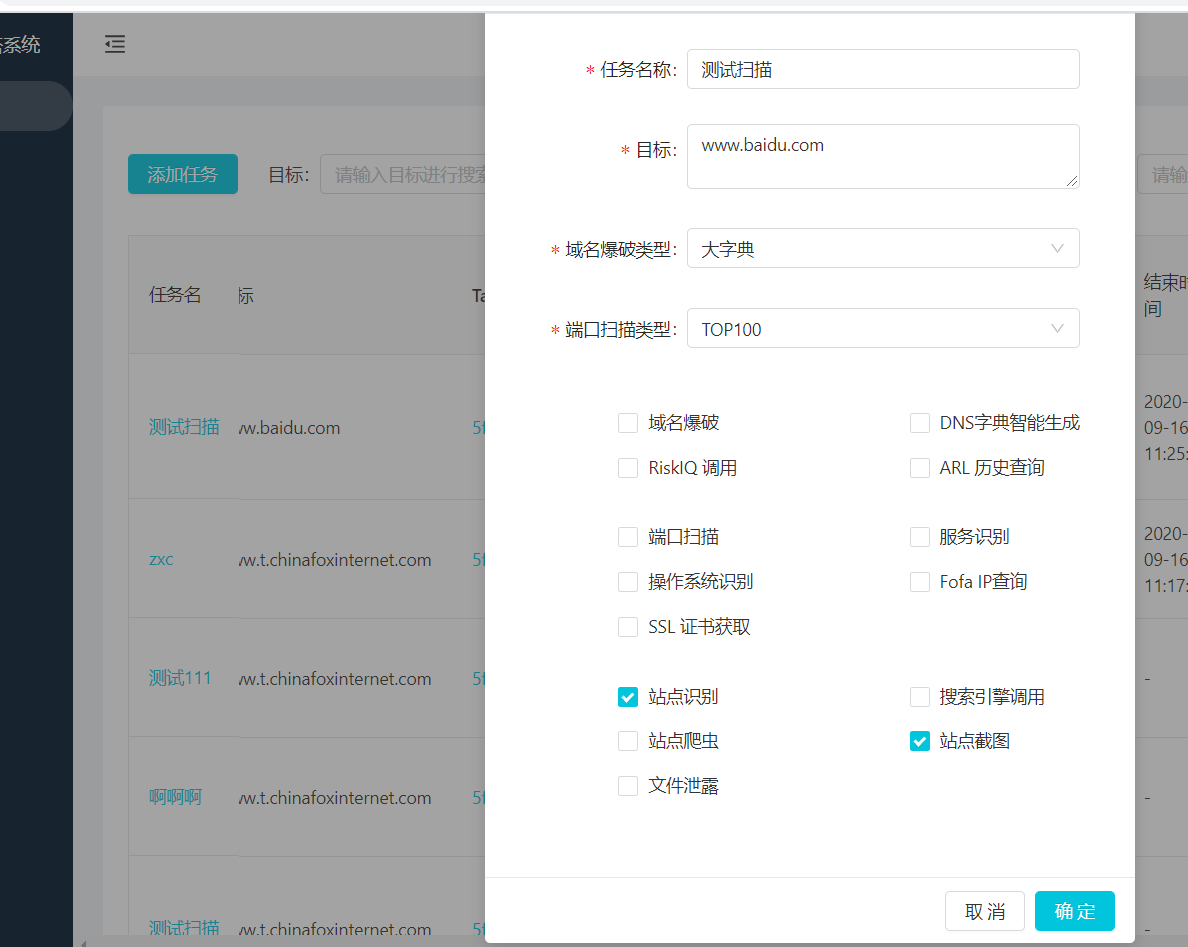
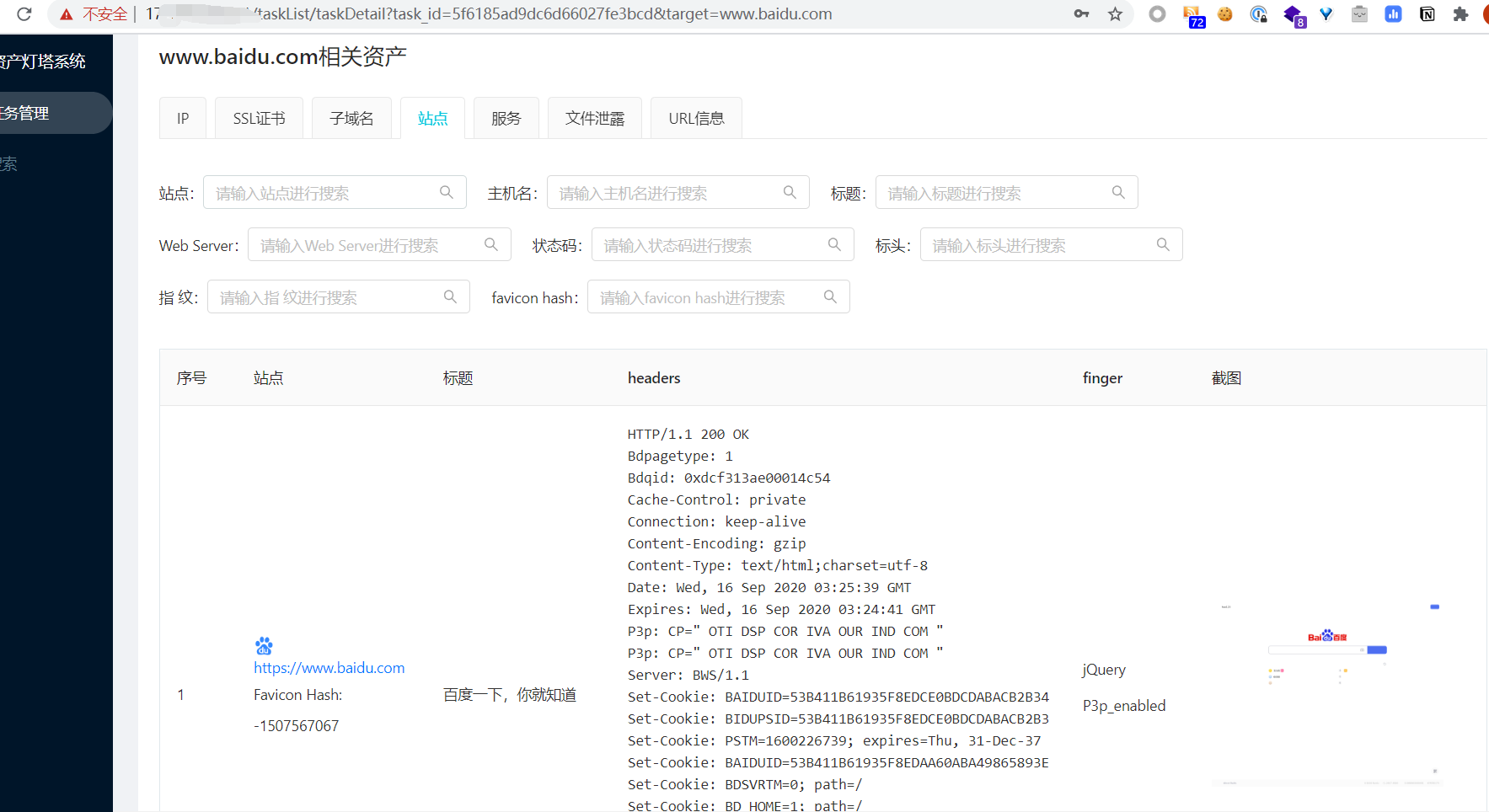
查看API文档并测试
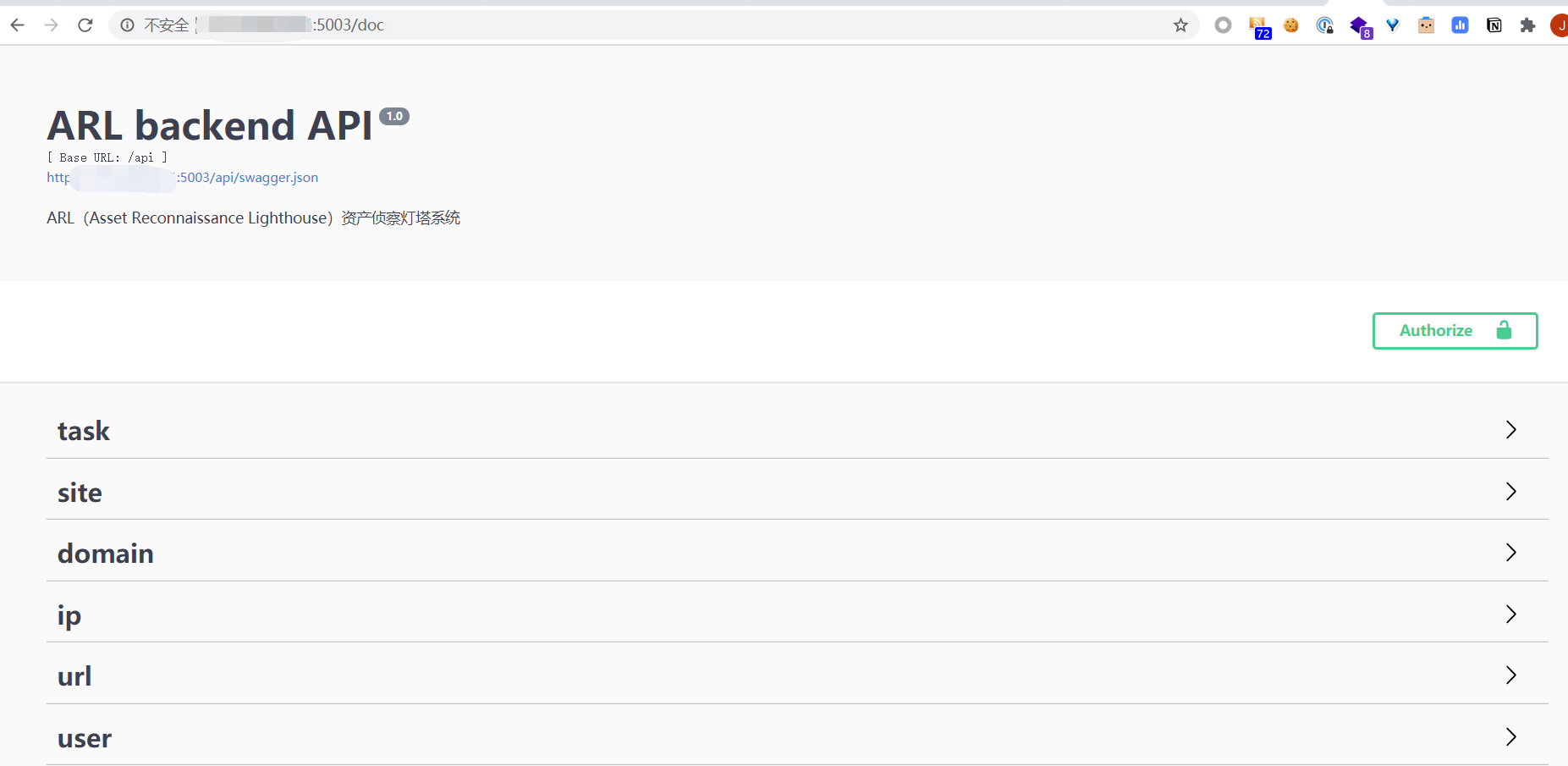
这边只简单提供下现需要的API(添加任务,停止任务,获取任务状态,获取任务结果)。具体需要的可查看文档自行编写。
首先在在app/config.yaml里加入API_KEY。然后重启下就可以了。
#!usr/bin/env python
# !coding=utf-8
__author__ = 'zhengjim'
import requests
import json
IP = "xxx.xxx.xxx.xxx" # ARL地址
token = "admin123" # ARL_KEY
headers = {
"token": token,
"Content-type": "application/json",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
# 添加任务
def add_task(name, target):
url = 'http://' + IP + '/api/task/'
data = {"name": name, "target": target, "domain_brute_type": "big", "port_scan_type": "top100",
