基本查询结构
用CodeQL编写的查询文件扩展名为.ql,并包含一个select子句。许多现有查询都包含其他可选信息,并具有以下结构:
/** * * Query metadata * */ import /* ... CodeQL libraries or modules ... */ /* ... Optional, define CodeQL classes and predicates ... */ from /* ... variable declarations ... */ where /* ... logical formula ... */ select /* ... expressions ... */
元数据属性
所有查询文件都支持以下属性:
| 属性 | 值 | 描述 |
|---|---|---|
@description |
<text> |
用一段简单的话描述查询的目的以及查询结果的重要性。该描述以纯文本编写,并使用单引号(')将代码括起来。 |
@id |
<text> |
是一串小写字母或数字,通过/或-分隔构成的单词序列,用于识别和分类查询。每个查询必须具有唯一的 ID。为确保这一点,对每个ID使用固定的结构可能会有所帮助。例如,标准LGTM查询具有以下格式:<language>/<brief-description>。 |
@kind |
|
标识查询是告警(@kind problem)还是路径(@kind path-problem)。有关这些查询类型的更多信息,请参见关于CodeQL查询。 |
@name |
<text> |
定义查询标签的语句。该名称以纯文本形式编写,并使用单引号(')将代码括起来。 |
@tags |
|
这些标签将查询按大类分组在一起,以使其更易于搜索和识别。除了此处列出的常用标签外,还有许多更具体的类别。有关更多信息,请参阅《 查询元数据样式指南》。 |
@precision |
|
表示查询结果为“真肯定”(相对于“假肯定”结果)的百分比。这与@problem.severity属性一起确定默认情况下是否在LGTM上显示结果。 |
@problem.severity |
|
定义查询生成的任何警报的严重性级别。这与@precision属性一起确定默认情况下是否在LGTM上显示结果。 |
对于过滤器查询的其他属性
过滤器查询用于定义其他约束,以限制其他查询返回的结果。筛选器查询必须具有与@kind要筛选其结果的查询相同的属性。不需要其他元数据属性。
例子
一个标准的Java查询元数据:

有关查询元数据的更多示例,请参见GitHub存储库中的标准CodeQL查询。
您可以通过修改查询的select语句来控制分析结果在源代码中的显示方式。
概述
告警查询必须在元数据中定义@kind problem属性。有关更多信息,请参见CodeQL查询的元数据。select 语句最基本的形式必须包含两“列”:
- Element ——查询所标识的代码元素。这定义了告警的位置。
- String——为该代码元素显示的消息,描述了生成告警的原因。
编写一个select语句
我们以一个使用标准CodeQL CodeDuplication.qll库识别相似文件的简单查询作为示例。
基本select语句
import java
import external.CodeDuplication
from File f, File other, int percent
where similarFiles(f, other, percent)
select f, "This file is similar to another file."
这个基本的select语句有两列:
- 显示告警的元素:
f对应于File。 - 要显示的字符串消息:
"This file is similar to another file."

包含相似文件的名称
select语句定义的告警信息是固定的,不能给用户提供太多信息。由于查询识别出了相似文件(other),因此很容易扩展select语句以告知用户这些相似文件的名称。例如:
select f, "This file is similar to " + other.getBaseName()
- Element :
和之前一样为f。 - String:"This file is similar to "—字符串文本与相似文件的文件名通过getBaseName()拼接在一起
。

尽管这比原始的select语句提供了更多信息,但用户仍然需要手动查找其他文件。
添加链接到相似文件
您可以在告警信息中使用占位符以插入其他信息,例如,指向相似文件的链接。占位符使用$@定义,并使用select语句的后两列中的信息来填充。例如,下述select语句就返回了4列信息:
select f, "This file is similar to $@.", other, other.getBaseName()
- Element:
和之前一样为f。 - 字符串消息:"This file is similar to $@."——该字符串包含一个占位符,它将显示接下来两列的合并内容。
- 占位符元素:
other对应于相似文件。 - 占位符的字符串文本:
other.getBaseName()所返回的短文件名。
显示告警消息时,$@占位符将替换为根据该select语句定义的第三第四列内容创建的链接。
如果使用$@在说明信息中多次使用占位符标记,则第N个使用的$@将由2N+2列和2N+3列组成的链接代替。如果附加列数量多于占位符标记,则末尾的列将被忽略。相反,如果附加列数量少于占位符标记,则末尾的$@标记将被视为普通文本,而不是占位符。
增加文件相似程度的一些细节
我们可以更进一步,更改select语句以报告两个文件中相似的内容部分,因为这部分信息已经在查询中可用。例如:
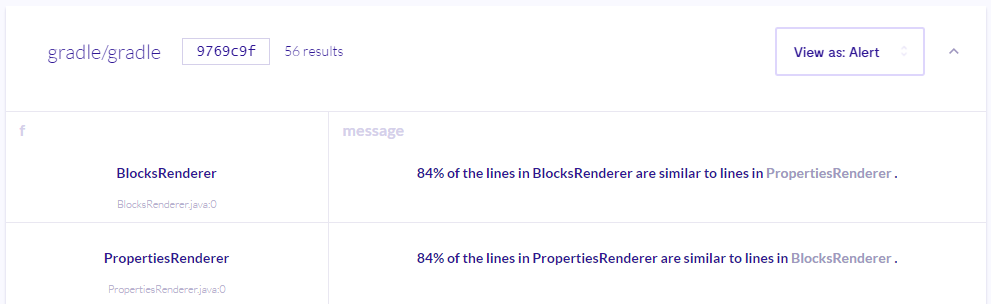
select f, percent + "% of the lines in " + f.getBaseName() + " are similar to lines in $@.", other, other.getBaseName()
由于此处添加的新元素不需要是可单击的,因此我们可以将它们直接拼接到字符串信息中。

创建一个自定义的QL包
我们编写的查询应该保存在自定义QL包文件夹或其子目录中。QL包用来整理在分析时使用的文件,包括查询、库文件、查询套件和重要的元数据。QL包目录的根目录下必须包含一个以qlpack.yml命名的文件,该文件包含name、version以及libraryPathDependencies字段属性。如果这个包还包含查询套件,可以使用suites这个字段来指定其位置。
执行命令的时候,codeql会扫描其安装目录或者子目录查找qlpack.yml文件,文件中的元数据会告知codeql如何编译查询、依赖什么库以及查询套件所在的位置。
例如一个自定义C++查询和库的QL包的qlpack.yml文件可能包含以下内容:
name: my-custom-queries version: 0.0.0 libraryPathDependencies: codeql-cpp suites: my-custom-suites
其中codeql-cpp是codeql仓库中用于C/C++分析的QL包的名称。
QL包包含的其它内容(codeql分析时使用的查询和库文件)与qlpack.yml放在同一个目录,或者它的子目录中。
例如,一个包含如下文件目录的QL包,如果需要导入CustomSinks.qll只需要在包的任意目录声明:
import mycompany.java.CustomSinks
qlpack.yml mycompany/ java/ security/ CustomSinks.qll Security/ CustomQuery.ql
我们可以通过如下方式使用自定义的查询:
codeql database analyze xssdb E:\codeql\codeql-repo\customql\java\xss.ql --format=sarif-latest --output=result.sarif
codeql database analyze xssdb E:\codeql\codeql-repo\customql\java\xss.ql --format=csv --output=codeql.csv
如有侵权请联系:admin#unsafe.sh