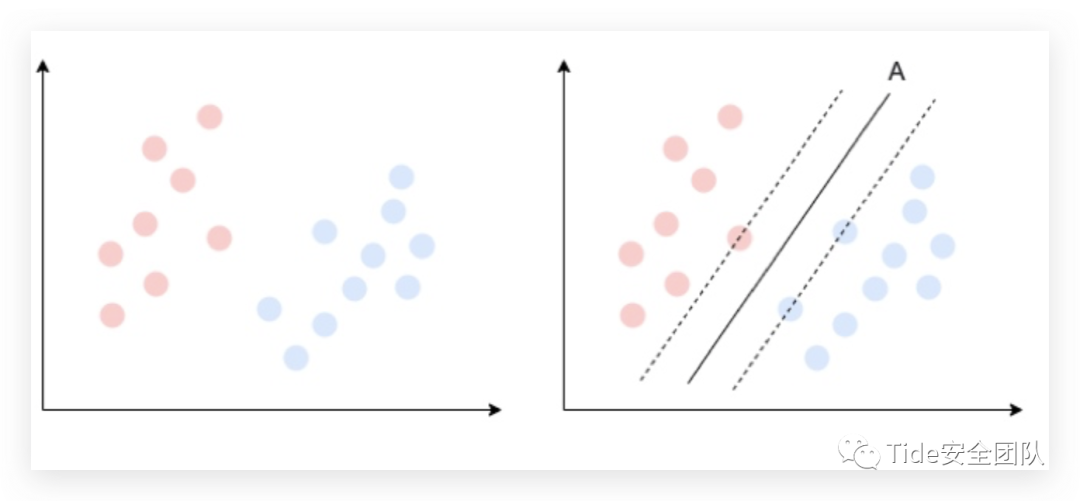
有监督学习:用已知某种或某些特性的样本作为训练集,以建立一个数学模型,再用已建立的模型来预测未知样本 无监督学习:让计算机自己学习,所有数据只有特征没有标记 半监督学习:训练数据一部分有标记,另一部分没有标记,没标记数据的数量往往极大于有标记数量
聚类(算法:K-means)
预测(算法:
线性回归、Gradient Boosting、AdaBoost、神经网络)
Windows
macOS
Linux(x86 / Power8)
系统要求:
32位或64位系统均可
下载文件大小:
约500MB
所需空间大小:
3GB空间大小(Miniconda仅需400MB空间即可)
零阶张量表示标量(scalar),一个数;
一阶张量为向量(vector),一维数组;
n阶张量可以理解为一个n维数组;
节点,每个节点都代表一个操作,是一种运算
有向边,每条边代表节点之间的关系(数据传递和控制依赖)
常规边(实线):代表数据依赖关系,代表数据。
任何维度的数据统称为张量,一个节点的运算输出成为另一个节点的输入,两个节点之间有tensor流动(值传递)
特殊边(虚线):不携带值,表示两个节点之间的控制相关性,可以控制操作的运行。比如,happens-before关系,源节点必须在目的节点执行前完成执行
tf.Session():
创建一个会话
tf.Session().as_default():
创建一个默认会话,当上下文管理器退出时会话没有关闭,还可以通过调用会话进行run()和eval()操作
node1=tf.constant(1.0,tf.float32,name="node1")node2=tf.constant(2.0,tf.float32,name="node2")node3=tf.add(node1,node2)#输出的结果不是一个具体的数字,而是一个张量的结构print(node3)
建立会话并显示运行结果sess=tf.Session()print("运行sess.run(node3)的结果:", sess.run(node3))sess.close()#关闭session
#创建一个会话,并通过Python中的 上下文管理器来管理这个会话with tf.Session() as sess:print( sess. run(node3))
init=tf.global_variables_initializer()sess.run(init)
tf.Graph.__init__():创建一个空图
tf.Graph.as_default():将图设置为默认图,并返回一个上下文管理器
tf.Graph.control_dependencies(control_inputs):定义一个控制依赖,并返回一个上下文管理器
tf.Graph.device(device_name_or_function):定义运行图所使用的设备,并返回一个上下文管理器
tf.Graph.name_scope(name):为节点创建层次化名称,并返回一个上下文管理器
tf.Operation.name:操作的名称
tf.Operation.typy:操作的类型
tf.Operation.inputs/tf.Operation.outputs:操作的输入输出
tf.Operation.control_inputs:操作的依赖
tf.Tensor.dtype:张量的数据类型
tf.Tensor.name:张量的名称
tf.Tensor.value_index:张量在操作输出中的索引
tf.Tensor.graph:张量所在的图
tf.Tensor.op:产生张量的操作
tf.summary():各类方法能够实现程序的可视化
tf.summary().scale:输出包含单个标量值的摘要
tf.summary().histogram:训练过程中变量的分布情况
tf.summary.distribution:显示weights分布
tf.summary.image:输出包含图片的摘要
Sigmoid(S型):
激活函数将加权和转换为介于0和1之间的值,是传统神经网络中最常用的激活函数之一,输入数据特征相差不明显可使用Sigmoid
Tanh:
由基本双曲函数双曲正弦和双曲余弦推导而来,收敛速度比Sigmoid快,输入数据特征相差明显可使用tanh,用Sigmoid和tanh时,需对输入进行规范化
ReLU(线性整流函数):
用于隐层神经元输出,大部分卷积神经网络都采用ReLU作为激活函数
Tf.train.GradientDescentOptimizer
Tf.train.AdadeltaOptimizer
Tf.train.AdagradOptimizer
Tf.train.AdagradDAOptimizer
Tf.train.MomentumOptimizer
Tf.train.AdamOptimizer
... ...
FIFOQueue:先入先出队列
RandomShuffleQueue:随即队列
预加载数据(preloaded data)
x1=tf.constant([1,2,3])
x2=tf.constant([2,3,4])
x3=tf.add(x1,x2)
定义常量或变量来保存所有数据,将数据直接嵌在数据流图中,当训练数据量过大,非常占内存
填充数据(feeding)
使用feed_dict()参数,存在数据类型转换也存在消耗内存问题
从文件读取数据(file)
先把文件写入到TFRecords二进制文件中,再从队列中读取数据
TFRecords是tensorflow自带的文件格式,是一种二进制文件,能够更加方便的复制和移动,不需要单独标记文件
了解TFRecords文件的读取流程,首先先理解什么是epoch:
epoch:使用训练集的全部数据对模型进行一次完整训练
参考书籍及文章:《TensorFlow技术解析与实战》https://blog.csdn.net/weixin_42555080/article/details/100704078https://blog.csdn.net/shenziheng1/article/details/84960746https://www.researchgate.net/figure/Nonlinear-function-a-Sigmoid-function-b-Tanh-function-c-ReLU-function-d-Leaky_fig3_323617663
E
N
D
关
于
我
们
Tide安全团队正式成立于2019年1月,是新潮信息旗下以互联网攻防技术研究为目标的安全团队,团队致力于分享高质量原创文章、开源安全工具、交流安全技术,研究方向覆盖网络攻防、系统安全、Web安全、移动终端、安全开发、物联网/工控安全/AI安全等多个领域。
团队作为“省级等保关键技术实验室”先后与哈工大、齐鲁银行、聊城大学、交通学院等多个高校名企建立联合技术实验室,近三年来在网络安全技术方面开展研发项目60余项,获得各类自主知识产权30余项,省市级科技项目立项20余项,研究成果应用于产品核心技术研究、国家重点科技项目攻关、专业安全服务等。对安全感兴趣的小伙伴可以加入或关注我们。
我知道你在看哟
如有侵权请联系:admin#unsafe.sh