"domain_brute": False, "alt_dns": False, "riskiq_search": False, "arl_search": False, "port_scan": False,
"service_detection": False, "os_detection": False, "fofa_search": False, "ssl_cert": False,
"site_identify": False, "search_engines": False, "site_spider": False, "site_capture": True,
"file_leak": False}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
result = r.json()
return result
# 停止任务
def stop_task(task_id):
url = 'http://' + IP + '/task/stop/'
url = url + task_id
r = requests.get(url=url, headers=headers)
result = r.json()
return result
# 获取任务状态
def get_task_status(task_id):
if len(task_id) != 24:
return False
url = 'http://' + IP + '/api/task/?page=1&size=10&_id={task_id}'.format(task_id=task_id)
r = requests.get(url=url, headers=headers)
result = r.json()
if result['total'] == 0:
return False
return {"status": result["items"][0]["status"]}
# 获取任务结果
def get_task_result(task_id):
if len(task_id) != 24:
return False
url = 'http://' + IP + '/api/site/?page=1&size=10&task_id={0}'.format(task_id)
r = requests.get(url=url, headers=headers)
result = r.json()
if result['total'] == 0:
return False
return result["items"][0]
if __name__ == '__main__':
# print(add_task("xxx", "www.baidu.com"))
# print(get_task_status("xxx"))
# print(get_task_result("xxx"))
# print(stop_task("xxx"))
使用了下,在资产探测收集还是很不错的,日站收集资产神器。而且是开源,也提供了API出来。在后续二开也很方便的。感谢开源!
如有侵权请联系:admin#unsafe.sh